






01什么是urllib库
urllib库是Python内置的HTTP请求库,他可以看作处理URL的组件集合。
urllib库包含的四大模块:
- urllib.request:请求模块
- urllib.error:异常处理模块
- urllib.parse:URL解析模块
- urllib.robotparser:robots.txt解析模块
02快速使用urllib爬取网页
import urllib.request
# 调用urllib.request库的URLopen()方法,并传入一个url
response=urllib.request.urlopen('http://www.baidu.com')
# 使用read()方法读取获取到的网页内容
html=response.read().decode('UTF-8')
# 打印网页内容
print(html)上述案例就是一个简单的爬取网页的案例,爬取网页结果如下:

实际上,在浏览器打开百度首页,右击选择“查看页面源代码”命令,和刚刚打印出来的内容是一样的。
分析urlopen方法
上一小节有个核心代码:
response=urllib.request.urlopen('http://www.baidu.com')改代码调用的是urllib.request模块中的urlopen()方法,他传入了一个百度首页的URL,使用的协议是HTTP,这是urlopen方法最简单的用法。
urlopen()方法可以接受多个参数,格式为:
urllib.requset.urlopen(url,data=None,[timeout,]*,cafile=None,
capath=None,cadefault=False,context=None)
使用HTTPResponse对象
使用urllib.request模块中的URLopen()方法发送HTTP请求后,服务器返回的响应内容封装在一个HTTPResponse类型的对象中。
import urllib.request
response=urllib.request.urlopen('http://www.itcast.cn')
print(type(response))
结果为:
<class'http.client.HTTPResponse'>从输出结果来看,HTTPResponse类属于http.client模块,该类提供了获取URL,状态码,响应内容等一系列的方法。常见如下:

使用一段代码演示这些方法的使用,如下:
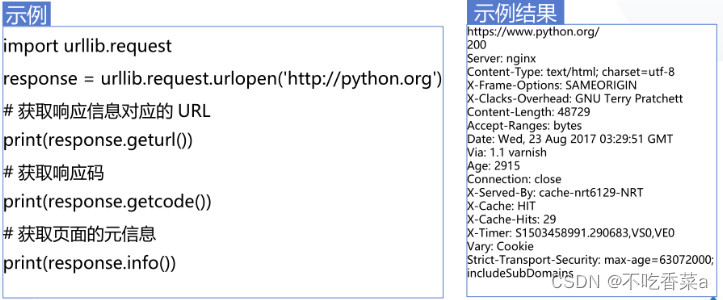
构造Request对象
如果希望对请求执行复杂操作,则需要创建一个Request对象来作为urlopen方法的参数
import urllib.request
# 将url作为Request()方法的参数,构造并返回一个Request对象
request = urllib.request.Request('http://www.baidu.com')
# 将Request对象作为urlopen方法的参数,发送给服务器并接收响应
response = urllib.request.urlopen(request)
# 使用read()方法读取获取到的网页内容
html=response.read().decode('UTF-8')
# 打印网页内容
print(html)在构建请求时,除了必须设置的url参数外,还可以加入其他内容,例如:

03使用urllib实现数据传输
url编码转换:
当传递的url包含中文或者其他特殊符号时,需要使用urllib.parse库中的urlencode方法将url进行编码。他可以将“key:value”这样的键值对转换成“key=value”这样的字符串。
import urllib.parse
data = {
'a':'传智播客',
'b':'黑马程序员'
}
result = urllib.parse.urlencode(data)
print(result)结果:

反之,解码使用的是url.parse库的unquote()方法:
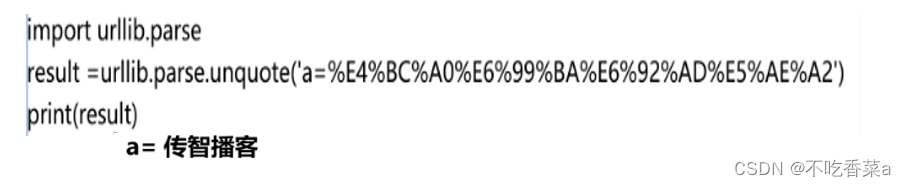
添加特定Headers--请求伪装:
对于一些需要登入的网站,如果不是从浏览器发出的请求,是不能获得响应内容的。伪装浏览器需要自定义请求报头,也就是在发送Request请求时,加入特定的Headers

04代理服务器
简单的自定义opener
opener是urllib.request.OpenerDirector类的对象,我们之前一直都在使用的urlopen,就是模块帮我们构建好的一个opener

自定义opener需要执行下列三个步骤:

设置代理服务器:
我们可以使用urllib.request中的ProxyHandler方法来设置代理服务器。

免费开放代理的获取基本没有成本,可以在一些代理网站上收集这些免费代理

05常见的网络异常
当使用urlopen()方法发送HTTP请求时,如果urlopen()不能返回的响应内容,就会产生错误。
URLError产生错误的原因主要有以下几种:
- 没有连接网络
- 服务器连接失败
- 找不到指定的服务器
可以使用try...except语句捕获相应的异常。例如:
import urllib.request
import urllib.error
request = urllib.request.Request("https://www.baidu.com")
try:
urllib.request.urlopen(request,timeout = 5)
except urllib.error.URLError as err:
print(err)运行程序后,输出结果为:
<urlopen error [Error 11001] getaddrinfo failed>实训:
requests库--以中国气象局天气预报为例:
import pprint
import requests
url = "https://aqiapp.daqi110.com/report/cityinfo?city=%E6%9F%B3%E5%B7%9E&place=1"
response = requests.get(url) # get到网址
response.encoding = "utf-8"
result_html = response.text
result_data = response.json() # 获取网址对应的json数据
pprint.pprint(result_data)
print("城市:" + result_data['city'])
print("PM2.5:" + str(result_data['pm25']))小结:
简单的介绍了什么是urllib库,让读者更加快速上手urllib案例,以及一些使用技巧,包括:urllib传输数据,添加Headers,简单自定义opener,这些都是常使用的技巧多加练习,就能熟练掌握了















 4674
4674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









