







一、介绍
图书管理与推荐系统。使用Python作为主要开发语言。前端采用HTML、CSS、BootStrap等技术搭建界面结构,后端采用Django作为逻辑处理,通过Ajax等技术实现数据交互通信。在图书推荐方面使用经典的协同过滤算法作为推荐算法模块。主要功能有:
- 角色分为普通用户和管理员
- 普通用户可注册、登录、查看图书、发布评论、收藏图书、对图书评分、借阅图书、归还图书、查看个人借阅、个人收藏、猜你喜欢(针对当前用户个性化推荐图书)
- 管理员可以管理图书以及用户信息
二、部分效果展示图片



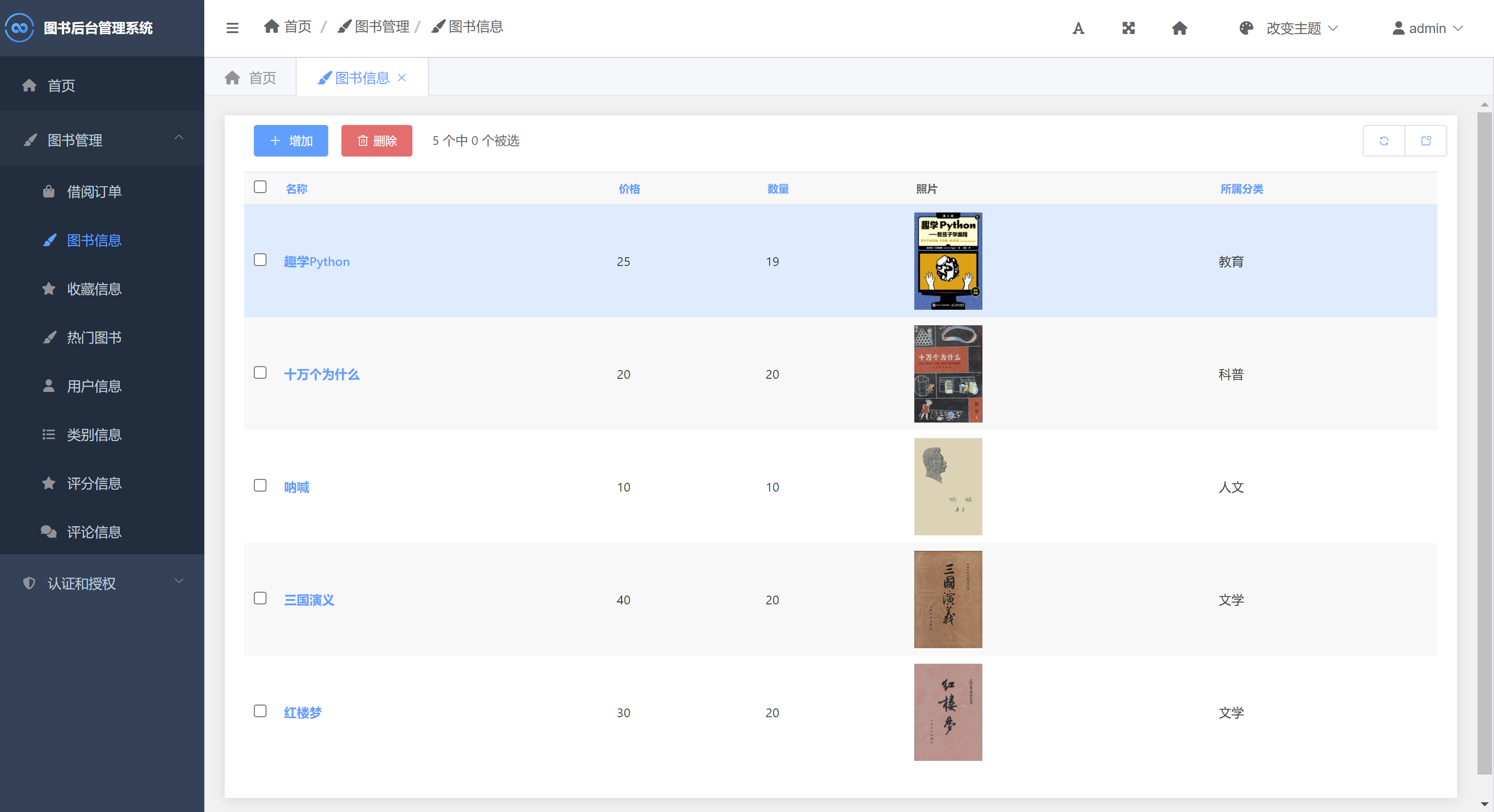
三、演示视频 and 代码 and 介绍
视频+代码+介绍:https://www.yuque.com/ziwu/yygu3z/kpq3wsbzgif4vkpi
四、协同过滤算法
基于用户的协同过滤算法(User-Based Collaborative Filtering)是一种常用于推荐系统的算法,它基于用户之间的相似度来进行推荐。其核心思想是找到与目标用户兴趣相似的其他用户,然后根据这些相似用户的行为来推荐商品或服务给目标用户。下面是该算法的主要步骤和特点:
- 计算用户相似度:
- 首先,需要定义用户之间的相似度计算方法。常用的方法有余弦相似度、皮尔逊相关系数、Jaccard系数等。
- 以余弦相似度为例,计算两个用户之间的相似度可以使用他们的评分向量的夹角的余弦值来表示。数值越接近1,说明两个用户越相似。
- 找到最相似的用户:
- 根据相似度计算结果,为每个用户找到与其最相似的K个用户(K是一个预设的参数)。
- 生成推荐列表:
- 根据目标用户的最相似用户的行为记录,来预测目标用户对未评分项的兴趣,并生成推荐列表。
- 推荐分数通常是基于最相似用户对项的评分和他们与目标用户的相似度加权得到的。
- 特点:
- 优点:直观、易于实现,对于新用户来说只要有足够的用户评分数据就能得到不错的推荐。
下面是一个基于用户的协同过滤推荐系统的简单示例。在这个示例中,我们使用Python的pandas库来处理数据,以及scikit-learn库来计算用户之间的余弦相似度。
首先,你需要安装这两个库(如果你还没有安装的话):
pip install pandas scikit-learn
然后,你可以使用下面的代码实现一个简单的基于用户的协同过滤推荐系统:
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# 构造一些示例数据
data = {
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9307
9307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









