






一.二叉树的定义即特点
1. 二叉树的特点
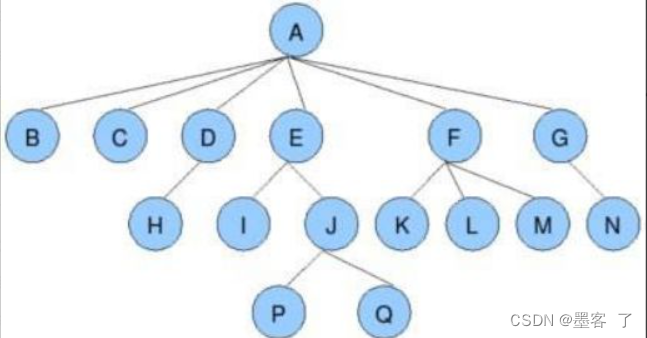
0·节点的度:一个节点含有的子树的个数称为该节点的度; 如上图:A的为6 .
1·叶节点或终端节点:度为0的节点称为叶节点;如上图:B、C、H、I…等节点为叶节点
2非终端节点或分支节点:度不为0的节点; 如上图:D、E、F、G…等节点为分支节点
3.双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点;如上图:A是B的父节点4.孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点; 如上图:B是A的孩子节点
5.兄弟节点:具有相同父节点的节点互称为兄弟节点; 如上图:B、C是兄弟节点
6.树的度:一棵树中,最大的节点的度称为树的度; 如上图:树的度为6(即B,C,D,E,F,G)。7.节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推; 树的高度或深度:树中节点的最大层次; 如上图:树的高度为4
8.堂兄弟节点:双亲在同一层的节点互为堂兄弟;如上图:H、I互为兄弟节点
9.节点的祖先:从根到该节点所经分支上的所有节点;如上图:A是所有节点的祖先
10.子孙:以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙
11.森林:由m(m>0)棵互不相交的树的集合称为森林;
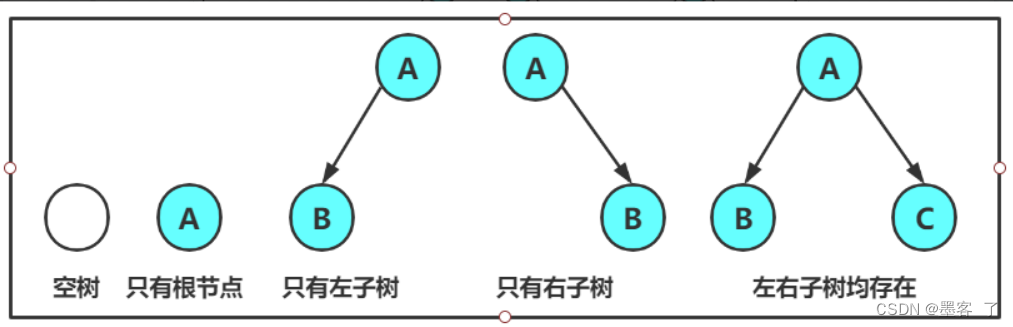
2.二叉树的分类:
3. 特殊的二叉树:
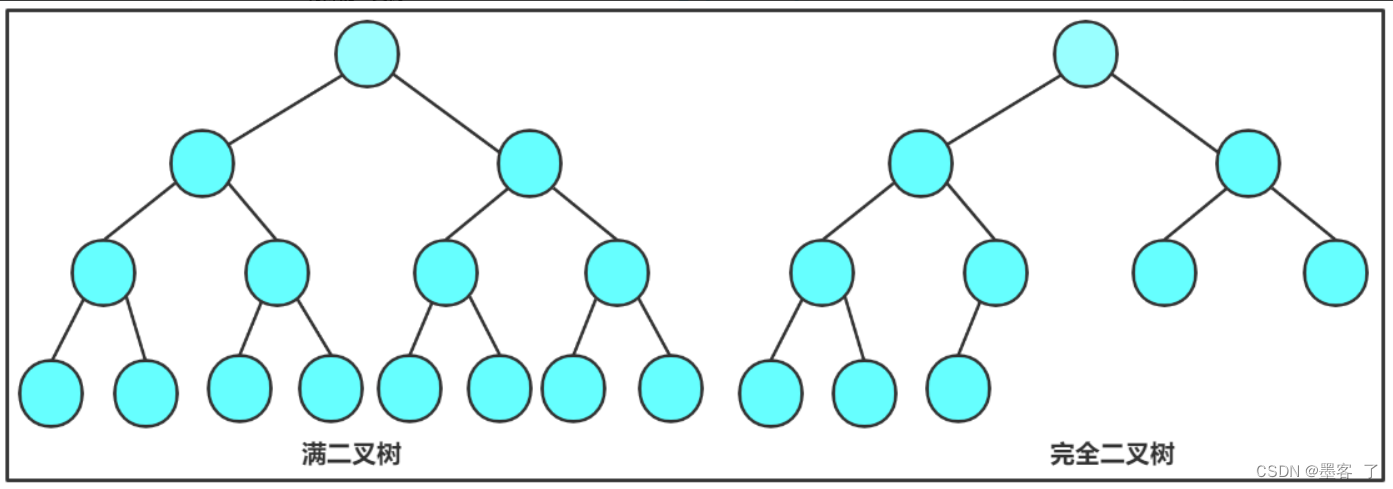
- 满二叉树:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是 说,如果一个二叉树的层数为K,且结点总数是 ,则它就是满二叉树。
- 完全二叉树:完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K 的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树。
要注意的是满二叉树是一种特殊的完全二叉树。
4 .二叉树的性质
- 若规定根节点的层数为1,则一棵非空二叉树的第i层上最多有 个结点.
- 若规定根节点的层数为1,则深度为h的二叉树的最大结点数是 .
- 对任何一棵二叉树, 如果度为0其叶结点个数为 , 度为2的分支结点个数为 ,则有 = +1
- 若规定根节点的层数为1,具有n个结点的满二叉树的深度,h= . (ps: 是log以2 为底,n+1为对数)
- 对于具有n个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有节点从0开始编号,则对 于序号为i的结点有:
. 若i>0,i位置节点的双亲序号:(i-1)/2;i=0,i为根节点编号,无双亲节点
. 若2i+1<n,左孩子序号:2i+1,2i+1>=n否则无左孩子
. 若2i+2<n,右孩子序号:2i+2,2i+2>=n否则无右孩子
题目
某二叉树共有 399 个结点,其中有 199 个度为 2 的结点,则该二叉树中的叶子结点数为( )
A 不存在这样的二叉树
B 200
C 198
D 1992.在具有 2n 个结点的完全二叉树中,叶子结点个数为( )
A n
B n+1
C n-1
D n/2
3.一个具有767个节点的完全二叉树,其叶子节点个数为()
A 383
B 384
C 385
D 386
答案:
1.B(根据规则叶子节点多度1)
2.A(代入1)
3.B(2n0=n2+1,则781/2+1=343)
5. 二叉树的存储结构
二叉树一般可以使用两种结构存储,一种顺序结构,一种链式结构。
- 顺序存储 顺序结构存储就是使用数组来存储,一般使用数组只适合表示完全二叉树,因为不是完全二叉树会有空间的浪费。而现实中使用中只有堆才会使用数组来存储,关于堆我们后面的章节会专门讲解。二叉树顺序存储在物理上是一个数组,在逻辑上是一颗二叉树。
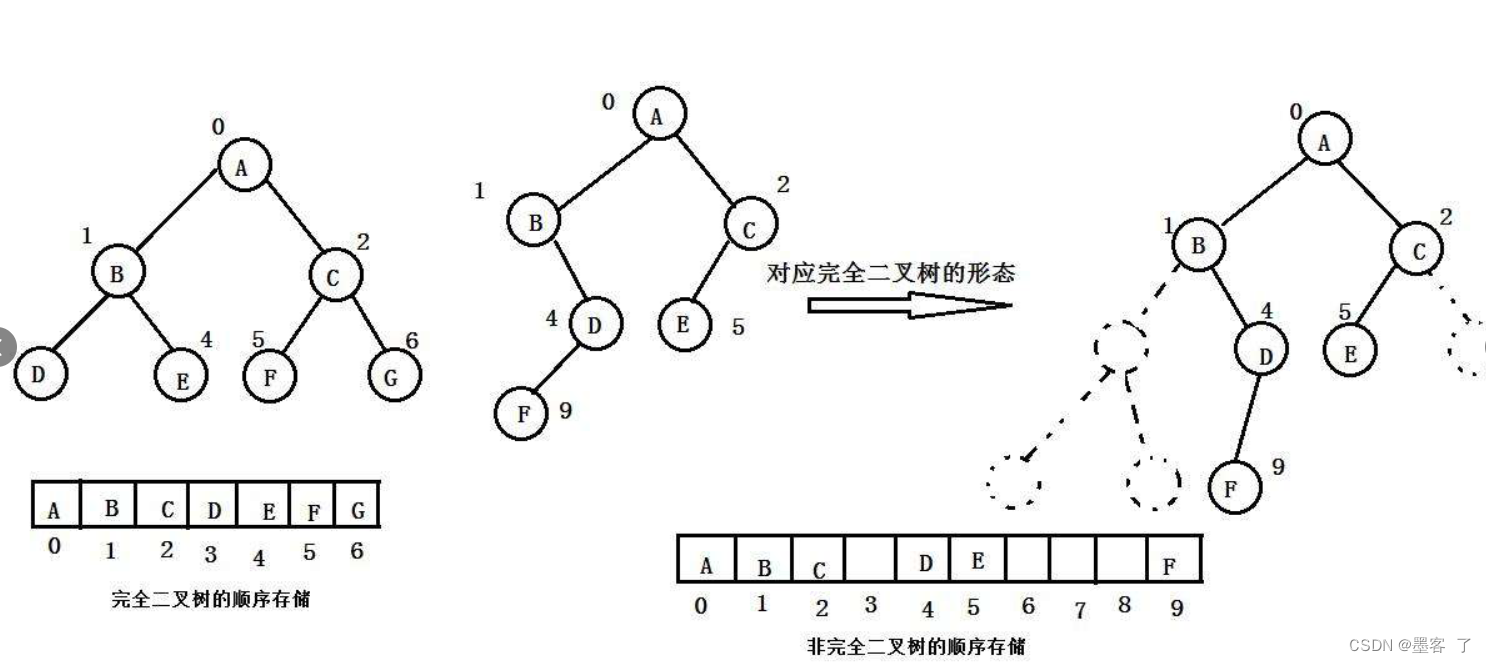
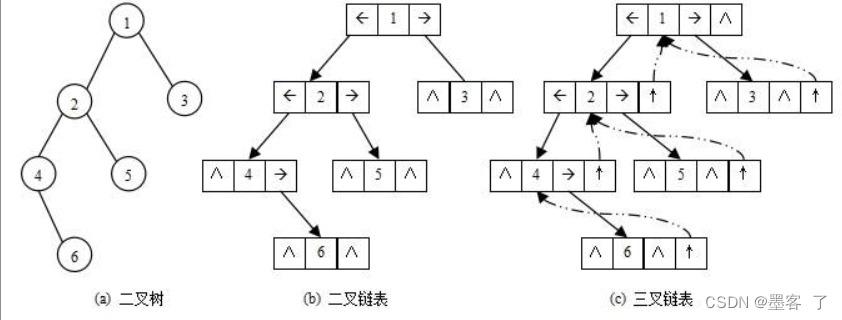
- 链式存储 二叉树的链式存储结构是指,用链表来表示一棵二叉树,即用链来指示元素的逻辑关系。 通常的方法是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所在的链结点的存储地址
。链式结构又分为二叉链和三叉链,当前我们学习中一般都是二叉链,后面课程学到高阶数据结构如红黑树等会用到三叉链。
二. 二叉树的顺序结构
1.二叉树的顺序结构
普通的二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树更适合使用顺序结构存储。现实中我们通常把堆(一种二叉树)使用顺序结构的数组来存储,需要注意的是这里的堆和操作系统虚拟进程地址空间中的堆是两回事,一个是数据结构,一个是操作系统中管理内存的一块区域分段。
2 .堆的概念及结构
如果有一个关键码的集合K = { , , ,…, },把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中,并满足: <= 且 <= ( >= 且 >= ) i = 0,1,
2…,则称为小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。堆的性质:
堆中某个节点的值总是不大于或不小于其父节点的值;
堆总是一棵完全二叉树。

3. 堆的实现
3.1全代码(此处代码是下向上排序)
注释部分为上向下排序代码。
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<time.h>
typedef int HPDataType;
void Swap(HPDataType* a, HPDataType* b) {
HPDataType t = *a;
*a = *b;
*b = t;
}
/*
void AdjustUp(HPDataType* a, int child)
{
int parent = (child - 1) / 2;
//while (parent >= 0)
while (child > 0)
{
if (a[child] <a[parent])
{
Swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
//child = (child - 1) / 2;
//parent = (parent - 1) / 2;
}
else
{
break;
}
}
} */
void AdjustDown(HPDataType* a, int size, int pos)
{
int parent = pos;
int child = parent * 2 + 1;
while (child < size)
{
if (child + 1 < size && a[child + 1] <a[child])
{
++child;
}
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
/*
void GetTop(int* a, int k, int n) {
assert(k <= n);//如果k大于n,不合法
//建立一个k个数的小根堆
int* topk = (int*)malloc(sizeof(int)*k);
//初始化这个堆内元素,维护一个小根堆
for (int i = 0; i < k; i++) {
topk[i] = a[i];//入堆
AdjustUp(topk, i);//向上调整,维护小根堆
}
for (int i = k; i < n; i++) {
if (a[i] > topk[0]) {
//topk[0]表示堆顶元素
topk[0] = a[i];//将堆顶元素换为a[i],变现的去掉了堆顶元素,
//但是此时的a[i]不一定就是堆里最小的
//再向下调整,维护小根堆
AdjustDown(topk, k, 0);
}
}
}
*/
void HeapSort(int* a, int n) {
//升序,用大根堆
//建堆,从最后一个非叶子节点开始向下调整,时间复杂度o(n)
for (int i = (n - 1 - 1) / 2; i >= 0; i--) {
AdjustDown(a, n, i);
}
int end = n - 1;//end是此时需要确定的最大的数放的位置,从下标n-1开始
while (end > 0) {
Swap(&a[0], &a[end]);//将堆顶元素放在a[end]处
AdjustDown(a, end, 0);//从[0,end)处调整
end--;//更新end
}
for (int i = 0; i < n; i++) {
printf("%d ", a[i]);
}
}
int main() {
int a[10] = { 10,9,8,7,6,5,4,3,2,1 };
HeapSort(a, 10);
return 0;
}
3.2分支简述
3.2.1堆排序
关于下代码讲解,代码从最后一个父节点开始向上排序,其中比较兄弟节点之间的最小值(取决于是大堆还是小队),将最小与父节点比较,如果小就交换,否则向上继续排序。排序完成之后,堆的关系就会出现问题,需要维护。
void AdjustDown(HPDataType* a, int size, int pos)
{
int parent = pos;
int child = parent * 2 + 1;
while (child < size)
{
if (child + 1 < size && a[child + 1] <a[child])
{
++child;
}
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
3.2.2.维护(上向下)
该部分与上部分差不多,主要目的是为了让他满足排序的目的,因为上一个只是达到相对的有序。
void AdjustUp(HPDataType* a, int child)
{
int parent = (child - 1) / 2;
//while (parent >= 0)
while (child > 0)
{
if (a[child] <a[parent])
{
Swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
//child = (child - 1) / 2;
//parent = (parent - 1) / 2;
}
else
{
break;
}
}
}
题目
1.下列关键字序列为堆的是:()
A .100,60,70,50,32,65
B .60,70,65,50,32,100
C .65,100,70,32,50,60
D. 70,65,100,32,50,60
E .32,50,100,70,65,60
F.50,100,70,65,60,322.已知小根堆为8,15,10,21,34,16,12,删除关键字 8 之后需重建堆,在此过程中,关键字之间的比较次数是()。
A 1
B 2
C 3
D 4
3.一组记录排序码为(5 11 7 2 3 17),则利用堆排序方法建立的初始堆为
A(11 5 7 2 3 17)
B(11 5 7 2 17 3)
C(17 11 7 2 3 5)
D(17 11 7 5 3 2)
E(17 7 11 3 5 2)
F(17 7 11 3 2 5)
4.最小堆[0,3,2,5,7,4,6,8],在删除堆顶元素0之后,其结果是()
A[3,2,5,7,4,6,8]
B[2,3,5,7,4,6,8]
C[2,3,4,5,7,8,6]
D[2,3,4,5,6,7,8]答案:
1.A
2.C
3.C
4.C
课后题目:
- 最小堆[0,3,2,5,7,4,6,8],第一次排序后的结果?
2.写出堆排序。
最后感谢你的观看,你的小赞是我继续更新的动力,如果你喜欢,还望多多支持,感激不尽!














 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









