






摘要
Abstract
一、文献阅读
1 论文标题
Accurate one step and multistep forecasting of very short-term PV power using LSTM-TCN model - ScienceDirect
2 论文摘要
准确的光伏功率预测正在成为将光伏电站并入电网、调度和保障电网安全的强制性任务。本文提出了一种利用LSTM-TCN预测光伏功率的新模型。它由长短期记忆和时间卷积网络模型之间的组合组成。LSTM用于从输入数据中提取时态特征,然后与TCN结合,在特征和输出之间建立连接。所提出的模型已使用包含测量光伏功率的历史时间序列的数据集进行了测试。然后,在不同季节、时段预报、多云、晴朗和间断性天气下,与LSTM和TCN模型的精度进行了比较。对于一步预测,结果表明,所提出的模型优于LSTM和TCN模型。与LSTM、TCN相比,平均绝对误差分别下降了、秋季8.47%,14.26%、冬季6.91%,15.18%、春季10.22%,14.26%和夏季14.26%,14.23%。 在多步预测方面,LSTM-TCN在2步到7步的光伏功率预测中均优于所有比较的模型。
3 过去方案
光伏发电预测主要有三种方法:物理方法、统计方法和混合方法。物理模型可以定义为具有描述系统输入和输出的数学方程的确定性模型。统计模型基于持久性的概念,通常依赖于机器学习和深度学习模型,这些模型可以从光伏发电历史数据中学习,并返回预测的光伏发电。对于混合模型,它是将前面的方法(物理模型和统计模型)相结合,以优化光伏功率预测的准确性。
在物理方法上,主要研究PV电池的等效电路。光伏发电功率预测是通过数值天气预报(numerical weather prediction,NWP)获取太阳辐照度、温度等输入参数得到的。光伏电池的物理模型需要大量的电路参数,这些参数对模型的准确性影响很大。在Comparison of different physical models for PV power output prediction - ScienceDirect中,比较了采用两种不同方法确定PV电池温度和实际天气数据的不同物理模型(基于3、4和5个参数)。结果表明,物理模型的准确性取决于用于校准该模型的数据和用于计算PV电池温度的方法。PV组件的电气数据表和估算方程可用于提取PV电池物理模型的参数。此外,还可以采用人工神经网络和进化算法等先进方法来计算这些参数。Applied Sciences | Free Full-Text | Application of Symbiotic Organisms Search Algorithm for Parameter Extraction of Solar Cell Models (mdpi.com)使用了一种名为共生生物搜索算法(Symbiotic Organisms Search algorithm)的算法,并与各种进化算法进行了比较,以识别PV模型参数。此外,还使用了一种名为Social Network Optimization的进化算法将PV模型参数与实测数据进行匹配。
几种基于机器学习的方法已被用于直接或间接地预测PV功率(预测太阳辐照度)。使用多层感知器神经网络(MLP)预测24小时的光伏发电功率,平均绝对误差(MAE)低于5%。Forecasting Power Output of Photovoltaic Systems Based on Weather Classification and Support Vector Machines | IEEE Journals & Magazine | IEEE Xplore采用支持向量机(Support Vector Machine,SVM)方法结合天气分类,结合历史PV功率时间序列,提前一天预测PV功率。结果表明,不同天气条件下光伏发电的平均相对误差(MRE)平均值为8.64%。Short-term power forecasting system for photovoltaic plants - ScienceDirect采用短期人工神经网络(ANN),利用PV输出功率的历史数据和来自数值天气预报模型(NWP)的天气预报,提前16 ~ 39小时预测PV功率。该技术已与自回归综合移动平均(ARIMA)和k -近邻(K-NN)进行了比较。结果表明,该方法优于其他方法。Day-ahead forecasting of solar photovoltaic output power using multilayer perceptron | Neural Computing and Applications (springer.com)中也使用了MLP和ANN的组合(MLP-ANN)来估计一天前的光伏功率。对于Levenberg-Marquardt等不同的学习算法,所得到的MAE在[1.92%-11.28%]范围内。Energies | Free Full-Text | Extreme Learning Machines for Solar Photovoltaic Power Predictions (mdpi.com)中已经开发了一种名为极限学习机(ELM)的算法,用于训练MLP网络提前一天进行预测。该方法在精度上优于反向传播算法。近年来,深度学习模型也被广泛应用于光伏发电功率预测。采用前馈深度神经网络(DNN)提前24小时预测光伏发电功率,MAE为2.9%。在准确性方面,最常用的深度学习模型是长短期记忆(LSTM)模型。在Deep learning neural networks for short-term photovoltaic power forecasting - ScienceDirect中,对LSTM、门控循环单元(GRU)、卷积神经网络(CNN)、CNN-LSTM、CNN-GRU、双向LSTM和双向GRU等不同深度学习模型进行了比较研究。结果表明,LSTM模型在短期光伏发电预测方面优于其他深度学习模型。此外,LSTM模型可以与几种算法相结合来优化其精度,如灰色关联分析(GRA),如Hour-ahead photovoltaic power forecast using a hybrid GRA-LSTM model based on multivariate meteorological factors and historical power datasets - IOPscience所示。时序卷积神经网络(TCN)是一种为序列建模而设计的新型卷积结构,用于光伏发电功率预测,并与LSTM、GRU、RNN和多层前馈神经网络进行了比较。TCN在准确率上优于其他模型。
如前所述,混合模型是结合两种方法(物理方法和统计方法)来提高预测精度的模型。一些文献中使用了几种混合模型。在Energies | Free Full-Text | A Physical Hybrid Artificial Neural Network for Short Term Forecasting of PV Plant Power Output (mdpi.com)中,一个名为物理混合人工神经网络(PHANN)的模型被用于预测光伏发电的提前日功率。该模型是基于双层人工神经网络(ANN)与晴空太阳辐射物理模型相结合的,并与经典的人工神经网络进行了比较。结果表明,PHANN在准确率方面优于人工神经网络。此外,PHANN在日前功率预测中优于光伏组件物理五参数等效模型。此外,Energies | Free Full-Text | Computational Intelligence Techniques Applied to the Day Ahead PV Output Power Forecast: PHANN, SNO and Mixed (mdpi.com)报道了一种混合预测方法。该方法利用PHANN组合提高天气预报精度,利用社会网络优化(social network optimization, SNO)优化模型参数。结果表明,与PHANN和SNO算法优化的光伏组件物理模型相比,混合方法提高了功率预测的准确性。
4 论文方案
LSTM-TCN模型已被应用于不同的研究领域。Text Sentiment Classification Based on LSTM-TCN Hybrid Model and Attention Mechanism | Proceedings of the 4th International Conference on Computer Science and Application Engineering (acm.org)采用结合注意机制的LSTM-TCN模型进行文本情感分类,并与有注意机制和不带注意机制的LSTM-CNN、LSTM和TCN模型进行比较。结果表明,LSTM-TCN优于LSTM、TCN,在注意机制下,AT-LSTM-TCN优于AT-LSTM-CNN等模型。此外,在LSTM-TCN: dissolved oxygen prediction in aquaculture, based on combined model of long short-term memory network and temporal convolutional network | Environmental Science and Pollution Research (springer.com)中,LSTM-TCN也用于水产养殖中溶解氧的预测。将该模型与TCN、LSTM和CNN-LSTM进行了比较。与其他方法相比,LSTM-TCN的MAE=0.236%,MAPE=3.10%,RMSE=0.342,R2=0.94,表现出较好的性能。风电功率预测也是LSTM-TCN模型应用的领域。Ultra-short term wind power prediction applying a novel model named SATCN-LSTM - ScienceDirect采用LSTM-TCN结合自关注机制进行超短期风电预测,并与不同预测模型进行精度比较。同样,提出的模型SATCN-LSTM优于LSTM、TCN和CNN-LSTM,并且略优于TCN-LSTM(无自注意机制)。与之前的工作一致,与其他深度学习模型相比,TCN和LSTM模型的结合显示出了很好的结果。尽管LSTM-TCN模型具有较高的精度和性能,但据我们所知,它还没有被用于光伏发电功率预测。本文研究了LSTM-TCN模型的单步和多步光伏功率预测。引入LSTM从光伏发电的历史时间序列中提取时间特征,然后结合TCN构建提取的时间特征与输出之间的连接。然后将所提出的模型与LSTM和TCN模型进行比较,以证明其有效性和准确性。

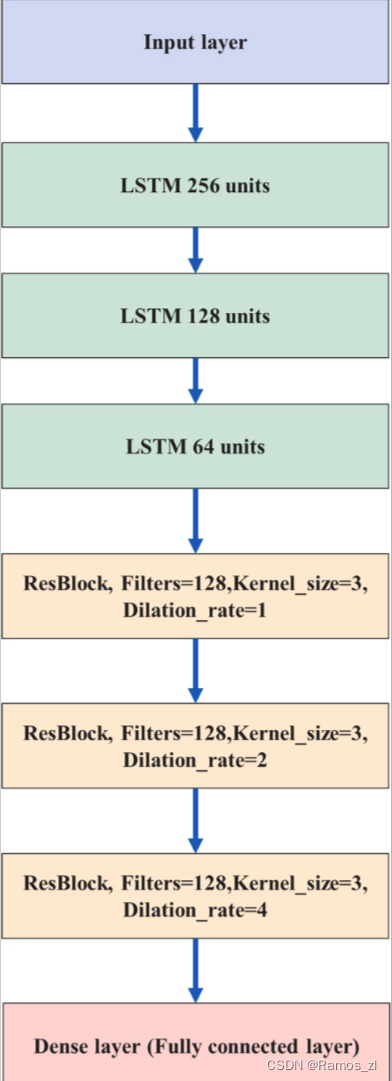
论文提出的模型结合LSTM和TCN,利用其历史和气象数据(如全球水平辐射)来预测PV功率。LSTM-TCN的流程图如下图所示。该模型由三层LSTM模型组成,用于从输入数据中提取时间特征。第一层有256个单元,第二层有128个单元,第三层有64个单元。在LSTM层中加入3个堆叠的TCN模型残差块。每个残差块具有相同数量的Filter和内核大小。残差块的膨胀系数分别为1、2和4。将TCN模型与LSTM相结合,提高了预测精度,并建立了特征与输出之间的联系。最后,使用Dense层进行维度变换。用于模型训练和验证的损失函数是均方误差(MSE),模型优化器是自适应矩估计(Adam)。值得注意的是,LSTM和TCN参数是在使用Keras调谐器函数搜索误差最小的最优参数后,测试了膨胀率、内核大小、Filter数量、LSTM单元和层数等几个值后选择的。
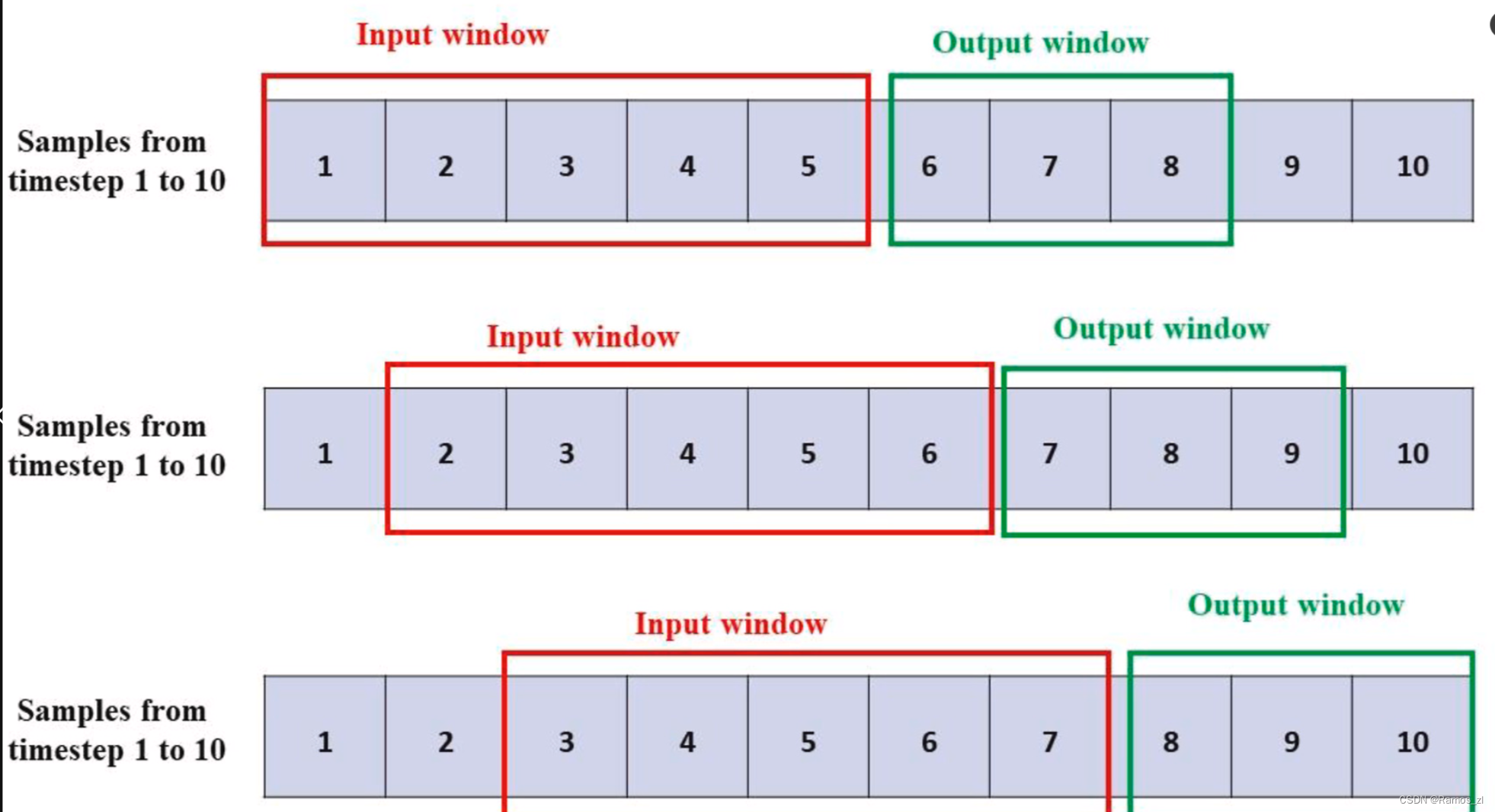
为了在时间序列预测中使用深度学习模型,必须将数据集转换为监督回归问题,其中输入特征和输出(标签)被呈现和定义。滑动窗口方法通过分割数据集来将数据集转换为监督学习问题,以获得一个序列(固定窗口大小)的观测值作为模型的输入,并获得固定数量的后续观测值作为输出,这些观测值可以是一步预测的一个后续观测值,也可以是多步预测的一系列后续观测值。通过每次滑动窗口一个时间步来对整个数据集重复分割,以获得下一个输入和输出序列。下图显示了多步时间序列预测(输入序列大小= 5,输出序列大小= 3)的滑动窗口过程。数据集分为训练数据集,用于训练所提出的深度学习模型和测试数据集,以评估模型的准确性和性能。
5 相关代码
import argparse
import time
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from matplotlib import pyplot as plt
from torch.nn.utils import weight_norm
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
from tqdm import tqdm
# 随机数种子
np.random.seed(0)
class StandardScaler():
def __init__(self):
self.mean = 0.
self.std = 1.
def fit(self, data):
self.mean = data.mean(0)
self.std = data.std(0)
def transform(self, data):
mean = torch.from_numpy(self.mean).type_as(data).to(data.device) if torch.is_tensor(data) else self.mean
std = torch.from_numpy(self.std).type_as(data).to(data.device) if torch.is_tensor(data) else self.std
return (data - mean) / std
def inverse_transform(self, data):
mean = torch.from_numpy(self.mean).type_as(data).to(data.device) if torch.is_tensor(data) else self.mean
std = torch.from_numpy(self.std).type_as(data).to(data.device) if torch.is_tensor(data) else self.std
if data.shape[-1] != mean.shape[-1]:
mean = mean[-1:]
std = std[-1:]
return (data * std) + mean
def plot_loss_data(data):
# 使用Matplotlib绘制线图
plt.figure()
plt.plot(data, marker='o')
# 添加标题
plt.title("loss results Plot")
# 显示图例
plt.legend(["Loss"])
plt.show()
class TimeSeriesDataset(Dataset):
def __init__(self, sequences):
self.sequences = sequences
def __len__(self):
return len(self.sequences)
def __getitem__(self, index):
sequence, label = self.sequences[index]
return torch.Tensor(sequence), torch.Tensor(label)
def create_inout_sequences(input_data, tw, pre_len, config):
# 创建时间序列数据专用的数据分割器
inout_seq = []
L = len(input_data)
for i in range(L - tw):
train_seq = input_data[i:i + tw]
if (i + tw + pre_len) > len(input_data):
break
if config.feature == 'MS':
train_label = input_data[:, -1:][i + tw:i + tw + pre_len]
else:
train_label = input_data[i + tw:i + tw + pre_len]
inout_seq.append((train_seq, train_label))
return inout_seq
def calculate_mae(y_true, y_pred):
# 平均绝对误差
mae = np.mean(np.abs(y_true - y_pred))
return mae
def create_dataloader(config, device):
print(">>>>>>>>>>>>>>>>>>>>>>>>>>>>创建数据加载器<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<")
df = pd.read_csv(config.data_path) # 填你自己的数据地址,自动选取你最后一列数据为特征列 # 添加你想要预测的特征列
pre_len = config.pre_len # 预测未来数据的长度
train_window = config.window_size # 观测窗口
# 将特征列移到末尾
target_data = df[[config.target]]
df = df.drop(config.target, axis=1)
df = pd.concat((df, target_data), axis=1)
cols_data = df.columns[1:]
df_data = df[cols_data]
# 这里加一些数据的预处理, 最后需要的格式是pd.series
true_data = df_data.values
# 定义标准化优化器
# 定义标准化优化器
scaler = StandardScaler()
scaler.fit(true_data)
train_data = true_data[int(0.3 * len(true_data)):]
valid_data = true_data[int(0.15 * len(true_data)):int(0.30 * len(true_data))]
test_data = true_data[:int(0.15 * len(true_data))]
print("训练集尺寸:", len(train_data), "测试集尺寸:", len(test_data), "验证集尺寸:", len(valid_data))
# 进行标准化处理
train_data_normalized = scaler.transform(train_data)
test_data_normalized = scaler.transform(test_data)
valid_data_normalized = scaler.transform(valid_data)
# 转化为深度学习模型需要的类型Tensor
train_data_normalized = torch.FloatTensor(train_data_normalized).to(device)
test_data_normalized = torch.FloatTensor(test_data_normalized).to(device)
valid_data_normalized = torch.FloatTensor(valid_data_normalized).to(device)
# 定义训练器的的输入
train_inout_seq = create_inout_sequences(train_data_normalized, train_window, pre_len, config)
test_inout_seq = create_inout_sequences(test_data_normalized, train_window, pre_len, config)
valid_inout_seq = create_inout_sequences(valid_data_normalized, train_window, pre_len, config)
# 创建数据集
train_dataset = TimeSeriesDataset(train_inout_seq)
test_dataset = TimeSeriesDataset(test_inout_seq)
valid_dataset = TimeSeriesDataset(valid_inout_seq)
# 创建 DataLoader
train_loader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, drop_last=True)
test_loader = DataLoader(test_dataset, batch_size=args.batch_size, shuffle=False, drop_last=True)
valid_loader = DataLoader(valid_dataset, batch_size=args.batch_size, shuffle=False, drop_last=True)
print("通过滑动窗口共有训练集数据:", len(train_inout_seq), "转化为批次数据:", len(train_loader))
print("通过滑动窗口共有测试集数据:", len(test_inout_seq), "转化为批次数据:", len(test_loader))
print("通过滑动窗口共有验证集数据:", len(valid_inout_seq), "转化为批次数据:", len(valid_loader))
print(">>>>>>>>>>>>>>>>>>>>>>>>>>>>创建数据加载器完成<<<<<<<<<<<<<<<<<<<<<<<<<<<")
return train_loader, test_loader, valid_loader, scaler
class Chomp1d(nn.Module):
def __init__(self, chomp_size):
super(Chomp1d, self).__init__()
self.chomp_size = chomp_size
def forward(self, x):
return x[:, :, :-self.chomp_size].contiguous()
class TemporalBlock(nn.Module):
def __init__(self, n_inputs, n_outputs, kernel_size, stride, dilation, padding, dropout=0.2):
super(TemporalBlock, self).__init__()
self.conv1 = weight_norm(nn.Conv1d(n_inputs, n_outputs, kernel_size,
stride=stride, padding=padding, dilation=dilation))
self.chomp1 = Chomp1d(padding)
self.relu1 = nn.ReLU()
self.dropout1 = nn.Dropout(dropout)
self.conv2 = weight_norm(nn.Conv1d(n_outputs, n_outputs, kernel_size,
stride=stride, padding=padding, dilation=dilation))
self.chomp2 = Chomp1d(padding)
self.relu2 = nn.ReLU()
self.dropout2 = nn.Dropout(dropout)
self.net = nn.Sequential(self.conv1, self.chomp1, self.relu1, self.dropout1,
self.conv2, self.chomp2, self.relu2, self.dropout2)
self.downsample = nn.Conv1d(n_inputs, n_outputs, 1) if n_inputs != n_outputs else None
self.relu = nn.ReLU()
self.init_weights()
def init_weights(self):
self.conv1.weight.data.normal_(0, 0.01)
self.conv2.weight.data.normal_(0, 0.01)
if self.downsample is not None:
self.downsample.weight.data.normal_(0, 0.01)
def forward(self, x):
out = self.net(x)
res = x if self.downsample is None else self.downsample(x)
return self.relu(out + res)
class TemporalConvNet(nn.Module):
def __init__(self, num_inputs, outputs, pre_len, num_channels, n_layers, kernel_size=2, dropout=0.2):
super(TemporalConvNet, self).__init__()
layers = []
self.pre_len = pre_len
self.n_layers = n_layers
self.hidden_size = num_channels[-2]
self.hidden = nn.Linear(num_channels[-1], num_channels[-2])
self.relu = nn.ReLU()
self.lstm = nn.LSTM(self.hidden_size, self.hidden_size, n_layers, bias=True,
batch_first=True) # output (batch_size, obs_len, hidden_size)
num_levels = len(num_channels)
for i in range(num_levels):
dilation_size = 2 ** i
in_channels = num_inputs if i == 0 else num_channels[i - 1]
out_channels = num_channels[i]
layers += [TemporalBlock(in_channels, out_channels, kernel_size, stride=1, dilation=dilation_size,
padding=(kernel_size - 1) * dilation_size, dropout=dropout)]
self.network = nn.Sequential(*layers)
self.linear = nn.Linear(num_channels[-2], outputs)
def forward(self, x):
x = x.permute(0, 2, 1)
x = self.network(x)
x = x.permute(0, 2, 1)
batch_size, obs_len, features_size = x.shape # (batch_size, obs_len, features_size)
xconcat = self.hidden(x) # (batch_size, obs_len, hidden_size)
H = torch.zeros(batch_size, obs_len - 1, self.hidden_size).to(device) # (batch_size, obs_len-1, hidden_size)
ht = torch.zeros(self.n_layers, batch_size, self.hidden_size).to(
device) # (num_layers, batch_size, hidden_size)
ct = ht.clone()
for t in range(obs_len):
xt = xconcat[:, t, :].view(batch_size, 1, -1) # (batch_size, 1, hidden_size)
out, (ht, ct) = self.lstm(xt, (ht, ct)) # ht size (num_layers, batch_size, hidden_size)
htt = ht[-1, :, :] # (batch_size, hidden_size)
if t != obs_len - 1:
H[:, t, :] = htt
H = self.relu(H) # (batch_size, obs_len-1, hidden_size)
x = self.linear(H)
return x[:, -self.pre_len:, :]
def train(model, args, scaler, device):
start_time = time.time() # 计算起始时间
model = model
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.005)
epochs = args.epochs
model.train() # 训练模式
results_loss = []
for i in tqdm(range(epochs)):
losss = []
for seq, labels in train_loader:
optimizer.zero_grad()
y_pred = model(seq)
single_loss = loss_function(y_pred, labels)
single_loss.backward()
optimizer.step()
losss.append(single_loss.detach().cpu().numpy())
tqdm.write(f"\t Epoch {i + 1} / {epochs}, Loss: {sum(losss) / len(losss)}")
results_loss.append(sum(losss) / len(losss))
torch.save(model.state_dict(), 'save_model.pth')
time.sleep(0.1)
# valid_loss = valid(model, args, scaler, valid_loader)
# 尚未引入学习率计划后期补上
# 保存模型
print(f">>>>>>>>>>>>>>>>>>>>>>模型已保存,用时:{(time.time() - start_time) / 60:.4f} min<<<<<<<<<<<<<<<<<<")
plot_loss_data(results_loss)
def valid(model, args, scaler, valid_loader):
lstm_model = model
# 加载模型进行预测
lstm_model.load_state_dict(torch.load('save_model.pth'))
lstm_model.eval() # 评估模式
losss = []
for seq, labels in valid_loader:
pred = lstm_model(seq)
mae = calculate_mae(pred.detach().numpy().cpu(), np.array(labels.detach().cpu())) # MAE误差计算绝对值(预测值 - 真实值)
losss.append(mae)
print("验证集误差MAE:", losss)
return sum(losss) / len(losss)
def test(model, args, test_loader, scaler):
# 加载模型进行预测
losss = []
model = model
model.load_state_dict(torch.load('save_model.pth'))
model.eval() # 评估模式
results = []
labels = []
for seq, label in test_loader:
pred = model(seq)
mae = calculate_mae(pred.detach().cpu().numpy(),
np.array(label.detach().cpu())) # MAE误差计算绝对值(预测值 - 真实值)
losss.append(mae)
pred = pred[:, 0, :]
label = label[:, 0, :]
pred = scaler.inverse_transform(pred.detach().cpu().numpy())
label = scaler.inverse_transform(label.detach().cpu().numpy())
for i in range(len(pred)):
results.append(pred[i][-1])
labels.append(label[i][-1])
print("测试集误差MAE:", losss)
# 绘制历史数据
plt.plot(labels, label='TrueValue')
# 绘制预测数据
# 注意这里预测数据的起始x坐标是历史数据的最后一个点的x坐标
plt.plot(results, label='Prediction')
# 添加标题和图例
plt.title("test state")
plt.legend()
plt.show()
# 检验模型拟合情况
def inspect_model_fit(model, args, train_loader, scaler):
model = model
model.load_state_dict(torch.load('save_model.pth'))
model.eval() # 评估模式
results = []
labels = []
for seq, label in train_loader:
pred = model(seq)[:, 0, :]
label = label[:, 0, :]
pred = scaler.inverse_transform(pred.detach().cpu().numpy())
label = scaler.inverse_transform(label.detach().cpu().numpy())
for i in range(len(pred)):
results.append(pred[i][-1])
labels.append(label[i][-1])
# 绘制历史数据
plt.plot(labels, label='History')
# 绘制预测数据
# 注意这里预测数据的起始x坐标是历史数据的最后一个点的x坐标
plt.plot(results, label='Prediction')
# 添加标题和图例
plt.title("inspect model fit state")
plt.legend()
plt.show()
def predict(model, args, device, scaler):
# 预测未知数据的功能
df = pd.read_csv(args.data_path)
df = df.iloc[:, 1:][-args.window_size:].values # 转换为nadarry
pre_data = scaler.transform(df)
tensor_pred = torch.FloatTensor(pre_data).to(device)
tensor_pred = tensor_pred.unsqueeze(0) # 单次预测 , 滚动预测功能暂未开发后期补上
model = model
model.load_state_dict(torch.load('save_model.pth'))
model.eval() # 评估模式
pred = model(tensor_pred)[0]
pred = scaler.inverse_transform(pred.detach().cpu().numpy())
# 假设 df 和 pred 是你的历史和预测数据
# 计算历史数据的长度
history_length = len(df[:, -1])
# 为历史数据生成x轴坐标
history_x = range(history_length)
# 为预测数据生成x轴坐标
# 开始于历史数据的最后一个点的x坐标
prediction_x = range(history_length - 1, history_length + len(pred[:, -1]) - 1)
# 绘制历史数据
plt.plot(history_x, df[:, -1], label='History')
# 绘制预测数据
# 注意这里预测数据的起始x坐标是历史数据的最后一个点的x坐标
plt.plot(prediction_x, pred[:, -1], marker='o', label='Prediction')
plt.axvline(history_length - 1, color='red') # 在图像的x位置处画一条红色竖线
# 添加标题和图例
plt.title("History and Prediction")
plt.legend()
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Time Series forecast')
parser.add_argument('-model', type=str, default='TCN-LSTM', help="模型持续更新")
parser.add_argument('-window_size', type=int, default=126, help="时间窗口大小, window_size > pre_len")
parser.add_argument('-pre_len', type=int, default=24, help="预测未来数据长度")
# data
parser.add_argument('-shuffle', action='store_true', default=True, help="是否打乱数据加载器中的数据顺序")
parser.add_argument('-data_path', type=str, default='ETTh1-Test.csv', help="你的数据数据地址")
parser.add_argument('-target', type=str, default='OT', help='你需要预测的特征列,这个值会最后保存在csv文件里')
parser.add_argument('-input_size', type=int, default=7, help='你的特征个数不算时间那一列')
parser.add_argument('-feature', type=str, default='MS', help='[M, S, MS],多元预测多元,单元预测单元,多元预测单元')
parser.add_argument('-model_dim', type=list, default=[64, 128, 256], help='这个地方是这个TCN卷积的关键部分,它代表了TCN的层数我这里输'
'入list中包含三个元素那么我的TCN就是三层,这个根据你的数据复杂度来设置'
'层数越多对应数据越复杂但是不要超过5层')
# learning
parser.add_argument('-lr', type=float, default=0.001, help="学习率")
parser.add_argument('-drop_out', type=float, default=0.05, help="随机丢弃概率,防止过拟合")
parser.add_argument('-epochs', type=int, default=20, help="训练轮次")
parser.add_argument('-batch_size', type=int, default=16, help="批次大小")
parser.add_argument('-save_path', type=str, default='models')
# model
parser.add_argument('-hidden_size', type=int, default=64, help="隐藏层单元数")
parser.add_argument('-kernel_sizes', type=int, default=3)
parser.add_argument('-laryer_num', type=int, default=1)
# device
parser.add_argument('-use_gpu', type=bool, default=True)
parser.add_argument('-device', type=int, default=0, help="只设置最多支持单个gpu训练")
# option
parser.add_argument('-train', type=bool, default=True)
parser.add_argument('-test', type=bool, default=True)
parser.add_argument('-predict', type=bool, default=True)
parser.add_argument('-inspect_fit', type=bool, default=True)
parser.add_argument('-lr-scheduler', type=bool, default=True)
args = parser.parse_args()
if isinstance(args.device, int) and args.use_gpu:
device = torch.device("cuda:" + f'{args.device}')
else:
device = torch.device("cpu")
print("使用设备:", device)
train_loader, test_loader, valid_loader, scaler = create_dataloader(args, device)
if args.feature == 'MS' or args.feature == 'S':
args.output_size = 1
else:
args.output_size = args.input_size
# 实例化模型
try:
print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始初始化{args.model}模型<<<<<<<<<<<<<<<<<<<<<<<<<<<")
model = TemporalConvNet(args.input_size, args.output_size, args.pre_len, args.model_dim, args.laryer_num,
args.kernel_sizes).to(device)
print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始初始化{args.model}模型成功<<<<<<<<<<<<<<<<<<<<<<<<<<<")
except:
print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始初始化{args.model}模型失败<<<<<<<<<<<<<<<<<<<<<<<<<<<")
# 训练模型
if args.train:
print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始{args.model}模型训练<<<<<<<<<<<<<<<<<<<<<<<<<<<")
train(model, args, scaler, device)
if args.test:
print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始{args.model}模型测试<<<<<<<<<<<<<<<<<<<<<<<<<<<")
test(model, args, test_loader, scaler)
if args.inspect_fit:
print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始检验{args.model}模型拟合情况<<<<<<<<<<<<<<<<<<<<<<<<<<<")
inspect_model_fit(model, args, train_loader, scaler)
if args.predict:
print(f">>>>>>>>>>>>>>>>>>>>>>>>>预测未来{args.pre_len}条数据<<<<<<<<<<<<<<<<<<<<<<<<<<<")
predict(model, args, device, scaler)
plt.show()
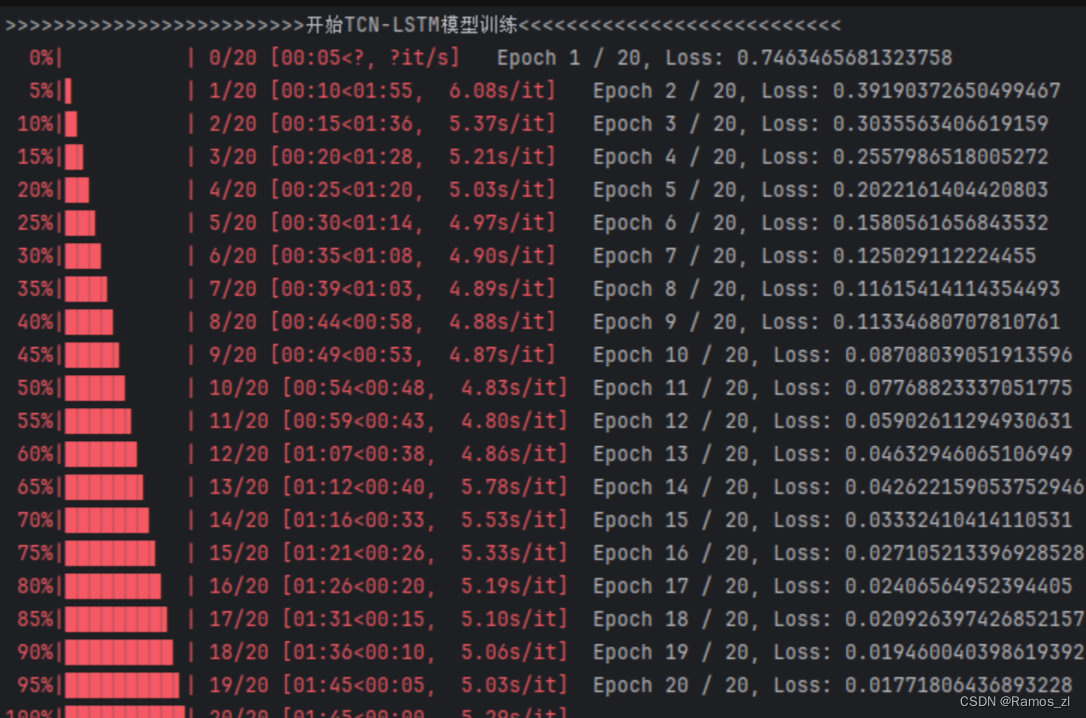
运行结果:















 1017
1017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









