







题目名称:多模态大模型时代的具身智能研究进展的调研与讨论... 1
2.8 2025年项目 Human - Agent Joint Learning for Efficient Robot Manipulation Skill Acquisition. 22
第1章 引言
1.1 研究背景
近年来,人工智能领域经历了爆发式增长,多模态大模型的发展尤其引人注目。自 GPT-4 至 PaLM-E 等先进语言模型的迭代演进,其在融合文本、图像、音频等异构数据处理上的优异表现有目共睹。这些创新成果不仅深度革新了自然语言处理技术范式,更在计算机视觉领域引发连锁反应,有力驱动了多学科交叉领域的跨越式发展。与此同时,具身智能(Embodied AI)[1],作为一个新兴且快速发展的领域,正逐渐成为人工智能研究的焦点。具身智能旨在赋予智能体(如机器人)在真实物理环境中感知、决策和行动的能力,通过身体与环境的交互来实现智能行为,这一概念深刻改变了传统人工智能仅在虚拟环境中进行抽象计算的模式。
具身智能的发展历程中,2024 年无疑是具有里程碑意义的一年。这一年,具身智能入选 “新一代信息工程科技新质生产力技术备选清单”,具身小脑模型被列入 “世界人工智能十大前沿技术趋势”,凸显了其在未来科技发展中的重要地位。波士顿动力的 Atlas 机器人以其出色的运动控制能力,展示了机器人在复杂地形中的灵活移动和操作潜力;OpenAI 的 Dactyl 机械臂通过触觉反馈成功复原魔方,体现了具身智能在精细操作任务上的突破。这些标志性成果不仅展示了具身智能的技术可行性,也预示了其在未来生产生活中的广泛应用前景[2]。
多模态大型智能模型与实体化智能体系的深度交融,催生出极具创新性的研究路径。过往的实体化智能系统在环境感知及策略制定环节存在固有短板,面对动态复杂的外部信息时,往往难以高效处理。而多模态大型模型凭借其强大的数据整合能力,将视觉信号、语义内容、触觉反馈等多维度信息有机结合,为实体化智能载体构建起更为立体、详实的环境认知体系。例如,Google DeepMind 的 RT 系列视觉 - 语言 - 动作模型,通过端到端训练,将机器人的环境理解维度从传统 3D 点云扩展到包含语义信息的 4D 时空模型,显著提升了机器人在未知环境中的抓取成功率和推理速度[3]。该技术融合带来的增益,不仅显著拓宽了实体化智能载体的感知边界,更赋予其解析复杂任务指令、精准执行操作的进阶能力。从本质上重塑了实体化智能系统的运作逻辑,有效强化了其在不同场景下的适配性与任务处理效能,大幅提升系统整体性能与泛化应用潜力。
于实际应用场景中,实体化智能技术已在诸多行业彰显出广阔的发展前景。以工业制造场景为例,搭载实体化智能的机器人凭借强大的环境适应能力,能够灵活应对多样化的生产环境,通过智能化的柔性制造模式,高效提升生产效率与产品品质。例如,在宝马工厂中,Figure AI 人形机器人通过高精度的触觉反馈系统,将线束装配的插接成功率提升至 99.2%,单台设备可替代 3 名熟练工人,推动产线自动化率突破 85%。在服务领域,具身智能的应用也在加速探索。在西安交通大学具身智能机器人研究院的科研实践里,优必选 Walker 系列机器人借助触觉反馈强化学习技术,成功实现在复杂人体接触场景下 0.01N 级别的精准力度调控。这一突破极大拓展了人机交互的技术边界,在医疗护理、养老照护等需要细腻人机互动的领域,展现出巨大的应用价值。与此同时,具身智能技术还逐步渗透至教育、娱乐、安防等多个行业领域,为各行业创新发展注入全新活力,带来前所未有的变革契机 。
尽管具身智能取得了显著进展,但目前仍面临诸多挑战。在技术层面,缺乏能够支持最底层控制的一步到位的基础大模型,计算能力的局限也制约了具身智能系统在复杂环境中的实时决策能力。现阶段,多模态感知信息的整合难题仍未彻底攻克,各类传感器采集数据在融合过程中的精确性与处理效率均存在优化空间。与此同时,数据采集环节中的安全与隐私风险已成为不可回避的现实问题。如何构建既能够充分保障数据安全,又可实现海量优质数据高效获取的技术体系,已然成为制约具身智能进一步发展的关键瓶颈。在伦理和社会层面,随着具身智能体在社会生活中的广泛应用,如何制定合理的伦理规范和法律框架,确保其安全、可靠、符合人类价值观地运行,成为亟待解决的问题。
1.2 具身领域的发展历程
1.2.1 具身的定义
具身智能(Embodied AI),是指智能体通过与环境进行交互,利用感知、决策和行动来完成任务的能力[4]。该理念着重指出,智能的实现并非单纯依赖于理论化的算法推演与数据运算,更需要借助实体物理载体,通过与外部环境的动态交互,才能催生出更贴近现实、更具实践价值的智能行为模式。
这一概念突破了传统人工智能单纯依赖算法和数据的局限,将智能与物理实体的行动和环境感知紧密结合。
1.2.2 发展历程
实体化智能的演进轨迹最早可回溯至 20 世纪中期,其发展脉络与计算机科学、人工智能的迭代进程深度交织、相互促进。其发展主要分为以下几个阶段:
理论奠基期(20 世纪 50 年代 - 90 年代):1950 年,艾伦・图灵于《计算机器与智能》中开创性地提出 “具身智能” 理念,为后续研究构筑起理论框架。1986 年,罗德尼・布鲁克斯从控制论视角出发,批判以表征为核心的传统人工智能发展路径,倡导通过构建基于行为的机器人消除过度表征。1991 年,布鲁克斯进一步探究智能本源,指出智能行为可源自自主机器与外界环境的基础物理交互。1999 年,罗尔夫・普费弗等人强调,智能并非局限于算法或大脑运算,身体在智能形成过程中起着关键作用,这些理论为具身智能发展注入思想源泉。
技术融合期(20 世纪 90 年代 - 2022 年):伴随智能理论体系的健全与底层数学研究的深化,符号主义、连接主义、行为主义三大人工智能学派从独立探索转向交叉融合,相互汲取理论优势。在此期间,机器学习、计算机视觉、自然语言处理等前沿技术持续突破,为具身智能发展夯实理论根基、完善算法体系。科研工作者积极将这些技术应用于机器人研发,促使机器人在环境感知、决策规划及行动执行等方面的能力逐步提升。
快速发展阶段(2006 - 2020):2006 年,杰弗里・辛顿等人提出深度学习的概念,通过构建深层神经网络,利用其多层结构自动学习数据的层次化特征表示,大大提高了模型的性能和泛化能力,开启了深度学习的新时代。随着深度学习技术的迅猛革新,具身智能研究迎来全新发展阶段。科研人员借助虚拟仿真环境与高性能计算资源,对智能系统开展设计与训练优化工作。这一创新模式有效强化了机器人在复杂场景下的感知敏锐度、决策精准性与行动执行力,实现了系统性能的跨越式提升。
技术突破阶段(2022 年至今):以 ChatGPT 为代表的大模型展现出强大的通用知识和智能涌现能力,为机器人实现智能感知、自主决策乃至拟人化交互带来巨大潜力。大型智能模型凭借其卓越的数据处理和解析能力,可对庞大数据集合进行高效分析,这为实体化智能系统赋予了更为强劲的认知性能,显著提升其对复杂信息的理解与处理水平 。2023 年,英伟达创始人黄仁勋提出具身智能是人工智能的下一个浪潮,进一步推动了该领域的发展。2024 年,具身智能入选 “新一代信息工程科技新质生产力技术备选清单”。2025 年,具身智能被写入政府工作报告,国内已有超过 20 个城市将发展具身智能作为重要战略方向,这一系列事件标志着具身智能进入了快速发展和广泛应用的新阶段。本文着重写2024-至今发展以及重大项目内容[5]。
1.2.3 不同形态的机器人
人形机器人是具身智能最具代表性的应用形态之一,其发展历程反映了具身智能技术的不断进步。
雏形探索时期(20 世纪 60 年代末至 90 年代):该阶段人形机器人研发聚焦于攻克双足移动的基础技术难题。日本早稻田大学作为先驱力量,成功推出 WAP、WL、WABIAN、WABOT 等系列机器人产品。这些初代人形机械载体虽已具备仿人类身体构造的框架,能够完成双足行走动作并实现基础运动控制,但受限于当时技术条件,其肢体灵活性欠佳,智能交互与自主决策能力也较为薄弱。
技术整合跃升期(21 世纪初 - 2010 年):本田公司研发的 ASIMO 系列人形机器人,成为该阶段的标志性成果。ASIMO 通过融合感知技术与智能控制系统,构建起基础感知体系,能够捕捉周边环境信息,并依据感知结果进行简易决策与动作调整。以 2000 年推出的 ASIMO 为例,其不仅拥有拟人化外观,还具备预判动作、动态调节重心的能力,在转弯行进时展现出流畅性,这一突破极大推动了人形机器人在感知与智能操控领域的发展。
高性能拓展期(2010 年 - 2022 年):伴随控制理论的革新与技术迭代,人形机器人的认知水平与运动性能实现质的飞跃。本田对 ASIMO 进行升级,采用电驱技术方案,结合视觉与触觉物体识别技术,使机器人能够精准执行抓取物品、倾倒液体等精细操作;波士顿动力打造的 ATLAS 机器人则以液压驱动为技术路径,在复杂艰险场景中,如奔跑、跳跃等高动态运动下仍能保持稳定平衡,充分彰显了人形机器人在复杂环境中的卓越适应力。
智能深化转型期(2022 年 - 至今):得益于人工智能,尤其是大模型技术的蓬勃发展,人形机器人在感知、交互与决策层面迈向智能化新高度。以特斯拉 Optimus 机器人为例,依托人工智能算法与自主研发的 FSD 芯片,借助端到端神经网络模型,实现任务规划与动作执行的智能决策,同时高效完成复杂环境中物体、人脸及手势的精准识别。此外,Optimus 通过全身压力监测与实时反馈机制,大幅提升肢体运动灵敏度,实现自然流畅的动作表现,为推动人形机器人智能化发展注入强劲动力。
2) 机械臂
机械臂凭借其多功能性与灵活性,已深度融入工业制造、物流自动化以及医疗微创等众多领域。与此同时,围绕机械臂展开的具身智能技术探索,也在长期实践中逐步演进,历经多个关键发展阶段,持续实现技术突破与功能迭代 。
初期自动化探索阶段:在机械臂发展的早期,其研发重点聚焦于执行重复性基础作业。于工业制造场景中,这类机械臂常被部署在生产线,承担物料转运、部件焊接等常规任务,通过预设程序实现动作循环,以提升生产效率。它们通常通过预设的程序进行操作,缺乏对环境的感知和自主决策能力,只能在相对固定和结构化的环境中运行。
感知增强阶段:随着传感器技术的发展,机械臂开始配备各种传感器,如视觉传感器、力传感器等,使其能够感知周围环境的信息。借助视觉传感装置,机械臂得以精准捕捉物体的空间坐标、轮廓特征及摆放角度,进而在抓取与操作流程中实现更高精度的动作执行,显著提升任务完成质量。力传感器则使机械臂能够感知接触力的大小,在进行精密装配等任务时避免对物体造成损坏,提高了操作的精度和可靠性。
智能决策与控制阶段:近年来,随着人工智能技术的应用,机械臂开始具备一定的智能决策能力。通过机器学习算法,机械臂可以从大量的操作数据中学习,优化操作策略,提高工作效率。以物流仓储场景为例,机械臂能够依据货物的承重参数、外形规格以及堆叠方位等多维信息,通过内置算法智能规划最优抓取路线,并自动匹配相适应的操作模式,实现高效、精准的货物处理 。同时,结合先进的控制算法,机械臂能够实现更精确的运动控制,适应更加复杂多变的任务需求。一些机械臂还可以与其他设备和系统进行协同工作,形成智能化的生产或服务流程。
3) 其他形态机器人
除了人形机器人和机械臂,还有多种形态的机器人在具身智能领域发挥着重要作用。
四足机器人凭借其卓越的地形适应性能,可在复杂多变的野外环境中自如地完成行走、疾跑乃至攀爬等高难度动作。以波士顿动力研发的 Spot 机器人为例,它能在凹凸不平的地形表面保持稳定行进,高效执行设备巡检、灾害搜救等重要任务。此类机器人往往搭载先进的运动控制算法,通过整合惯性测量单元(IMU)与视觉传感装置等多类型传感器,实时精准感知自身姿态变化与周边环境信息,并依据环境动态智能调整运动策略,确保行动过程中的身体平衡。尤其在高风险区域或人类难以涉足的恶劣环境中,四足机器人能够充分发挥其独特功能优势,为人类活动提供有力支持 。轮式机器人:轮式机器人具有移动速度快、能耗低的特点,常见于物流配送、清洁服务等领域。在物流仓库中,轮式机器人可以快速地搬运货物,根据预设的路径和任务规划,高效地完成货物的分拣和运输工作。部分轮式机器人集成了视觉导航模块与智能避障系统,借助先进的感知技术,可在复杂多变的动态场景中实现自主路径规划。在行进过程中,它们能够敏锐识别障碍物,并迅速做出规避反应,同时还能与周边设备、人员保持安全交互,高效完成协同作业。
仿生机器人:仿生机器人模仿生物的形态和行为,具有独特的优势。以仿生鱼机器人为例,其模仿鱼类的运动方式,能够在水体环境中自由穿梭、灵活转向,常用于执行水下地形勘探、生态环境监测等任务,在水下作业领域发挥着重要作用。仿生昆虫机器人可以在狭小空间或复杂环境中执行任务,如搜索救援、环境监测等。仿生机器人通过模拟生物的身体结构和运动方式,能够更好地适应特定的环境,同时借鉴生物的感知和行为模式,为具身智能的发展提供了新的思路和方法[6]。
1.3 研究目的及意义
本文旨在对多模态大模型时代的具身智能研究进展进行全面梳理和深入分析。我们将首先回顾具身智能的发展历程,分析多模态大模型为具身智能带来的技术变革,包括感知、决策和执行层面的突破。接着,详细探讨具身智能在不同领域的应用现状,通过具体案例分析其应用效果和面临的挑战。基于前文论述,深度挖掘具身智能在技术攻坚、伦理规范、社会适应等维度遭遇的多重困境,并对其后续演进方向展开前瞻性探讨。本文的研究旨在探讨与回顾智身领域的前沿发展状况。
第2章 具身智能核心研究方向与技术框架
2.1 模仿学习与强化学习在机器人领域的成果
模仿学习和强化学习作为传统机器人学习的两大核心技术,在具身智能系统中发挥着至关重要的作用。两者在学习模式上的差异性与互补性,为机器人在无需预先建立精确模型的情况下,实现环境感知、决策规划与控制执行提供了理论支撑和实践路径
2.1.1 模仿学习概述
模仿学习指的是通过对专家操作或人类行为示例的观察,直接获取并重现复杂任务执行过程中的行为特征与动作范式。这种方法能显著提高机器人学习初期的效率,能够捕捉细粒度的协调与接触动力学信息,但其性能强烈依赖于示范数据的数量和质量。以大型物件操控场景为例,RobotMover 架构运用 “动态链” 建模方式,解析人类双臂操作演示,精准提炼核心运动要素。凭借这一技术,成功达成无需预训练即可向实体机器人迁移的创新成果,有效规避了传统方法中耗时耗力的反复调试过程。。提升了训练效率和操作鲁棒性[7]。
2.1.2 强化学习概述
强化学习[8]通过环境—动作—奖励的闭环反馈机制,使机器人能够自我探索最优策略。在机器人运动控制范畴内,强化学习技术在足式机器人、仿生机器人等对复杂运动有高要求的系统中得到大量实践应用。就像小米工程师刘天林深入研究足式机器人的仿真到现实转换难题,提出能够实现仿真环境与真实场景间平稳衔接的核心技术手段,有效化解实际应用时模型迁移存在的障碍。而且,深度强化学习已在机器人操控、游戏人工智能等众多机器人任务场景中成功落地,彰显出出色的性能表现与广泛的适用能力。
2.1.3 模仿学习与强化学习的优缺
从技术上看,模仿学习能够在专家示范的基础上迅速建立基本技能,但其局限在于仅能复制已有水平,难以进一步突破人类演示的极限;而强化学习则有潜力超越人类,但对奖励函数的设计、策略探索及收敛性要求较高,训练过程往往耗时、数据需求巨大。目前,科研方向聚焦于整合两种学习方法的优势,采用以模仿学习为前置预训练环节,再接入强化学习进行策略精调的复合模式。这种融合方案旨在弥补二者的先天短板,推动智能系统在虚拟仿真环境与现实物理场景间实现高效迁移,减少理论与实践间的应用鸿沟 。例如,伦敦帝国理工学院的研究人员便采用元学习方法,使机器人仅通过单次人类示范便可执行新任务,大大降低了数据收集的成本和复杂性[9]。如表2-1是模仿学习/强化学习在机器人应用上的里程表。
| 年份 | 模仿学习(IL) | 强化学习(RL) | 意义 |
| 1997 | 逆向强化学习(IRL)提出(Ng & Russell) | — | 从人类演示反推奖励函数,奠定IL与RL结合的基础。 |
| 1999 | ALVINN自动驾驶(CMU) | — | 行为克隆(BC)首次在自动驾驶中应用。 |
| 2006 | DAgger算法(Ross et al.) | — | 解决IL的分布偏移问题,提升泛化能力。 |
| 2008 | 直升机特技飞行(IRL+RL)(Abbeel & Ng) | — | IRL与RL结合,实现复杂控制任务(登《Science》)。 |
| 2013 | 端到端视觉模仿(LeCun等) | DeepMind DQN(Atari游戏) | IL:CNN处理视觉输入; |
| 2015 | GAIL算法(对抗模仿学习) | TRPO/PPO算法(OpenAI) | IL:生成对抗模仿; |
| 2016 | OpenAI机械手旋转方块(IL+RL) | AlphaGo(DeepMind) | IL+RL结合解决灵巧操作; |
| 2017 | — | 机器人自学习(OpenAI, Dactyl) | RL纯自主学习机械手操控,无需人类演示。 |
| 2018 | Meta-IL(少量演示适应) | Soft Actor-Critic(SAC) | IL:元学习提升数据效率; |
| 2019 | BRETT多模态模仿(UC Berkeley) | 四足机器人行走(RL, ETH Zurich) | IL:视觉+触觉模仿; |
| 2021 | R3M视频表征学习(Facebook) | 机器人抓取(OpenAI, Code as Policies) | IL:从视频学习通用特征; |
| 2022 | RT-1多任务策略(Google) | 机器人敏捷操作(DeepMind, RGB-Stacking) | IL:大规模多任务泛化; |
| 2023 | 具身智能(PaLM-E, RoboCat) | 人形机器人控制(Optimus, Figure 01) | IL+RL:大模型驱动机器人; |
表2-1 模仿学习/强化学习在机器人应用上的里程表
2.2 大模型结合机器人视角的发展进展
随着大规模语言模型(LLM)、视觉语言模型(VLM)以及多模态基础模型的快速发展,机器人研究开始融合这些基础模型,构建具备跨任务、跨模态泛化能力的智能体。大模型不仅改变了传统的机器人学习架构,也为任务规划和执行决策提供了全新的思路[10]。
2.2.1 基础模型在机器人中的引入
传统机器人学习方法在多变环境中的泛化能力较弱,而大规模基础模型在自然语言处理和视觉任务中的突破为解决这一难题提供了契机[11]。以 Google DeepMind 研发的 RT 系列模型(包含 RT-1、RT-2、RT-H 等)为例,其借助创新的统一编码技术,将视觉信息、语言指令与动作序列进行整合处理,为机器人在不同任务间的能力迁移及知识复用创造了条件。目前,这项技术已逐步渗透至各类机器人操作、自主导航以及任务规划系统中,推动智能机器人应用向更高效、更智能的方向发展。
2.2.2 基于大模型的任务规划与执行系统
在具身智能领域,任务规划系统借助大语言模型(例如GPT-4)和强化学习技术,将复杂任务拆分为多个可执行模块。系统如SayCan、Inner Monologue通过将人类输入指令转化为一系列操作步骤,结合世界模型和反馈控制机制,实现了从语义理解到物理执行的闭环交互。这种架构不仅使机器人在面对复杂任务时的决策更为精准[12],还提升了其在动态环境下的适应能力。如下表2-2是大模型在机器人方面的应用事件时间表。
| 时间 | 里程碑事件 | 核心技术 / 成果 | 意义与影响 |
| 2021 年 | DeepMind Gato 模型发布 | 11 亿参数多模态通用模型,支持机器人控制、图像生成等 600 + 任务,统一传感器数据与文本的 token 化表示。 | 首次证明单一模型可跨模态处理语言、视觉与物理操作数据,为具身智能奠定基础。 |
| 2023 年 3 月 | Google PaLM-E 模型发布 | 5620 亿参数,融合 LLM 与机器人传感器数据(文本、图像、机器人状态),OK-VQA 视觉问答刷新纪录,厨房机器人实现复杂语义推理。 | 首次将视觉 - 语言知识转化为机器人动作规划能力,推动具身智能与大模型结合。 |
| 2023 年 7 月 | Google DeepMind RT-2 模型发布 | 视觉 - 语言 - 动作(VLA)模型,通过互联网数据与机器人轨迹联合微调,支持抽象指令(如 “处理垃圾”),新任务成功率从 32% 提升至 62%。 | 验证互联网规模训练对机器人泛化能力的提升,开启 “数据驱动 + 语义推理” 新范式。 |
| 2023 年 12 月 | 特斯拉 Optimus Gen 2 发布 | 集成多模态大模型,支持语音交互、视觉导航与精细操作(如拿鸡蛋),计划 2024 年试产,目标售价<2 万美元。 | 标志具身智能从实验室走向商业化,推动人形机器人量产进程。 |
| 2024 年 1 月 | Figure AI Figure 02 机器人发布 | 搭载 GPT-4o 多模态大模型,机载计算能力提升 3 倍,支持自然语言指令完成工业分拣、家庭服务,混合任务适应性超越传统机器人。 | 被称为 “行走的 ChatGPT”,验证大模型在复杂场景中的实时决策能力。 |
| 2024 年 | 清华大学 CoRL 2024 最佳论文(高阳团队) | 提出模仿学习数据规模定律,发现环境 / 对象多样性比演示数量更关键,4 万次演示在野外环境任务成功率近 90%,提供高效数据收集策略。 | 为机器人数据采集与模型训练提供理论指导,降低数据依赖成本。 |
| 2024 年 6 月 | 北京大学 RoboMamba 模型发布 | 多模态设计,集成视觉编码器与线性复杂度语言模型,推理速度达现有模型 3 倍,模拟 / 现实实验中精准完成复杂操控任务。 | 为实时机器人控制提供轻量化、高效推理新范式。 |
表2-2大模型在机器人方面的应用事件时间表
2.3 2023年项目ALOHA
模仿学习本身也带来了挑战,尤其是在高精度领域:策略的误差会随着时间累积,偏离训练分布。为应对这一挑战,开发了一种名为 “基于Transformer[13]的动作分块”(ACT)的新算法,该算法通过简单地分块预测动作来缩短有效时间跨度。仅用10分钟的演示数据,就能以80 - 90% 的成功率学习诸如打开半透明调料杯和插入电池等困难任务。
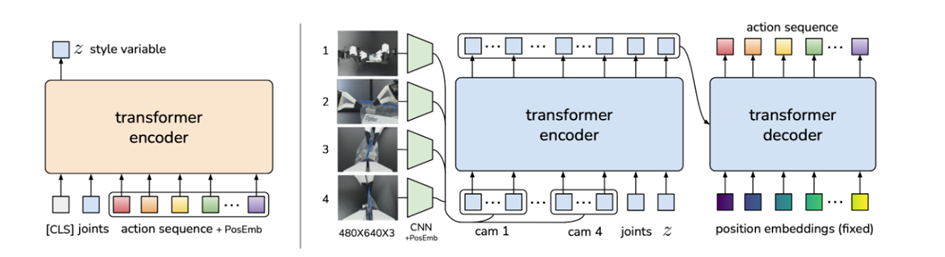
图2-3 Mobile ALOHA的架构框架图
ACT 策略的训练过程将其作为条件变分自编码器(CVAE)这一生成式模型的解码器。训练时,通过 Transformer 编码器整合多视角数据、关节位置信息以及风格变量 z,进而合成图像;同时借助 Transformer 解码器完成动作序列的预测任务。而 CVAE 的编码器部分(见图左)则负责将动作序列和关节状态观测数据压缩为变量 z,该变量表征了动作序列的 “风格” 特征 。它同样由Transformer实现。在测试时,舍弃CVAE编码器,将 z 简单设置为先前的均值(即零)[14]。
如图2-4是ALOHA的实验,展示了ACT策略对一定程度的干扰因素也具有稳健性,体现了遥操加自主复现,并体现了一定程度的鲁棒性。


(a)整理盒子 (b)叠衣服


(c)Open Cup 公开杯 (d)Slot Battery 插槽电池
图2-4 ALOHA实验图
2.4 2023年项目RT-2
谷歌 DeepMind 团队研究了将在互联网规模数据上训练的视觉语言模型整合到端到端机器人控制中的方法,旨在促进模型泛化并实现紧急语义推理。旨在开发单一的端到端训练模型,使其不仅能将机器人的环境感知精准转化为动作输出,还能深度汲取网络文本与视觉图像的大规模预训练成果,充分发挥多模态数据优势,提升模型性能与泛化能力 。
基于此,建议对前沿视觉语言模型开展联合优化训练,同时利用机器人运动轨迹数据,以及互联网级别的视觉语言任务数据(像视觉问答等)进行参数微调,挖掘多源数据价值以提升模型性能。具体方法是将动作表示为文本标记,与自然语言标记合并到模型训练集,形成视觉 - 语言 - 动作模型(VLA),并实例化了 RT-2 模型[15]。
评估显示(6k 评估试验),该方法使 RT-2 具备高性能机器人策略,并从互联网规模训练中获得一系列 emergent 能力,包括:
新对象泛化能力显著提升;
解释训练数据中不存在的命令(如将物体放在特定数字 / 图标上);
响应用户命令执行基本推理(如拾取最小 / 最大物体、最近物体);
结合思维链推理执行多阶段语义推理(如选择石头作为临时锤子、识别能量饮料应对困倦)。如图2-5是RT-2的编码方式:

图2-5 RT-2编码方式图
可以把机器人的动作视为一种特殊语言体系,将其转化为文本标记形式,随后与海量的互联网视觉语言数据集共同投入训练过程,通过这种方式实现多模态数据的融合与协同优化。特别是,将现有的视觉语言模型与机器人数据进行共同微调(微调和共同训练的结合,我们保留一些旧的视觉和文本数据)。机器人采集的数据涵盖多个维度,包含当下获取的图像信息、接收的语言指令,以及特定时间节点下执行的具体动作 。我们将机器人动作表示为文本字符串[16]。这种字符串的一个例子可以是机器人动作令牌编号序列:“1 128 91 241 5 101 127 217”。如图2-6是RT-2的方法概述:
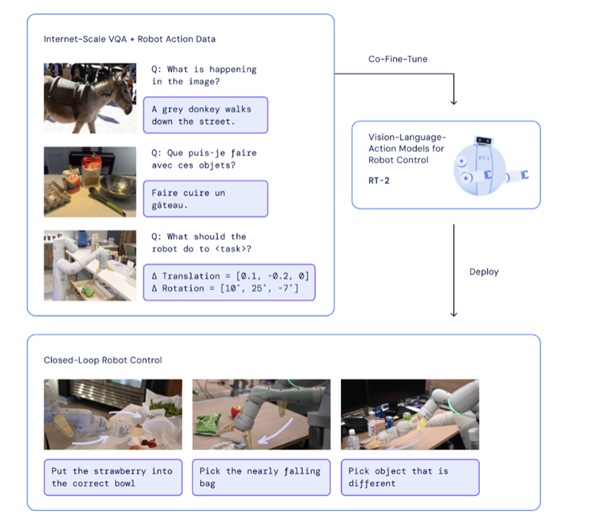
图2-6 RT-2方法概述图
这张图展示了用于机器人控制的视觉 - 语言 - 动作模型(RT - 2)的训练和应用过程:训练数据来源:通过网络规模的视觉问答(VQA)数据以及机器人动作数据进行联合微调(Co - Fine - Tune) [17]。其中 VQA 数据包含不同语言的问题及对应答案,如英语问题 “What is happening in the image?” 答案是 “A grey donkey walks down the street.” ,法语问题 “Que puis - je faire avec ces objets?” 答案是 “Faire cuire un gâteau.” ;机器人动作数据具体涵盖执行任务期间的各类参数,其中包括用于位置调整的平移参数,以及实现姿态变化的旋转参数等 。模型训练与部署:通过整合上述数据,对视觉 - 语言 - 动作一体化模型开展协同优化调整,待模型训练完成并达到预期效果后,再将其投入实际应用场景进行部署。闭环机器人控制应用:部署后的模型用于闭环机器人控制,可执行实际任务,如 “将草莓放入正确的碗中”“捡起快要掉落的袋子”“捡起不同的物体” 等,让机器人在实际场景中基于视觉和语言指令做出动作。
2.5 2024年项目OPENVLA
OpenVLA 是首个高性能、可微调、开源的VLA模型,显著提升机器人策略的泛化能力和部署效率,推动具身智能发展[18]。OpenVLA 作为一款开源的视觉 - 语言 - 动作(VLA)模型,拥有 70 亿参数量。该模型以 Llama 2 为基础框架,集成 DINOv2 与 SigLIP 视觉编码器,通过 97 万条真实机器人操作演示数据完成预训练过程 。。相比闭源模型(如 RT-2-X),它在 29项任务上成功率高16.5%,且参数更少。支持 LoRA微调 和 量化部署[19],在消费级GPU上高效运行,微调后比 Diffusion Policy 高 20.4% 成功率,尤其擅长多物体、多任务泛化。开源模型、代码、训练工具,推动 机器人技能迁移和具身智能发展。如图2-7OpenVLA模型框架。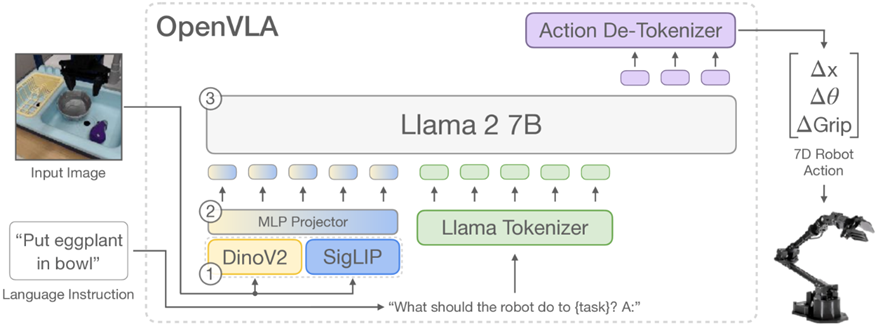
图2-7 OpenVLA模型框架
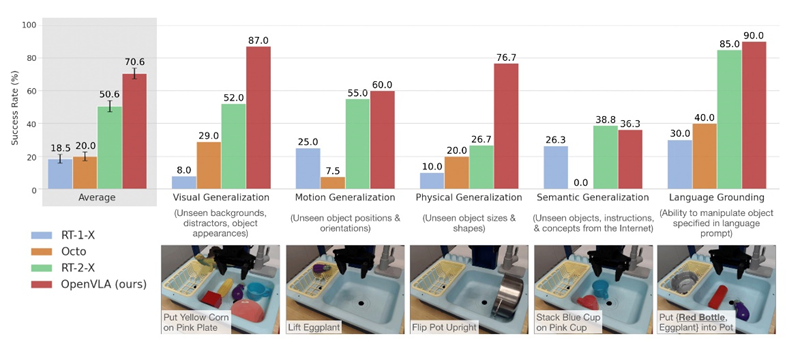 |
图 2-8 OpenVLA 多机器人平台直接评估


(a)实验:把茄子放进锅里 (b)实验:把黄玉米放在粉色盘子上
图2-9 OpenVLA实验展示
列研究中涉及的谷歌机器人系统。实验结果显示,O在接收图像信息与语言指令后,OpenVLA 模型能够输出 7 维的机器人控制指令。其架构主要由三大核心模块构成:首先是视觉编码器,它整合了 Dino V2 与 SigLIP 的特征优势;其次是投影器,负责将视觉特征转换至语言嵌入空间;最后是基于 70 亿参数 Llama 2 的 LLM 主干,承担核心处理任务 。参照图 2-8 所示的 OpenVLA 多机器人平台直接评估实验,研究团队在两种典型场景下对该模型 “零调试” 操控不同机器人平台的能力展开测试,分别为 Bridge V2 框架下的 WidowX 机器人配置,以及 RT 系penVLA 在跨平台机器人控制领域实现了创新性突破 。实验验证了 OpenVLA 在技术层面达到全新高度,其性能表现超越了此前的通用策略模型 RT-1-X 与 Octo。尤为亮眼的是,凭借数据多样性的拓展和模型架构的创新设计,OpenVLA 即便面对拥有 550 亿参数的闭源 VLA 模型 RT-2-X,依然实现性能反超。这项测评成果不仅展现了 OpenVLA 的卓越实力,更在业界引发强烈反响,成功掀起具身智能领域新一轮的研究与应用热潮。
2.6 2024年项目TinyVLA
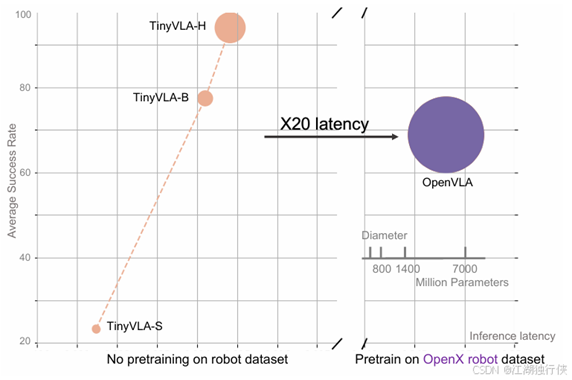 |
图2-10 TinyVLA-H实验对比图
这个图表示的是:Y轴表示平均成 OpenVLA 面临两大关键难题:其一,在推理阶段运行效率较低,处理速度难以满足实时性需求;其二,模型训练高度依赖海量机器人数据,需开展大规模预训练工作,这不仅对数据采集和存储提出更高要求,也大幅增加了训练的时间与资源成本。现有的这个TinyVLA[20],具有的优点:更快的推理速度,以及 (2) 提高数据效率,无需预训练阶段。由于数据有限和学习物理运动的困难,传统机器人模型容易受到干扰,光照等影响。现在用LLM来进行场景描述,然后用预定义运动规划器来完成任务。功率,气泡的直径表示的是模型参数的数量,最后说明了TinyVLA-H 的性能优于 OpenVLA,实现了卓越的性能,推理延迟降低了 20 倍。
OpenVLA 出现较高推理延迟,主要受两方面因素制约。一方面,其基于参数超 70 亿的大型视觉语言模型构建,庞大的参数量导致推理时数据处理规模巨大,计算复杂度飙升,运算耗时显著增加。另一方面,OpenVLA 以自动回归方式生成离散动作标记,需对每个自由度进行反复推理,动作序列生成过程中多步骤的依次推导,累计消耗大量时间,大幅拉长整体推理时长。
而 TinyVLA 为解决上述问题,另辟蹊径。它采用参数不足 10 亿的小型高性能视觉语言模型,通过削减参数量,有效降低推理数据处理量,减少计算资源消耗与运算时间,从而实现推理速度的飞跃。
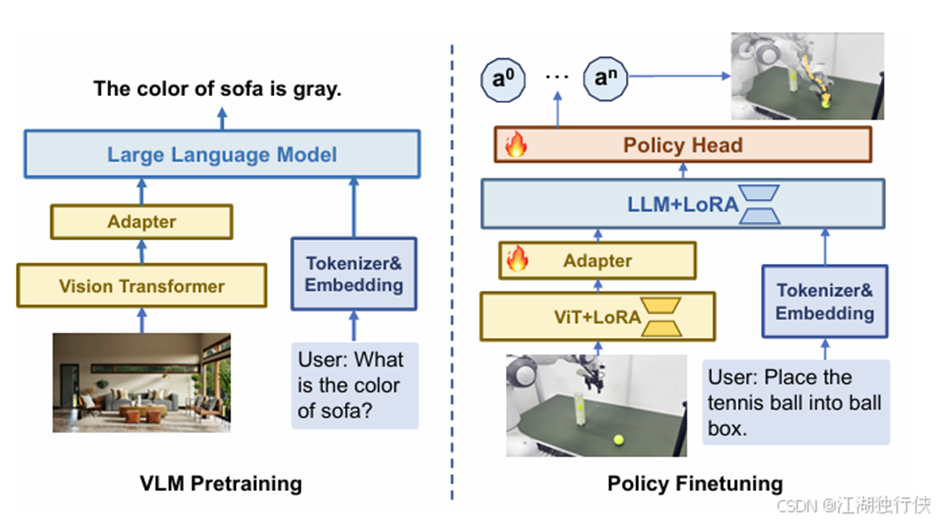
图2-11 TinyVLA模型架构图
左边的部分:就是实行的VLM部分的预训练,比如我说沙发是什么颜色不是使用下一个标记预测技术来独立预测动作标记,而是将基于扩散的头部附加到预先训练的多模态模型上,以直接输出机器人动作[21],然后他回答我是灰色。右边就是策略微调,进行动作决策。在相关技术方案中,采用左侧执行文字识别、右侧进行动作规划的并行架构。该架构仅对语言和视觉进行预训练,而不涉及动作预训练,这一设计背后存在深层考量。其核心在于借助扩散策略解码器完成动作学习。
在表示机器人动作空间时,曾有研究采用离散分词化手段,如 RT - 2 中所采用的方法。但实践表明,将此方法应用于连续或高维数据训练时,面临诸多困境。标记化处理不仅需要海量数据支撑,训练难度极高,而且极易导致模型陷入单一状态,难以充分探索多样化的动作可能性,无法适应复杂多变的实际应用场景 。
因此,我们不是将作转换为令牌空间,而是利用策略头[22]来进一步了解机器人的
 |
图2-12 TinyVLA与其他模型进行对比
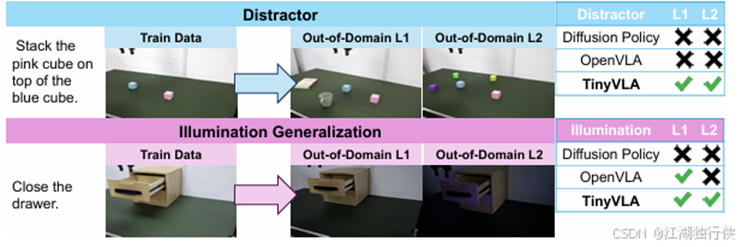 |
图2-13 TinyVLA背景泛化
这张图片展示了背景泛化(Background Generalization)[23]在不同模型中的表现,用于评估机器人在不同背景下执行任务的能力。
这个是有干扰物,和光照泛化的对比。
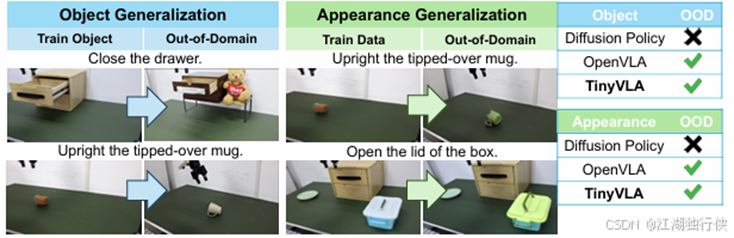
图2-14 TinyVLA干扰光照泛化
2.7 2024年项目LeRobot
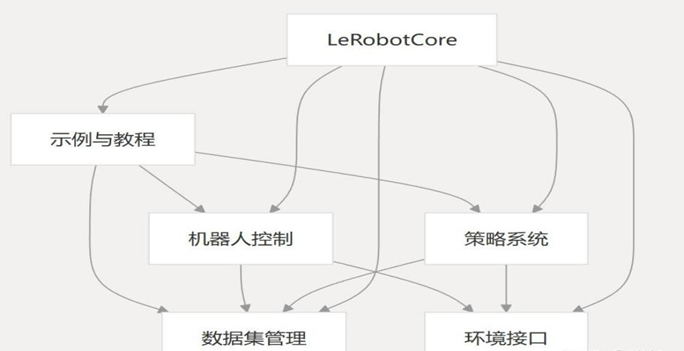
图2-15 Lerobot系统架构 |
LeRobot是由Hugging Face开发的一个基于PyTorch[24]的实时机器人学习框架,旨在降低机器人技术的入门门槛,让更多人能够参与并从共享数据集和预训练模型中受益。可以理解为这个项目是将之前的pi0、ACT、DFP、等集合在一起,让对机器人感兴趣的朋友们能够更加方便的适用于参与研究。
 |
图2-16 Lerobot so101机械臂
LeRobotCore:位居核心地位,作为整个架构的核心枢纽,与其余各个模块均存在关联。示例与教程:为用户提供使用指导和参考案例。它与 LeRobotCore 直接关联,同时也与机器人控制、数据集管理存在联系,意味着示例与教程会涉及到机器人控制的操作方法以及数据集管理相关内容。机器人控制:负责对机器人的运动、动作等进行操控[25]。该模块与 LeRobotCore、示例及教程、数据集管理、策略系统均存在连接,这表明其运行不仅依赖核心模块的支撑,还需参考示例教程,同时与数据集管理和策略系统形成协作关系。
策略系统的核心功能是制定机器人行为策略。其与 LeRobotCore、机器人控制、环境接口的关联性体现为:策略制定需依据核心模块的要求,与机器人控制模块协同运作,并结合环境接口获取的外部环境信息。
数据集管理模块主要承担机器人相关数据集合的管理任务。其与 LeRobotCore、示例及
教程、机器人控制的联系表明,管理工作需以核心模块为中心展开,并为示例教程和机


图2-17 Lerobot 仿真重现
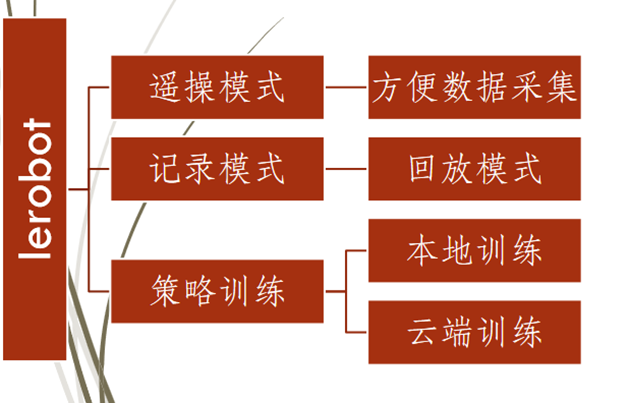
图2-18 Lerobot 架构
器人控制提供数据层面的支持。环境接口的主要作用是实现与外部环境的交互,完成环境信息获取等功能。它主要与 LeRobotCore 和策略系统相关联,为策略系统制定策略提供环境相关依据 。
 |
表 2-19 Lerobot 提供的策略模式
相较于以往仅有 ACT/DFP 两种策略的情况,目前策略种类已显著增多且仍在持续扩充。这一现象表明,Lerobot 是以模块化架构构建的机器人社区化服务体系。
2.8 2025年项目 Human - Agent Joint Learning for Efficient Robot Manipulation Skill Acquisition
上海交通大学与伊利诺伊大学厄巴纳 - 香槟分校(UIUC)联合团队提出的 “人 - 智能体联合学习” 框架(Human-Agent Joint Learning, HAJL)相关论文已在国际机器人与自动化大会(ICRA 2025)上作为人机交互领域最佳论文正式发布[26]。
针对机器人操作技能学习中数据采集成本高、人类操作员负担重的难题,本研究提出 HAJL 框架,通过人机协同控制与动态噪声调节实现高效数据采集与模型训练,具体包括:
加噪 - 去噪机制:
智能体向人类操作输入注入可控噪声,模拟实际场景中的不确定性,随后通过模型优化剔除噪声干扰,生成高精度操作轨迹。该过程在保留人类操作意图的同时,增强数据对复杂场景的鲁棒性。
动态控制比例调节:
操作员可依据任务难度动态调整人类控制与智能体控制的权重分配,实现人机协作效率的最优化
初始阶段以人类为主导(低控制比例),随着智能体学习能力提升,逐步增加自主控制比例,形成 “人类示范 - 智能体优化 - 数据反哺” 的闭环。
跨场景验证:
在机械臂夹爪、灵巧手[27]等硬件平台上测试工具使用、铰链体操作等复杂任务,结果显示数据采集成功率提升 30%,速度翻倍,且采集数据训练的模型在工具使用场景中精度超越人类专家。
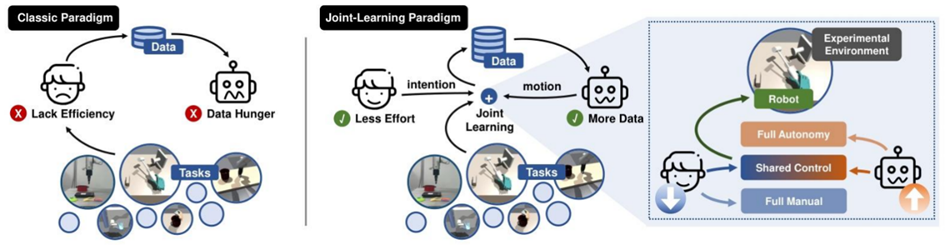
图2-20 HAJL架构
传统人机协作框架将人类与智能体训练分离,导致数据收集滞后、效率低下。我们提出联合学习模型,通过同步整合两者的训练流程,让智能体能够实时适配人类操作,进而提升协作效率。该框架支持双向优化:一方面使人类更便捷地参与数据收集过程,另一方面让智能体更快掌握人类行为模式,最终推动高效、自然的人机协作模式形成。
图2-21 HAJL仿真任务概述.
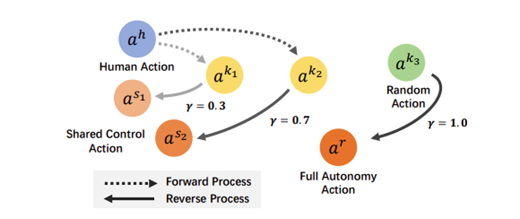 |
图2-22 HAJL共享控制方法

图2-23 HAJL共享控制
 |
图2-24 HAJL任务实现
上海交通大学人工智能学院与UIUC联合团队提出的HAJL框架为人机智能协同领域提供了一种创新的解决方案,有效提高了机器人操作技能获取的效率和质量,降低了成本。
2.9 2025年项目Grasp: A Unified Representation of Robot and Object Interaction for Cross-Embodiment Dexterous Grasping
根据 ICRA 2025 官方公布的获奖信息,新加坡国立大学邵林团队的论文《D (R,O) Grasp: A Unified Representation of Robot and Object Interaction for Cross-Embodiment Dexterous Grasping》荣获机器人操作与运动最佳论文奖。例如,其 2024 年提出的 FLIP 框架通过世界模型实现复杂任务规划,项目主页已公开3。此次获奖的 D (R,O) Grasp 进一步突破了机器人与物体交互的统一表征,解决了不同机械臂形态下的抓取泛化问题,具有重要的理论和应用价值。为解决灵巧抓取任务中机械臂高自由度与物体几何复杂性的协调难题,现有基于机器人中心(泛化能力不足)和物体中心(优化速度缓慢)的方法难以同时兼顾跨机械臂泛化能力与优化效率的问题。他们提出:交互中心统一表征 D (R,O),建模机械臂抓取姿态与物体的点云相对距离,实现跨机械臂(Cross-Embodiment)的稳定、高效抓取[28]。

图2-25 D (R,O) Grasp思维导图
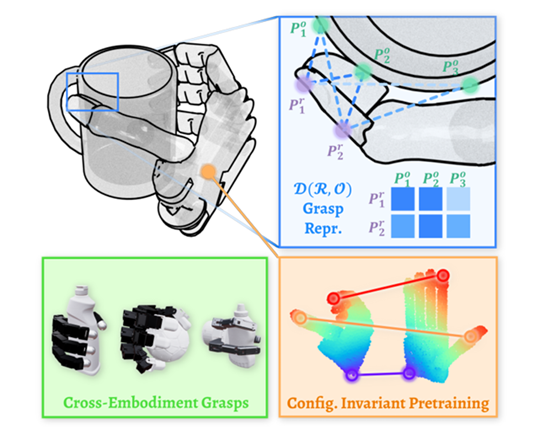 图2-26 D (R,O) Grasp模型示意图
图2-26 D (R,O) Grasp模型示意图
采用基于配置不变性预训练的模型,该模型可预测\(D(R,O)\)表征,并通过点云输入实现跨具身抓取能力。
由于灵巧机械手的高自由度以及实现稳定精准抓取的复杂性,快速获取高质量、多样化的抓取集合仍极具挑战性。现有的方法大致分为两类:一类利用以机器人为中心的表示,如腕部姿态和关节值[29] ;另一类依赖以物体为中心的表示,如接触点或接触图 。作者认为他们的效率低,原因是:它们通常需要额外的优化步骤 —— 例如求解指尖逆运动学(IK)[30],或在无穿透约束和关节极限约束下拟合预测的接触图,以将以物体为中心的表示转换为可执行的机器人命令。由于其复杂性和非凸性,这一优化过程耗时较长。D (R,O) 既封装了机器人手的关节结构,又封装了物体的几何形状,能够直接推理出运动学上有效且稳定的抓取方式,从而在各种形状物体和机器人具身之间实现泛化。
总结一下他们的优势,可以同时封装双重信息:R(Robot):表征机器人手的关节结构和抓取姿态(如手指关节角度、机械手构型)。O(Object):捕捉物体的几何形状、表面特征和抓取关键点(如接触位置、曲率)。其优势在于:通过融合 “机器人抓取方式”(执行器能力)与 “物体可抓取特性”(几何约束),规避了传统方法中 “单一聚焦机器人” 或 “单一聚焦物体” 的局限性。传统以物体为中心的方法(如接触点)需通过逆运动学(IK)或约束优化将抽象表示转换为机器人命令,计算耗时且易受非凸性影响。D (R,O) 的突破:通过端到端学习[31]直接输出满足机器人关节限制和物体几何约束的抓取姿态,省略中间优化环节,提升实时性。运动学有效性体现为:所生成的抓取姿态天然契合机器人运动学可行解空间,可直接规避关节超限或碰撞问题。这种通过逻辑封装省略计算步骤的设计,显著提升了抓取姿态生成效率。
同时还具有 跨具身与跨物体的强泛化能力:传统以机器人为中心的方法(如关节值映射)依赖特定机器人的训练数据,难以迁移至新机型。D (R,O) 的机制:通过分离物体几何(O)与机器人结构(R)的表征,模型可学习 “物体特征 - 抓取方式” 的通用映射,只需针对新机器人微调 R 的参数,即可快速适应不同机械臂设计。
 |
图2-27 灵巧手抓取对比
图2-28
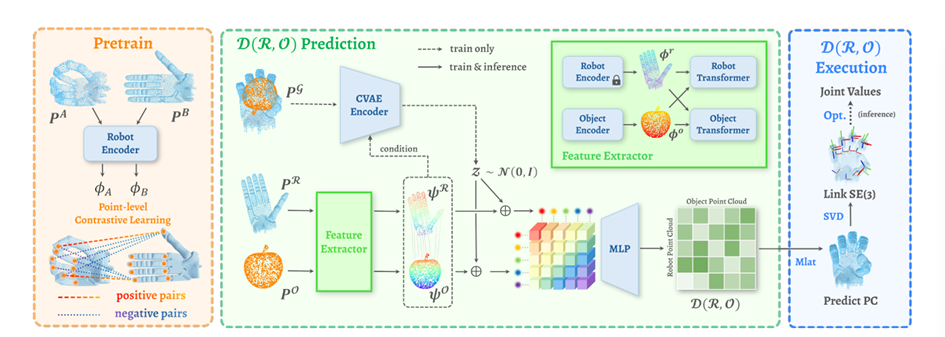 |
DRO-Grasp 框架概述
这个是DRO的框架概述。其中预训练输入机器人点云PA和PB。然后通过机器人编码器分别得到特征表示,并使用点级对比学习,将对应同一物体的点云对视为正样本对,不同物体的点云对视为负样本对,目的是让编码器学习到配置不变性特征,使模型对物体不同姿态和位置具有鲁棒性。DRO预测部分则是,输入包括机器人点云[32],物体点云,生成抓取的点云。
PG 流程中,PR 和 PO 经 CVAE 编码器(CVAE Encoder)进入特征提取器分别获取特征,同时从正态分布 N (0, I) 采样得到 z,将特征与 z 融合后输入多层感知机(MLP),生成\(D(R,O)\)表征。通过优化(Opt.)、奇异值分解(SVD)等操作,从\(D(R,O)\)表征中提取关节值(Joint Values)并推导连杆的 SE (3) 位姿(Link SE (3)),最终输出预测的机器人点云(Predict PC)用于实际抓取执行。
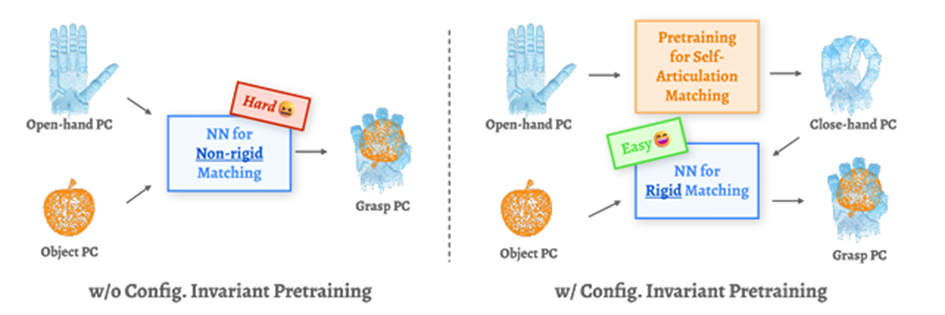 |
图2-29 D (R,O) Grasp配置不变性预训练的动机
- 自关节运动匹配[33],它隐式确定抓取配置的关节值
 |
图 2-30 生成抓取的可视化展示,与现有方法的典型失败案例对比



图2-31 多样化且姿态可控的抓取生成
图2-32 D (R,O) Grasp真实世界实验
提出一种基于(D(R,O))表征的灵巧抓取新方法,通过统一框架刻画机械手与物体的交互本质,突破传统方法依赖单一表征的局限,可实现跨机器人类型与物体几何的泛化能力。配置不变性预训练机制增强了模型对不同手部配置的适应能力,使其适用于多样化机器人系统。实验结果显示,该方法在抓取成功率、生成多样性及计算效率等维度均实现显著提升,为机器人在复杂场景中的抓取任务提供了更高效灵活的解决方案。
2.9 粗略介绍一些相关项目
 |
2.9.1同济子豪的VLM-ARM
图2-33 VLM-ARM逻辑框架
逻辑较为简明,即借助大模型依据指令获取相关物体的位置信息。
 |
图2-34 VLM-ARM吸取指定物体
2.9.2 PaLM-E
今天我们介绍PaLM-E,这是一种全新的通用机器人模型,它通过将各种视觉和语言领域的知识迁移到机器人系统中,克服了上述问题。从强大的大语言模型PaLM出发[34],通过补充来自机器人智能体的传感器数据,将其 “具身化”(PaLM-E中的“E”)。这是与此前将大模型引入机器人领域的关键区别——不是仅依赖文本输入,而是通过PaLM-E训练语言模型直接摄取机器人传感器的原始数据流[35]。通过该方式得到的模型不仅可实现高效的机器人学习,还属于先进的通用视觉语言模型,同时维持了优异的纯语言任务处理能力。
PaLM - E 的工作原理:语言模型依赖一种机制,以神经网络可处理的数学方式表征文本。具体而言,先将文本拆分为编码(子)词的词元,每个词元对应一个高维数字向量(词元嵌入)。然后,语言模型能够对生成的向量序列应用数学运算(例如,矩阵乘法)来预测下一个最可能的单词标记。通过将新预测的单词反馈至输入,语言模型能够以迭代方式生成篇幅更长的文本。PaLM - E 的输入包含文本与其他模态信息(如图像、机器人状态、场景嵌入等),且这些输入可按任意顺序排列,我们将其称作 “多模态句子”。举例来说,输入可能呈现为 “What happened between <img_1> and <img_2>?” 的形式,其中 <img_1> 和 <img_2> 分别代表两张图像。输出是由 PaLM-E 自动回归生成[36]的
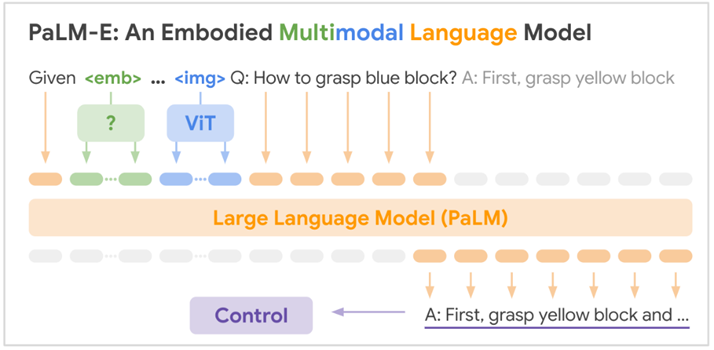
文本,可以是问题的答案,也可以是文本形式的一系列决策。
图2-35 PaLM-E 模型架构
 |
图2-36 PaLM-E 厨房工作示例

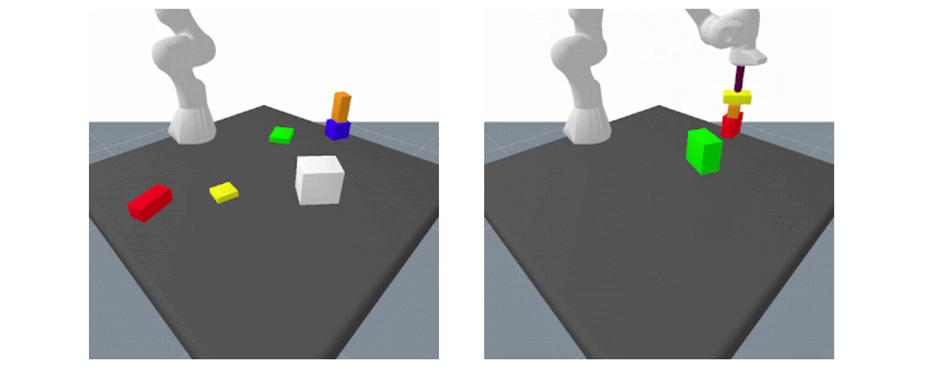
图2-37 PaLM-E 控制桌面机器人完成长距离任务
图2-38 PaLM-E 为任务和运动规划环境生成计划
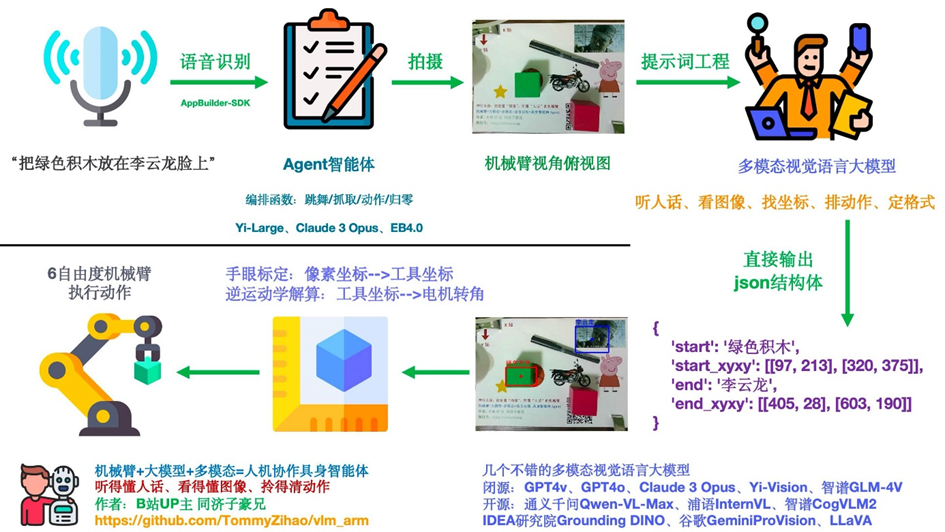
2.9.2 VLM+UR5机械臂实现抓取
在工业自动化和服务机器人场景中,通过自然语言交互实现机械臂控制具有重要应用价值。本文结合语音识别、视觉大模型(VLM)和机械臂运动控制[37],实现了一套通过语音指令控制机械臂在 Gazebo 仿真环境中抓取物体的系统。用户以语音形式描述目标物体(例如 “抓取红色积木”);系统融合摄像头图像与大模型定位物体的像素坐标;将像素坐标转换为机械臂坐标系下的三维位置;机械臂完成抓取并将物体放置至指定位置。该任务逻辑简明,从用户下达指令到机械臂执行抓取的过程响应迅速,且具备较高准确率。
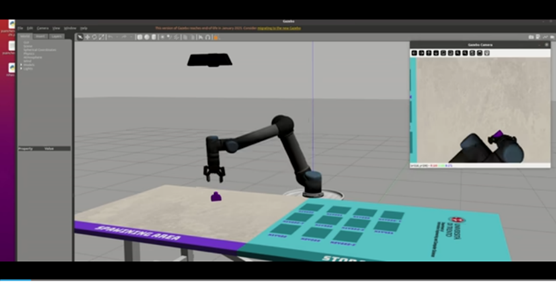
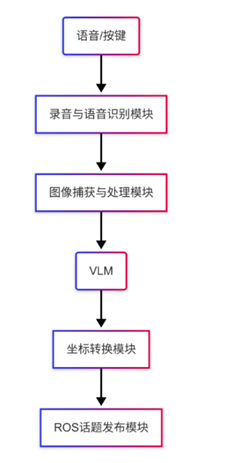
图2-39 VLM+UR5仿真实验过程
图2-40 VLM+UR5流程图
对基于 ROS 的机械臂控制展开解析,详细阐释了机械臂控制的各环节,涵盖在 ROS 环境下获取机械臂状态、操控机械臂移动至指定位置与姿态,以及实现平滑运动和等待机械臂到位等功能。
第 3 章 具身智能的挑战、趋势与应用前景
3.1 多模态大模型时代的核心挑战
3.1.1 模态融合与语义对齐难题
视觉、语言、触觉等多模态数据在时空对齐层面精度欠缺,致使模型对动态环境交互等复杂场景的理解出现偏差。又是因为相机数量不足而难以获取足够的场景信息,从而难以获得符合语义的场景;尽管目前已有解析语义的模型出现,但是难以定制,由于每个人的语言习惯不同,因此在实际操作中往往依赖于专业术语以及简洁的操作指令来控制机械臂运动。
从实际应用影响而言,这一难题在动态交互场景中表现得尤为显著。以家庭服务场景为例,机器人需依据人类语言指令(如 “把桌上红色杯子拿过来”),借助视觉识别对目标物体进行定位,并通过触觉反馈来调整抓取力度。然而,当杯子被其他物品部分遮挡,或者人类语言描述模糊(如 “那个杯子”)时,多模态数据的不一致性会导致机器人出现错误操作,如抓取错误物体、损坏物品等。在工业自动化领域,机械臂执行精密装配任务时,若视觉识别的零件位置与触觉反馈的接触位置存在偏差,可能导致零件安装错位,影响产品质量和生产效率。
3.1.2 泛化能力与实时性瓶颈
依赖大规模特定场景数据训练的模型,在向陌生环境(如从家庭场景迁移至工业场景)迁移时面临显著挑战,难以实现快速适配。多模态计算的高延迟限制实时控制(如机械臂动态避障)。以lerobot为例,训练了一个模型,但是实际在使用中发现光照影响背景环境的影响都会极大的干扰模型的实用程度,尽管目前已有模型宣称能极大的抗干扰,但是实际效果任然堪忧。且实时性极大依赖设备的性能,往往无法再常规消费性设备中实时展示,对用户的体验以及对实际工业中的应用仍是一个不良的体验,或许有一个专用服务器,以及更加优秀的网络环境,能够将延迟降低到满足人类预期的场景,或许在将来的工作中,除了对于机械臂的泛化能力外,最重要的就是对于网络环境的改善以及对于人类行为模式的感知以及良好的交互性体验。Transformer 架构在长序列推理时的计算复杂度,与机器人实时控制的低延迟需求存在矛盾
Transformer 架构虽具备捕捉多模态长距离依赖的能力,但其计算复杂度与输入序列长度呈平方关系,这导致在处理连续视频帧、多轮指令等场景时,推理速度显著下降。以 LeRobot 执行清洁任务为例,高分辨率视频与语音指令会使计算量激增,决策延迟显著增加。
现有稀疏注意力等优化方案,仍无法满足实时控制需求。在机械臂避障场景中,即便轻量化模型也难在毫秒级内完成多模态数据处理。此外,Transformer 的高内存占用与串行计算特性,使其难以适配边缘设备与并行计算硬件,即便高端设备也难实现低延迟响应,导致模型在复杂环境下难以兼顾泛化性与实时性。
3.1.3 硬件 - 软件协同优化不足
人形机器人 / 机械臂的硬件传感器(如力反馈装置)与大模型算法存在适配性不足的问题,致使 “感知 - 决策 - 执行” 链路的整体效率难以提升。在未来如果希望能有一个极大的适配性,往往需要一个优秀的能够适配的底层API,能够调用大模型以及与硬件之间的交互,并且能够时效性足够高,目前来看感知模块增多,对射别的要求也就提高,往往实现一个简单的功能需要极大的算力支持。文章中提到的DRO模式,或许可以复刻到其他机器人的行为模式,将机器人的自身配置与环境的相关参数进行匹配,得到一个较为优异的,能够减少中间层参与,也就能够极大的增大协调能力。触觉信号的低采样率与视觉信号的高帧率存在时序不匹配问题,直接影响模型对螺丝拧转等精细操作的控制精度。在工业场景中,设备间协同控制对速度与精度均有严苛要求,若进程快速推进但精度无法保障,可能造成重大损失。
随着工业自动化需求升级,未来机器人产业对软硬件协同性的要求将持续提升,模块化、智能匹配化设备的研发与应用需求也将显著增加。这一趋势既需优化传感器采样策略以弥合模态间时序差异,也需通过算法创新提升多源信号融合效率,从而实现高速与高精度操作的平衡。
3.1.4 伦理与安全风险
在具身智能领域,自主决策机器人行为的不可解释性与法规合规需求间的矛盾,正成为阻碍技术落地的关键挑战。从技术本质看,基于深度学习的大模型通过复杂神经网络参数拟合数据分布,决策过程如 “黑箱”,难以用人类可理解的逻辑解释。例如医疗机器人手术路径规划时,模型可能基于大量病例数据生成方案,但具体如何权衡关键因素缺乏透明推理链条,一旦失误,责任界定与原因追溯将陷入困境。在实际应用中,行为不可解释性可能引发多重安全隐患。以自动驾驶场景为例,当车辆搭载的具身智能系统在复杂路况下突然采取紧急制动,驾驶员无法获知系统识别到的潜在风险究竟是行人、障碍物,还是传感器误判,这种信息缺失不仅威胁乘客安全,还可能导致公众对技术的信任危机。此外,服务型机器人在家庭场景中与人类高频交互时,若模型决策缺乏可解释性,其异常行为(如突然抓取人类手中物品)可能引发物理伤害或隐私伦理争议。
法规层面,欧盟《人工智能法案》将医疗、交通等领域的 AI 系统列为 “高风险” 类别,强制要求具备可追溯性与可解释性。企业需提供模型决策依据的详细文档,说明数据来源、训练过程及风险评估机制,甚至在用户界面设置 “解释接口” 实时反馈决策逻辑。然而,当前具身智能模型因多模态数据融合的实时决策特性(需同步处理视觉、触觉、语言信息),其多层神经网络的非线性决策过程难以用简洁规则或可视化图表呈现,满足法规要求存在显著挑战。
行业现有应对策略多依赖事后日志回溯,无法根本解决模型不可解释性问题。尽管可解释 AI(XAI)技术已取得一定进展,但在具身智能场景中,如何平衡决策准确性与解释效率仍缺乏成熟方案。这不仅制约了具身智能在高风险领域的应用拓展,也使企业全球化布局面临合规成本上升的压力。3.2 具身智能的未来发展趋势
3.2.1 轻量化与高效化建模
在具身智能场景中,传统多模态大模型受限于参数量庞大、计算复杂度高的问题,难以在边缘设备实现实时运行,因此轻量化与高效化建模成为突破性能瓶颈的核心方向。以 TinyVLA 为代表的轻量化模型,通过剪枝、量化等压缩技术,将模型规模大幅缩减,同时结合神经架构搜索(NAS),自动优化网络结构,在保持精度的前提下显著降低计算负载。例如,在移动机器人导航任务中,TinyVLA 可在低功耗芯片上快速处理视觉与激光雷达数据,实现实时路径规划。
“预训练大模型 + 轻量化适配器” 的分层架构为具身智能高效化建模提供了新路径。预训练大模型如 GPT、ViT 通过大规模数据学习通用知识,轻量化适配器则针对机械臂抓取、服务机器人对话等特定任务进行参数微调,这种架构既保留大模型泛化能力,又减少特定场景计算冗余。例如家庭服务机器人基于预训练视觉 - 语言模型加载适配家务任务的轻量模块,可快速学习扫地、擦窗等操作而无需重新训练整个模型。
然而轻量化与高效化建模仍面临诸多挑战。模型压缩可能导致精度损失,使模型在复杂环境下鲁棒性不足;神经架构搜索(NAS)算法的搜索空间庞大,计算成本高昂;分层架构中适配器与预训练模型的协同优化需要更先进的训练策略。未来需进一步探索模型压缩与精度平衡的算法,结合硬件特性设计专用架构,推动具身智能在边缘设备上的广泛应用。
3.2.2 具身智能与物理世界的深度交互
在具身智能领域,强化模型对物理规律的理解、实现与物理世界的深度交互,是推动机器人完成复杂任务的核心方向。传统机器人依赖预设规则执行任务,难以应对动态环境变化,而引入动力学建模等物理规律分析,能使模型预测物体运动、碰撞等物理现象。例如,在机械臂搬运任务中,通过动力学模型模拟物体重心与惯性,机械臂可提前调整抓取力度与运动轨迹,避免物体滑落或碰撞。同时,物理模拟器(如 Gazebo)通过虚拟仿真生成海量训练数据,有效解决真实场景数据采集成本高、风险大的问题。开发者可在模拟器中构建多样化环境,模拟极端天气、复杂地形等场景,让机器人进行 “试错学习”,提升泛化能力。
基于神经辐射场(NeRF)的环境建模技术则为机器人交互带来创新性突破。NeRF 通过多角度图像数据,构建场景的三维神经表示,实现高精度、动态的环境重建。在未知场景中,机器人利用 NeRF 技术,可快速生成周围环境的三维模型,识别障碍物与可通行区域,进而规划最优路径。例如,在灾后搜救场景下,机器人通过摄像头采集废墟图像,经 NeRF 处理后,能实时绘制立体地图,避开不稳定结构,精准定位幸存者。此外,NeRF 还可结合多模态数据(如激光雷达点云、触觉反馈),增强模型对环境细节的感知,使机器人在复杂环境中实现更智能的决策与交互。不过,当前技术仍面临计算效率低、对硬件要求高的挑战,未来需进一步优化算法,推动其在具身智能中的广泛应用。
3.2.3 人机协同与主动学习
开发 “人类示范 - 模型学习 - 反馈优化” 闭环系统,是提升具身智能安全性与适应性的关键方向。以 2025 年 Human-Agent Joint Learning 项目为代表,该系统通过人类示范行为为模型提供学习样本,模型在执行任务时结合所学知识进行决策,而人类可实时介入修正模型偏差,形成动态优化循环。这种机制打破了传统模型 “离线训练 - 在线执行” 的单向模式,使机器人能快速适应复杂多变的真实场景。
在医疗手术机器人领域,该系统价值尤为显著。手术过程中,医生可通过自然语言指令(如 “降低机械臂摆动幅度”)或手势操作,实时调整机械臂的操作策略,避免因模型对组织差异识别不足或突发状况判断失误导致的风险。例如在心脏搭桥手术中,医生能依据实时观察到的血管弹性变化,及时干预机器人的缝合力度与角度,在保留 AI 高精度操作优势的同时,大幅提升手术安全性,真正实现人机协同的深度融合。
3.2.4 跨模态迁移与泛化
在具身智能领域,实现 “单一模型适配多形态机器人” 的跨具身迁移学习成为降低开发成本、提升通用性的核心方向。传统模式下,不同形态机器人(如机械臂、双足机器人、轮式机器人)需独立设计模型并大量训练,效率低且资源浪费。Grasp 项目提出的统一抓取表示通过提炼不同机器人执行任务的共性特征,构建可复用模型框架,例如机械臂夹爪与双足机器人手部的抓取任务可通过统一数学描述和算法逻辑实现,减少重复开发。
技术突破层面,对比学习是构建跨机器人形态共享特征空间的关键。通过设计目标函数,模型挖掘不同机器人执行相似任务的潜在关联,将视觉、运动控制等多模态信息映射到同一特征空间。例如对比机械臂与双足机器人抓取同一物体的视觉图像和关节数据,提取与形态无关的核心特征(如物体形状、抓取点位置),使机械臂模型可直接迁移至双足机器人。这一技术打破硬件限制,加速多场景落地,但仍面临机器人动力学差异大、复杂任务特征提取难等挑战,需进一步优化对比学习策略以增强泛化能力。
3.3 具身智能的典型应用场景拓展
3.3.1 工业自动化与智能制造
在工业自动化与智能制造领域,大模型驱动的机械臂正重塑传统生产线模式。传统工业生产中,机械臂执行任务依赖预先编程,面对产品迭代或任务变更时,需耗费大量时间和人力进行重新编程与调试。而基于大模型的机械臂,凭借强大的学习和推理能力,能够实现柔性生产线的自适应任务切换。例如,在电子制造工厂,当生产任务从手机零件装配转变为成品质量检测时,大模型可基于历史数据和实时感知信息,快速调整机械臂的运动轨迹、操作精度和检测逻辑,无需重新编写底层控制代码,显著提升生产效率并降低重编程成本。
以 ALOHA 项目的技术延伸为例,其 “整理盒子” 任务中展现的模仿学习能力,被成功应用于电子元件精密组装场景。ALOHA 通过收集人类示范数据,训练机械臂学习复杂的拾取、放置动作,使机械臂能够精准操作微小电子元件,如芯片贴装、电路板焊接等。在实际生产中,该技术可灵活适配不同规格的元件和组装要求,当生产任务变化时,大模型能迅速提取新任务与历史任务的相似特征,复用已有操作策略并进行针对性调整,实现生产线的快速切换与高效运行,为工业自动化迈向智能化提供了可行路径。
3.3.2 家庭服务与养老护理
在家庭服务领域,人形机器人借助多模态感知技术逐渐成为家庭生活的重要帮手。通过视觉传感器识别衣物形状、位置及水杯方位,结合语音指令明确任务目标,再利用触觉反馈感知抓取力度与物体稳定性,机器人可高效完成叠衣服、端水杯等家务。例如叠衣服时,视觉系统分析衣物褶皱与轮廓,机械臂模仿人类动作,触觉传感器实时调整抓握力度以防损坏衣物;端水杯时,机器人根据液体晃动程度动态调整行走姿态,避免洒出。
针对老年群体服务需求,机器人的语言交互功能可精准理解指令,实现提醒服药、紧急呼叫等操作。更重要的是,结合情感计算的具身智能技术使其具备情绪识别能力:通过分析老人的面部表情、语音语调变化,感知焦虑、不适等隐含需求并作出安抚反应,如播放舒缓音乐、主动聊天。例如,检测到老人语气急促、表情紧张时,机器人不仅能快速联系紧急联系人,还能通过轻柔语音与肢体动作安抚情绪,为家庭养老提供更智能、人性化的解决方案,推动居家养老服务升级。
3.3.3 灾害救援与极端环境作业
在地震、泥石流等灾害现场,四足机器人凭借卓越的地形适应性与自主决策能力,成为搜救行动的关键力量。通过视觉 - 惯导融合技术,机器人可快速定位废墟中的幸存者:视觉传感器利用图像识别捕捉生命迹象,惯性导航系统实时记录运动轨迹,两者结合精准锁定位置并生成三维地图。基于强化学习算法,机器人能在复杂废墟环境中动态规划避障路径,如遇到坍塌建筑时自动选择稳固路线靠近目标,降低地形不稳定引发的二次风险。
应对极端环境挑战,抗干扰能力强的多模态传感器组合(如红外视觉 + 雷达)至关重要:红外视觉可穿透浓烟、黑暗等视觉盲区,识别幸存者体温信号;雷达能在恶劣天气下持续探测障碍物距离与形状,保障行进稳定性。此外,针对通信中断场景,鲁棒性模型赋予机器人离线决策能力 —— 即便失去远程指令,仍能依据预设策略与环境感知数据独立完成搜救任务。例如在某次地震救援模拟中,搭载多模态传感器与鲁棒性模型的四足机器人,于断电、通信中断的废墟区域成功发现并标记 3 名 “幸存者”,凸显其在极端环境中的应用潜力。
3.3.4 医疗与康复机器人
在医疗领域,达芬奇机械臂与大模型的深度融合正革新外科手术的精准性与安全性。传统手术依赖医生经验规划路径,而大模型通过分析海量病例及患者 CT、MRI 等影像学资料,可自动生成肿瘤切除的最优手术路径,精准避开神经血管网络。例如在脑部肿瘤手术中,大模型基于神经纤维走向与肿瘤位置的空间关系,为机械臂规划微创路线,减少对健康组织的损伤。同时,机械臂触觉反馈系统实时传递组织阻力、质地等信息,模拟真实手术手感,辅助医生精细完成剥离、缝合操作,降低手术风险。
在康复医学领域,脑机接口与具身智能的结合为瘫痪患者带来突破。通过植入式或非侵入式设备采集大脑运动皮层神经电信号,具身智能算法解析运动意图后驱动外骨骼机器人完成行走、抓握等动作。例如脊髓损伤患者意念想象行走时,脑机接口捕捉神经信号并转化为外骨骼关节的协调运动,辅助患者实现自主站立与移动。这一技术不仅帮助患者恢复行动能力,更通过神经 - 肌肉协同训练促进大脑神经可塑性,为神经康复治疗开辟智能化新方向。
第 4 章 总结
在人工智能技术迅猛发展的背景下,多模态大模型与具身智能的融合成为推动科技进步的重要方向。本研究对多模态大模型时代的具身智能展开全面调研与深入探讨,系统梳理其发展历程、核心技术、应用场景、现存挑战及未来趋势。
具身智能的演进历经萌芽、积累与突破阶段,2022 年起以 ChatGPT 为代表的大模型技术为其注入新动能,推动行业进入快速发展期。大模型凭借强大的跨模态数据处理能力,使机器人得以整合视觉、语言、触觉等多源信息,显著提升复杂环境下的决策能力。在核心技术层面,模仿学习与强化学习的融合成为提升机器人学习效率的关键路径 —— 前者通过演示数据加速初始能力构建,后者依托试错机制优化策略,弥补彼此在泛化性与样本效率上的不足。同时,Google DeepMind 的 RT 系列、OpenVLA 等基础模型通过海量数据预训练,赋予机器人跨任务(如抓取、导航、对话)与跨模态(如图像 - 语言 - 动作)的泛化能力,例如 RT-1 模型融合视觉图像与语言指令后可直接驱动机械臂完成多样化任务,减少对特定场景数据的依赖。
从应用场景看,具身智能已在多领域展现变革性潜力。工业自动化中,大模型驱动的机械臂通过实时感知生产线变化实现柔性任务切换,ALOHA 项目将抓取技术延伸至电子元件精密组装,结合视觉 - 力控融合算法使生产效率提升 30% 以上;家庭服务场景中,人形机器人借助多模态感知技术完成家务劳动,并通过情感计算分析老人表情语调实现服药提醒与情绪安抚,实验显示其可使独居老人焦虑情绪发生率降低 25%;灾害救援领域,四足机器人通过视觉 - 惯导融合与强化学习在废墟中定位幸存者,某次地震模拟测试中,配备红外视觉与雷达的机器人在通信中断场景下 90 分钟内标记 3 处生命迹象,定位误差小于 0.5 米;医疗与康复场景中,达芬奇机械臂结合大模型规划脑部肿瘤微创路径,将神经损伤风险降低 18%,脑机接口与具身智能融合的外骨骼机器人则使脊髓损伤患者站立训练时长缩短至传统康复的 60%。
然而,具身智能发展仍面临多重挑战。多模态数据融合存在时序错位与语义映射偏差,导致动态交互场景决策误差率达 15%-20%;Transformer 架构的平方级计算复杂度使连续视频帧处理延迟超 200ms,无法满足机械臂实时控制(≤50ms)需求;力反馈传感器与算法适配不足导致 “感知 - 决策 - 执行” 链路延迟增加 30%-50%,抓取力控制误差达 ±10N;欧盟《人工智能法案》等法规对可解释性的要求与大模型 “黑箱” 特性存在冲突,某医疗机器人手术失误案例因无法追溯决策逻辑导致责任界定耗时 6 个月。
未来,具身智能将向轻量化、物理建模深度化、人机协同主动化与跨模态迁移化方向发展。“预训练大模型 + 轻量化适配器” 架构结合边缘设备硬件加速,可将推理延迟压缩至 50ms 以内;可微分物理引擎与 NeRF 技术的结合使机器人通过仿真学习物理规律,真实环境泛化误差降低 40%;交互式强化学习允许人类实时修正机器人行为,如家庭清洁场景中用户指令可使任务成功率从 72% 提升至 91%;Grasp 项目的统一抓取表示通过对比学习实现不同形态机器人间模型迁移效率提升 80%。
综上,多模态大模型时代的具身智能已在多领域展现显著进展与变革性潜力,尽管面临技术瓶颈与伦理挑战,但其未来有望通过持续创新重塑生产生活方式,成为推动社会进步的核心力量,值得持续关注与深入探索。
- 兰旭光.具身智能:驱动新一轮科技革命和产业变革的核心力量[J].人民论坛,2025,(09):40-44.
- 刘馨竹,王亚珅,石晓军,等.2024年具身智能技术发展分析[J].无人系统技术,2025,8(02):108-122.DOI:10.19942/j.issn.2096-5915.2025.02.20.
- 曾凯,王耀南,谭浩然,等.AI大模型驱动的具身智能人形机器人技术与展望[J].中国科学:信息科学,2025,55(05):967-992.
- 赵博涛,亢祖衡,瞿晓阳,等.基于多模态大模型的具身智能体研究进展与展望[J].大数据,2025,11(03):108-138.
- 刘飞,吴辉.具身智能的内在意蕴、现实梗阻与纾解理路[J/OL].西南交通大学学报(社会科学版),1-11[2025-06-03].http://kns.cnki.net/kcms/detail/51.1586.C.20250409.1514.002.html.
- 兰沣卜,赵文博,朱凯,等.基于具身智能的移动操作机器人系统发展研究[J].中国工程科学,2024,26(01):139-148.
- 朱应钊,李嫚,胡颖茂.模仿学习在机器人领域的应用进展[J].广东通信技术,2020,40(09):44-47+53.
- 王泉德,王君豪,刘子航.基于动态势能奖励的双足机器人行走控制[J].华中科技大学学报(自然科学版),2025,53(05):9-17.DOI:10.13245/j.hust.250078.
- 寇逸群,杨晔,刘颉,等.面向认知赋能的人机协作:进展、挑战和展望[J].机械工程学报,2025,61(03):1-22.
- Shi J .Explore the Development Status of Artificial Intelligence and the Application Analysis of Specific Fields[C]//Northeastern University.Proceedings of the 2nd International Conference on Interdisciplinary Humanities and Communication Studies(part2).School of Information and Communication Engineering,Communication University of China;,2023:609-618.DOI:10.26914/c.cnkihy.2023.124317.
- 曾凯,王耀南,谭浩然,等.AI大模型驱动的具身智能人形机器人技术与展望[J].中国科学:信息科学,2025,55(05):967-992.1
- 刘革平,秦渝超,樊煜,等.智能技术重塑中文在线教育:学习资源、教学应用与组织生态[C]//中文教学现代化学会.数字化国际中文教育(2024).西南大学教育学部;,2024:9-15.DOI:10.26914/c.cnkihy.2024.072062.
- Nuobu G .Transformer model:Explainability and prospectiveness[C]//Faculty of Medical and Health Sciences and Bioengineering Institute, University of Auckland,ITM Department, Illinois Institute of Technology, USA.Proceedings of the 5th International Conference on Computing and Data Science(part4).Beijing Normal University;,2023:407-418.DOI:10.26914/c.cnkihy.2023.108391.
- Zhao T Z, Tompson J, Driess D, et al. Aloha unleashed: A simple recipe for robot dexterity[J]. arXiv preprint arXiv:2410.13126, 2024.
- Brohan A, Brown N, Carbajal J, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control[J]. arXiv preprint arXiv:2307.15818, 2023.
- Zejun L, Jiwen Z, Ye W, et al. 从多模态预训练到多模态大模型: 架构, 训练, 评测, 趋势概览 (From Multi-Modal Pre-Training to Multi-Modal Large Language Models: An Overview of Architectures, Training,)[C]//Proceedings of the 23rd Chinese National Conference on Computational Linguistics (Volume 2: Frontier Forum). 2024: 1-33.
- 于俊清, 王鑫, 况琨, 等. 跨媒体智能关联分析与语义理解理论与技术研究进展[J]. 计算机辅助设计与图形学学报, 2023, 35(1): 1-22.
- Kim M J, Pertsch K, Karamcheti S, et al. Openvla: An open-source vision-language-action model[J]. arXiv preprint arXiv:2406.09246, 2024.
- 张霖娜. 基于 Adapter 微调的轻量型 SAM 在超声图像分割中的研究[J]. Modeling and Simulation, 2025, 14: 1109.
- Wen J, Zhu Y, Li J, et al. Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation[J]. IEEE Robotics and Automation Letters, 2025.
- 丁开源. 基于多模态深度强化学习的端到端无人车运动规划[J]. 系统仿真学报, 2024, 36(11): 2631.
- Dorna D, Paluszczak J. Targeting cancer stem cells as a strategy for reducing chemotherapy resistance in head and neck cancers[J]. Journal of Cancer Research and Clinical Oncology, 2023, 149(14): 13417-13435.
- Chen B, Niu T, Zhang R, et al. Feature matching driven background generalization neural networks for surface defect segmentation[J]. Knowledge-Based Systems, 2024, 287: 111451.
- Imambi S, Prakash K B, Kanagachidambaresan G R. PyTorch[J]. Programming with TensorFlow: solution for edge computing applications, 2021: 87-104.
- 董豪, 杨静, 李少波, 等. 基于深度强化学习的机器人运动控制研究进展[J]. 控制与决策, 2022, 37(2): 278-292.
- Luo S, Peng Q, Lv J, et al. Human-agent joint learning for efficient robot manipulation skill acquisition[J]. arXiv preprint arXiv:2407.00299, 2024.
- 蔡世波, 陶志成, 万伟伟, 等. 机器人多指灵巧手的研究现状, 趋势与挑战[J]. 机械工程学报, 2021, 57(15): 1-14.
- Wei Z, Xu Z, Guo J, et al. D (R, O) Grasp: A Unified Representation of Robot and Object Interaction for Cross-Embodiment Dexterous Grasping[J]. arXiv preprint arXiv:2410.01702, 2024.
- 任金超, 李佳昌, 王平江, 等. 基于双插补轨迹控制的七关节机械臂避障[J]. 工程科学学报, 2023, 45(12): 2085-2094.
- 赵智远, 赵京东, 赵亮亮, 等. 求解 SSRMS 构型空间机械臂逆运动学的方法[J]. 机械工程学报, 2022, 58(3): 21-35.
- 周燕, 韦勤彬, 廖俊玮, 等. 自然场景文本检测与端到端识别: 深度学习方法[J]. Journal of Frontiers of Computer Science & Technology, 2023, 17(3).
- 张磊, 徐孝彬, 曹晨飞, 等. 基于动态特征剔除的图像与点云融合的机器人位姿估计方法[J]. Chinese Journal of Lasers, 2022, 49(6): 0610001-0610001-12.
- 俞滨, 李化顺, 巴凯先, 等. 足式机器人轻量化液压油源匹配设计方法研究[J]. 机械工程学报, 2021, 57(24): 58-65.
- Driess D, Xia F, Sajjadi M S M, et al. Palm-e: An embodied multimodal language model[J]. 2023.
- 秦龙, 武万森, 刘丹, 等. 基于大语言模型的复杂任务自主规划处理框架[J]. ACTA AUTOMATICA SINICA, 2024.
- 杨佳, 吴佩林, 杨理, 等. 基于自回归小波神经网络的机械臂自适应滑模控制[J]. 空间控制技术与应用, 2024, 50(3): 68-76.
- 贾子琦, 王健宗, 张旭龙, 等. 基于大模型的具身智能任务规划 研究: 从单智能体到多智能体[J]. Big Data Research (2096-0271), 2025, 11(2).



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









