






1.安装nltk库
打开终端输入如下命令安装NLTK库
pip install -U nltk安装完成以后,在终端启动Python,然后输入如下命令测试是否安装成功:
import nltk2.如果希望在计算机上安装单独的的数据包,或者下载全部的数据包,则需要在Jupyter Notebook(或者管理员账户)执行下列操作
import nltk
nltk.download() #打开NLTK下载器注:可能会出现以下问题
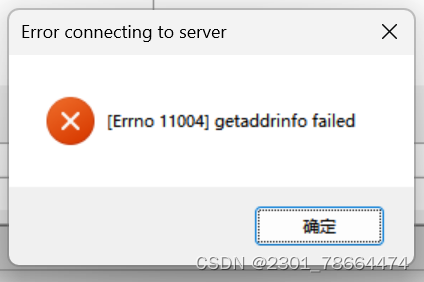
以下就是解决方法
2.1首先,确定安装目录:
我的是C:\Users\Lenovo\AppData\Roaming\nltk_data
可以在弹出的界面查看自己的路径(不要随便更改,要不然可能会导致错误)
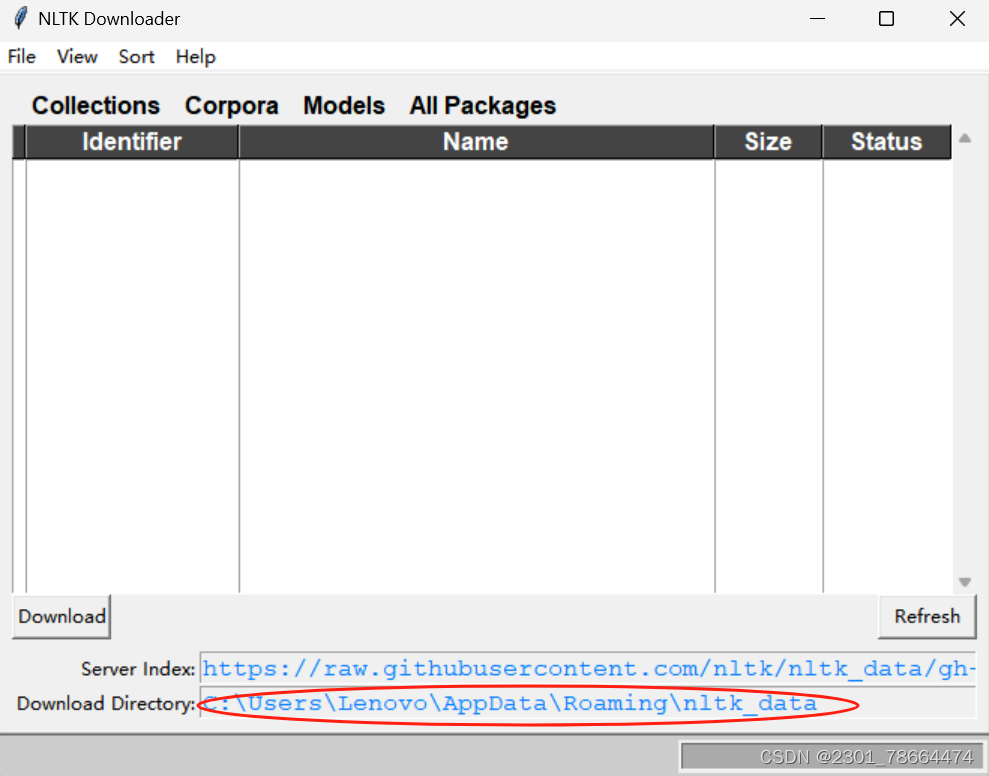
2.2下载数据包并解压到nltk_data文件夹
提取码:xcka
2.3测试是否成功
输入下述代码
import nltk
from nltk.book import *出现红色框内就是成功啦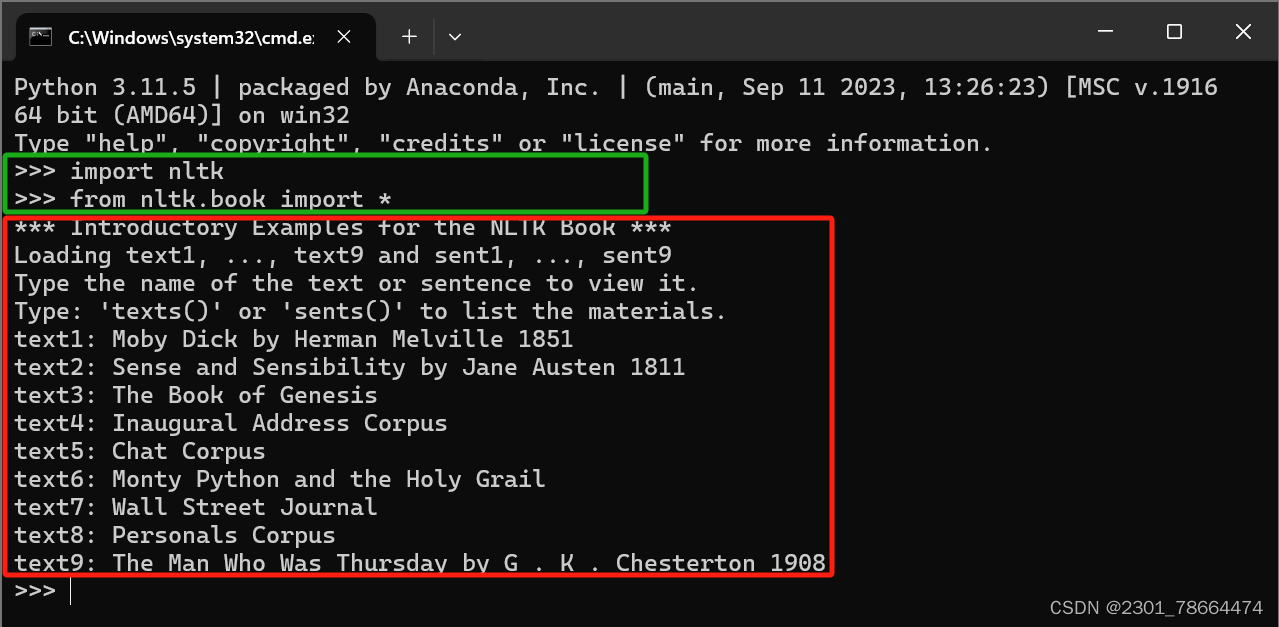
2.4也可以在python环境下输入下述代码,来验证是否成功
from nltk.corpus import brown
brown.words()结果为下图即为成功
![]()
最后,动手开始你的安装吧(随手点赞哦)

















 1792
1792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









