







首先使用conda安装nltk:
conda install nltk安装成功后,打开python编辑器,输入下面代码下载NLTK_DATA语料库
import nltk
nltk.download()如果下载成功的话其实可以直接进行使用了。
我这里下载失败,所以需要用下面的方法手动加载语料库。
1.记住路径
失败之后记住这个窗口显示的路径,手动进入该目录
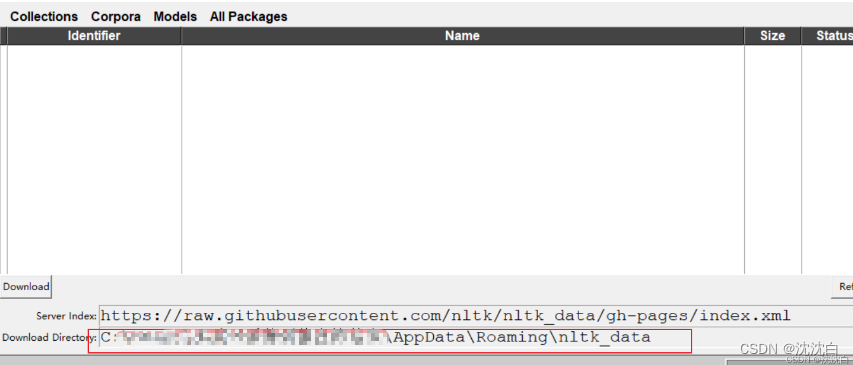
2.下载语料
可以单独从 http://www.nltk.org/nltk_data/下载需要的语料。
网传只用来处理分词的话也可以只下载下面这个,但是亲测不够用,还是需要全部的语料。。。

全部的语料我是从github下载的:GitHub - nltk/nltk_data: NLTK Data
3.放入指定位置
在1的路径下创建文件夹 nltk_data,在nltk_data文件夹中再创建文件夹 tokenizers,把下载好的 punkt.zip 解压到 C:\Users\xxx\AppData\Roaming\nltk_data\tokenizers 路径。
效果如下。
如果下载了全部语料,就不用新建文件夹,直接放到目录即可。
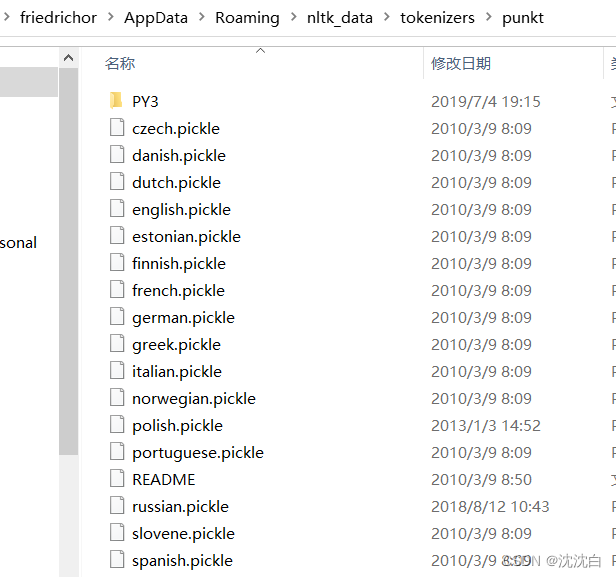
4. 检查安装成功
import nltk
text=nltk.word_tokenize("brad pitt, 54 years old , will join as a nonexecutive actor on Nov. 29 .")
print(text)5.自定义
如果觉得语料包太大,不想使用1中的默认路径占用c盘的话(大概2.3G),可以用下面代码修改nltk的路径,比如把nltk_data放到d盘下面
import nltk
nltk.data.path.append('D:\\nltk_data')下面就可以愉快进行语义分析了~

















 1777
1777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









