






在云计算与大数据时代,传统单机数据库面临三大挑战:海量数据存储、高并发访问和实时分析需求。MySQL分库分表方案复杂、NoSQL缺乏ACID支持、MPP数仓难以处理OLTP... 在这样的背景下,TiDB应运而生。作为一款开源的分布式NewSQL数据库,TiDB完美融合了关系型数据库与NoSQL的最佳特性。
TiDB 是一款开源的分布式关系型数据库,融合了传统关系型数据库和 NoSQL 数据库的优势,具备高可用、强一致、弹性扩展等特点。以下是使用 TiDB 的主要原因:
1. 核心优势
水平扩展能力强:TiDB 基于分布式架构,可以通过增加机器实现水平扩展,轻松应对海量数据和高并发场景。例如,当数据库读写压力增大时,只需增加节点,TiDB 会自动均衡数据,确保集群性能。
强一致性:采用 Raft 协议,确保数据在分布式环境下的强一致性和高可用性。即使部分节点故障,数据也不会丢失。
兼容 MySQL:支持 MySQL 协议、SQL 语法、索引和事务等特性,可无缝迁移 MySQL 数据,无需重写大量代码。
实时 HTAP 支持:结合行存储引擎 TiKV 和列存储引擎 TiFlash,TiDB 支持在线事务处理(OLTP)和在线分析处理(OLAP),可同时进行实时数据插入和复杂查询。
云原生支持:作为云原生数据库,TiDB 支持容器化部署(如 Kubernetes),适合云计算环境,便于弹性伸缩。
2. 适用场景
金融行业:对数据一致性、高可用性和容灾要求极高。TiDB 采用多副本和 Multi-Raft 协议,确保 RTO(恢复时间目标)≤30 秒,RPO(恢复点目标)=0。
海量数据及高并发 OLTP 场景:TiDB 的计算和存储分离架构支持分别扩缩容,计算最大支持 512 节点,每个节点支持 1000 并发,集群容量可达 PB 级。
实时 HTAP 场景:在 4.0 版本中引入 TiFlash 后,TiDB 可在同一个系统中完成联机交易处理和实时数据分析,节省企业成本。
数据汇聚与二次加工:可将分散在不同系统的数据汇聚到 TiDB 中进行二次加工处理,生成 T+0 或 T+1 的报表。
典型应用场景:分库分表
- SQL
关系型数据库(RDBMS,即SQL数据库)
商业软件: Oracle,DB2
开源软件:MySQL,PostgreSQL
关系型数据库面临的单机版本已经很难满足海量数据的需求
- NoSQL
NoSQL = Not Only SQL,意即“不仅仅是SQL,提倡运用非关系型的数据存储
普遍选择牺牲掉复杂 SQL 的支持及 ACID 事务换取弹性扩展能力
通常不保证强一致性的(支持最终一致)
主要分类键值(Key-Value)数据库:如 MemcacheDB,Redis
文档存储:如 MongoDB
列存储:方便存储结构化和半结构化数据,并做数据压缩,对某几列的查询有非常大的IO优势: 如 HBase,Cassandra
图数据库:存储图关系(注意:不是图片)。如 Neo4J
- NewSQL
针对OLTP的读写,提供与NOSQL相同的可扩展性和性能,同时能支持满足ACID特性的事务,即保持NoSQL的高可扩展和高性能,并且保持关系模型
为什么需要NewSQLNoSQL 不能完全取代 RDBMS
单机RDBMS 无法满足性能需求
使用“单机RDBMS + 中间件”方式,在中间件层很难解决分布式事务、高可用问题
一、TiDB核心特性解析
1.1 真正的HTAP架构
HTAP(Hybrid Transactional/Analytical Processing)是TiDB区别于传统数据库的杀手锏:
-
行列混合存储引擎:
-
TiKV(行存):基于RocksDB的键值存储,优化OLTP场景
-
TiFlash(列存):通过RAFT Learner异步复制,提供实时分析能力
-
-
智能路由引擎:
EXPLAIN SELECT * FROM orders WHERE region='Asia' /*+ READ_FROM_STORAGE(TIFLASH[orders]) */;
通过Hint或优化器自动选择存储引擎
-
2 水平扩展能力
-
通过添加TiKV节点实现存储与计算能力的线性扩展:
-
数据自动分片(Region)
-
PD调度器动态平衡负载
-
在线DDL不影响业务
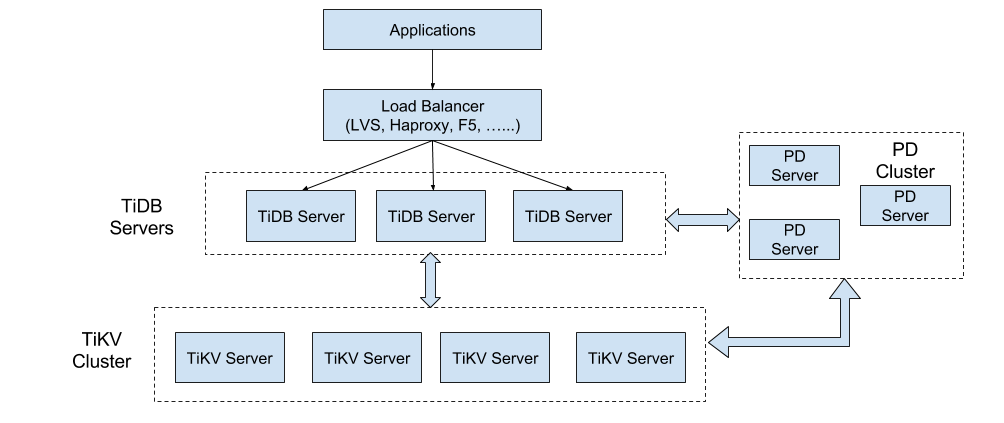
二、TiDB架构深度解析
2.1 分层架构设计
| 组件 | 作用 | 关键技术 |
|---|---|---|
| TiDB Server | 无状态SQL层 | 分布式SQL优化器 |
| TiKV | 分布式事务型存储引擎 | Raft共识算法、MVCC |
| PD | 元数据管理&调度中心 | TSO全局时钟、热点调度 |
| TiFlash | 列存分析引擎 | 向量化计算、MPP执行引擎 |
TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑并通过 PD Server找到存储计算所需数据的TiKV 地址,与 TiKV 交互获取数据,最终返回结果。TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址
PD Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个:
一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);
二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);
三是分配全局唯一且递增的事务 ID。
PD 通过 Raft 协议保证数据的安全性。Raft 的leader server 负责处理所有操作,其余的 PD server 仅用于保证高可用。建议部署奇数个 PD 节点
三、TiDB生态全景
| 工具 | 用途 | 特点 |
|---|---|---|
| DM | 数据迁移 | 支持MySQL/MariaDB全量+增量 |
| Lightning | 快速导入 | TB级数据导入速度提升5倍 |
| BR | 备份恢复 | 分布式快照备份 |
| TiCDC | 数据变更捕获 | 提供Kafka、MySQL Sink |
四、总结:
传统关系型数据库历史比较久,目前RDBMS的代表为Oracle、MySQL、PostgreSQL,在数据库领域也是“辈份”比较高的,其广泛应用在各行各业,RDBMS大多为本地存储或共享存储。
但是此类数据库存在着一些问题,如自身容量的限制。随着业务量不断增加,容量渐渐成为瓶颈,此时DBA会通过多次的库表sharding,以此来缓解容量问题。大量的分库分表,不仅耗费了大量人力,还使得业务访问数据库的路由逻辑变得复杂。除此之外,RDBMS伸缩性比较差,通常集群扩容缩容成本较高,且不满足分布式的事务。
NoSQL类数据库的代表为Hbase、Redis、MongoDB、Cassandra等,这类数据库解决了 RDBMS伸缩性差的问题,集群容量扩容变得方便很多,但是由于存储方式为多个KV存储,所以对SQL的兼容性就大打折扣。对于NoSQL类数据库来说,只能满足部分分布式事务的特点。
NewSQL领域的代表是Google的spanner和F1,其号称可以实现全球数据中心容灾,且完全满足分布式事务的ACID,但是只能在Google云上使用。TiDB诞生在大背景下,也弥补了国内在NewSQL领域中的空缺。TiDB自2015年5月写下第一行代码以来,至今已发布大小版本几十次,版本迭代十分迅速



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









