









系列篇章💥
目录
前言
在人工智能技术飞速发展的当下,大模型的应用已经渗透到各个领域。然而,通用的大模型往往无法完全满足特定场景的需求,因此对模型进行微调成为了提升模型性能和适用性的关键手段。Swift框架凭借其灵活的特性和高效的性能,为模型微调提供了强大的支持。本实战指南将详细介绍如何使用Swift框架对自定义数据集进行微调,从模型准备、数据集准备,到模型微调、推理,再到模型合并与加速推理,一步步带领大家完成整个微调流程,帮助你更好地利用自定义数据提升模型的表现,满足实际业务的需求。
一、模型准备
1. 模型下载
在下载模型之前,确保已经安装了 git-lfs。git-lfs(Git Large File Storage)是一个用于管理大型文件的扩展,在下载包含大文件的模型时非常必要。如果尚未安装,可以通过以下命令进行安装:
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
上述命令通过 curl 脚本添加 git-lfs 的软件源,然后使用 apt-get 进行安装。安装完成后,需要初始化 git-lfs,可以使用命令 git lfs install 来完成初始化。
接下来,从 modelscope 的模型库中下载模型权重文件。这里我们选择下载 Qwen2.5-7B-Instruct 模型:
git clone https://www.modelscope.cn/Qwen/Qwen2.5-7B-Instruct.git
此命令会将 Qwen2.5-7B-Instruct 模型的所有文件克隆到当前目录下。在下载过程中,由于模型文件可能较大,需要确保网络稳定,并且磁盘空间足够。如果下载过程中出现中断,可以使用 git lfs pull 命令继续下载未完成的文件。
下载效果如下:

2. 模型推理
在下载完模型后,我们可以通过以下脚本进行模型推理,以验证模型是否能够正常工作:
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--model /root/autodl-tmp/Qwen2.5-7B-Instruct \
--infer_backend pt \
--stream true
CUDA_VISIBLE_DEVICES=0:指定仅使用编号为 0 的 GPU 进行推理。在多 GPU 环境中,通过这个环境变量可以灵活选择使用的 GPU。swift infer:执行 Swift 框架的推理命令。--model /root/autodl-tmp/Qwen2.5-7B-Instruct:指定推理使用的模型文件路径。请确保路径正确,否则会导致模型加载失败。--infer_backend pt:指定使用 PyTorch 作为推理后端。PyTorch 是一个广泛使用的深度学习框架,具有强大的计算能力和丰富的工具库。--stream true:开启流模式,使得模型生成的回答能够实时逐步返回,提升用户体验。
执行上述命令后,输入一些测试问题,观察模型的响应。如果模型能够正常输出合理的回答,说明模型下载和配置正确,可以进行后续的微调操作。

二、数据集准备
我们将对 Qwen2.5-7B-Instruct 模型进行微调,为此需要准备一份合适的数据集。这里我们整理编写一份 alpaca 格式的数据集,并上传到服务器。alpaca 格式的数据集通常包含 instruction(指令)、input(输入)和 output(输出)三个字段,示例如下:
[
{
"instruction": "寻道AI小兵是什么?",
"input": "",
"output": "寻道AI小兵是一名CSDN技术博主"
},
{
"instruction": "寻道AI小兵是什么?",
"input": "",
"output": "寻道AI小兵是一名CSDN技术博主"
},
{
"instruction": "寻道AI小兵的博客主题是什么?",
"input": "",
"output": "寻道码路,探索编程之路的无限可能。"
},
{
"instruction": "寻道AI小兵的博客特色?",
"input": "",
"output": "深入探索AI大模型,分享系统架构和编程实践的经验。"
}
]
在实际应用中,为了方便测试,我们可以直接使用大模型帮忙生成数据集。例如,使用以下提示让大模型生成一份包含 10 条 json 格式的 alpaca 数据集:
请基于下面提供的文本内容,生成一份包含 10 条json格式的alpaca数据集:
CSDN技术博主:寻道AI小兵;码龄15年
个人简介:探索未知,分享所知。作为一名系统架构师,我曾带领团队打造多个行业领域的系统平台。如今,我正踏上AI大模型的探索之旅,期待与你一起成长,迎接技术的未来。
博客简介:寻道码路,探索编程之路的无限可能。
博客描述:在这里,我将带你深入AI大模型的内部世界,揭秘学习过程中的洞见和挑战。分享我在系统架构和编程实践中的经验,一起探索AI技术的深度和广度。加入我,一起学习、成长,塑造技术的未来!
在生成数据集后,需要对数据集进行检查和清洗,确保数据的质量。例如,检查是否存在空值、重复数据等问题。同时,将数据集上传到服务器的指定路径,例如 /root/autodl-tmp/datasets/trainTest.json。
三、模型微调
1. 微调命令
微调模型的命令如下:
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model /root/autodl-tmp/Qwen2.5-7B-Instruct \
--train_type lora \
--dataset /root/autodl-tmp/datasets/trainTest.json#500 \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--system 'You are a helpful assistant.' \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--model_author swift \
--model_name swift-robot
2. 参数说明
CUDA_VISIBLE_DEVICES=0:设置环境变量,指定仅使用编号为 0 的 GPU。在多 GPU 服务器中,可以通过修改这个值来选择不同的 GPU 进行训练。swift sft:执行 Swift for TensorFlow(SFT)的命令行工具,用于微调模型。SFT 是 Swift 框架中专门用于模型微调的功能模块。--model /root/autodl-tmp/Qwen2.5-7B-Instruct:指定微调使用的模型文件路径。确保路径指向之前下载的模型文件所在目录。--train_type lora:指定微调类型为 LoRA(Low-Rank Adaptation),这是一种参数高效的微调方法。LoRA 通过在模型的线性层中引入低秩矩阵来减少可训练参数的数量,从而在不显著增加计算成本的情况下实现模型的微调。--dataset /root/autodl-tmp/datasets/trainTest.json#500:指定训练数据集及其大小。数据集后面跟的数字500表示使用的数据量为 500 条记录。如果数据集较大,可以根据实际情况调整这个数值。--torch_dtype bfloat16:设置 PyTorch 的数据类型为bfloat16,这是一种较新的浮点数格式,旨在提供更好的精度和性能。bfloat16在保持一定精度的同时,能够减少内存占用和计算量,提高训练效率。--num_train_epochs 1:设置训练的总轮数(Epochs)。一个 Epoch 表示将整个数据集完整地训练一次。根据数据集的大小和模型的复杂度,可以调整这个参数来控制训练的程度。--per_device_train_batch_size 1:设置每个设备上训练时的批次大小。批次大小是指在一次迭代中同时处理的样本数量。较小的批次大小可以增加训练的随机性,但可能会导致训练速度变慢;较大的批次大小可以提高训练速度,但可能会占用更多的内存。--per_device_eval_batch_size 1:设置每个设备上评估时的批次大小。评估批次大小通常可以与训练批次大小相同,但在某些情况下,为了提高评估的准确性,可以适当增大评估批次大小。--learning_rate 1e-4:设置学习率。学习率控制了模型参数更新的步长。过大的学习率可能会导致模型无法收敛,而过小的学习率会使训练过程变得非常缓慢。可以通过实验来选择合适的学习率。--lora_rank 8:设置 LoRA 微调中的秩(rank),控制微调参数的数量。秩越小,可训练的参数越少,计算成本越低;秩越大,可训练的参数越多,模型的表达能力越强。--lora_alpha 32:设置 LoRA 微调中的 alpha 值,与秩一起影响微调参数的分布。alpha 值越大,LoRA 模块对模型的影响越大。--target_modules all-linear:指定目标模块为所有线性层。在 LoRA 微调中,只对指定的目标模块进行参数更新。--gradient_accumulation_steps 16:设置梯度累积的步数。梯度累积是一种在有限内存下模拟大批次训练的方法。通过多次前向传播和反向传播,累积梯度,然后在指定的步数后进行一次参数更新。--eval_steps 50:设置评估的步数。每训练 50 步,对模型进行一次评估,以监控模型的性能变化。--save_steps 50:设置保存模型的步数。每训练 50 步,保存一次模型的权重文件,以便在训练过程中出现问题时可以恢复到之前的状态。--save_total_limit 2:设置保存模型文件的总限制。最多保存 2 个模型权重文件,避免占用过多的磁盘空间。--logging_steps 5:设置日志记录的步数。每训练 5 步,记录一次训练日志,包括损失值、学习率等信息,方便观察训练过程。--max_length 2048:设置最大序列长度。在处理文本数据时,超过这个长度的序列将被截断。--output_dir output:设置输出目录。训练过程中生成的模型权重文件、日志文件等将保存到这个目录下。--system 'You are a helpful assistant.':设置系统提示,用于指导模型的行为。在推理过程中,模型会根据这个提示来生成回答。--warmup_ratio 0.05:设置预热比例,这是学习率预热策略中的一个参数。在训练开始的前 5% 的步数内,逐渐增大学习率,有助于模型更好地收敛。--dataloader_num_workers 4:设置数据加载器的工作线程数。增加工作线程数可以提高数据加载的速度,但也会占用更多的系统资源。--model_author swift:设置模型的作者。--model_name swift-robot:设置模型的名称。
3. 微调过程与结果
执行上述微调命令后,模型将开始进行微调训练。训练过程可能需要几分钟到数小时不等,具体时间取决于数据集的大小、模型的复杂度和硬件资源。在训练过程中,可以通过日志文件查看训练的进度和性能指标,如损失值、准确率等。
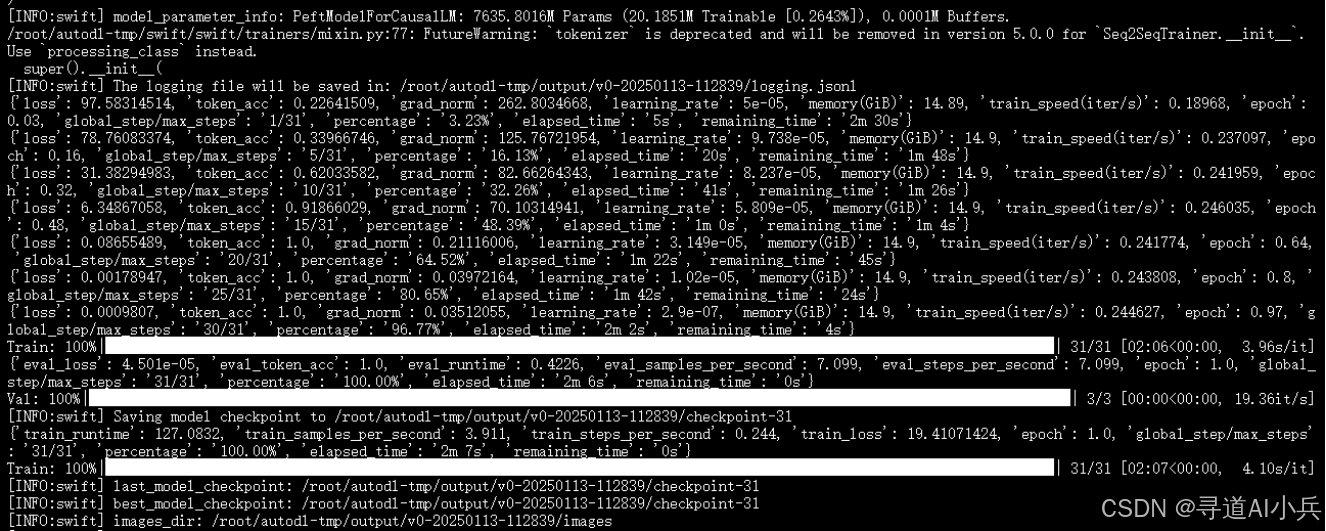
微调结束后,可以查看到生成的权重文件,例如 /root/autodl-tmp/output/v0-20250113-112839/checkpoint-31。这些权重文件包含了微调后的模型参数,可以用于后续的推理任务。
四、推理微调后权重文件
1. 模型命令
训练完成后,使用以下命令对经过训练的权重执行推理。应将 --adapters 选项替换为从训练生成的最后一个检查点文件夹。由于 adapters 文件夹包含来自训练的参数文件,因此无需单独指定 --model 或 --system。
# 使用交互式命令行进行推理。
# 设置CUDA_VISIBLE_DEVICES环境变量为0,指定使用GPU 0。
# swift infer是推理命令,用于启动推理过程。
# --adapters指定模型检查点的路径。
# --stream设置为true,表示推理过程中数据流是连续的。
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters /root/autodl-tmp/output/v0-20250113-112839/checkpoint-31 \
--stream true
2. 推理测试
执行上述命令后,进入交互式命令行界面。输入一些测试问题,观察模型的响应。与微调前的模型相比,微调后的模型应该能够更好地回答与自定义数据集相关的问题。例如,对于关于“寻道AI小兵”的问题,模型的回答应该更加准确和详细。
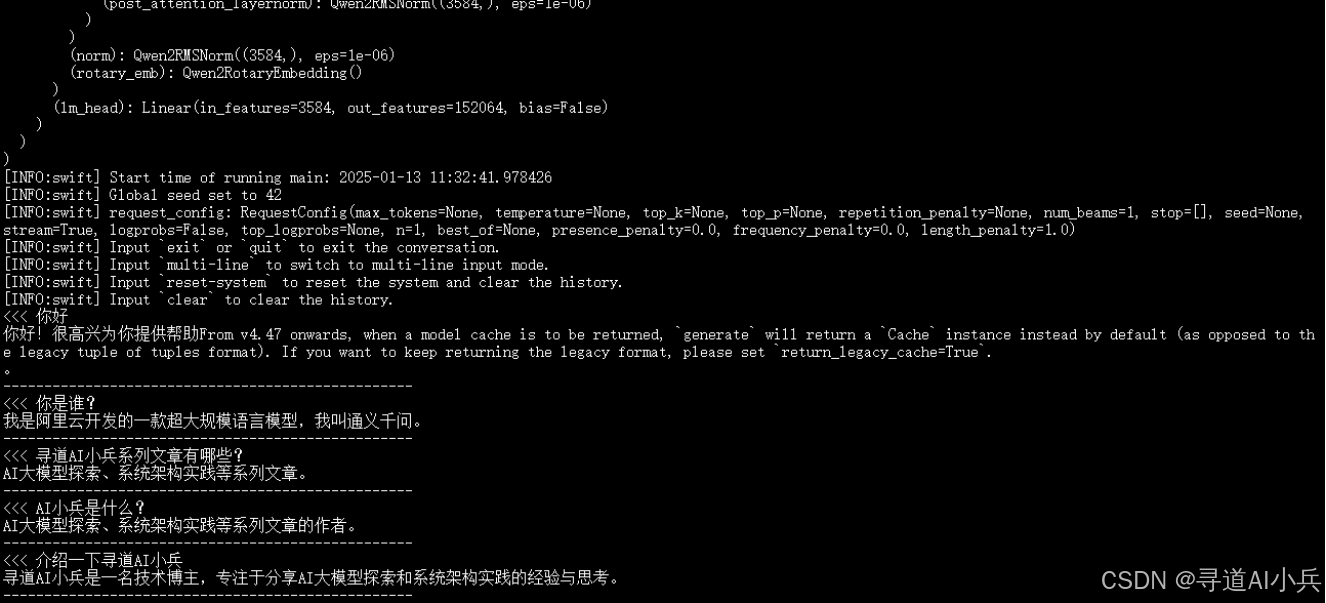
3. 资源消耗
在推理过程中,记录资源消耗情况,包括 GPU 使用率、内存占用等。可以使用 nvidia-smi 命令查看 GPU 的使用情况,使用 top 或 htop 命令查看系统的内存和 CPU 使用情况。通过分析资源消耗,评估微调后模型的推理性能和资源需求,为后续的部署提供参考。
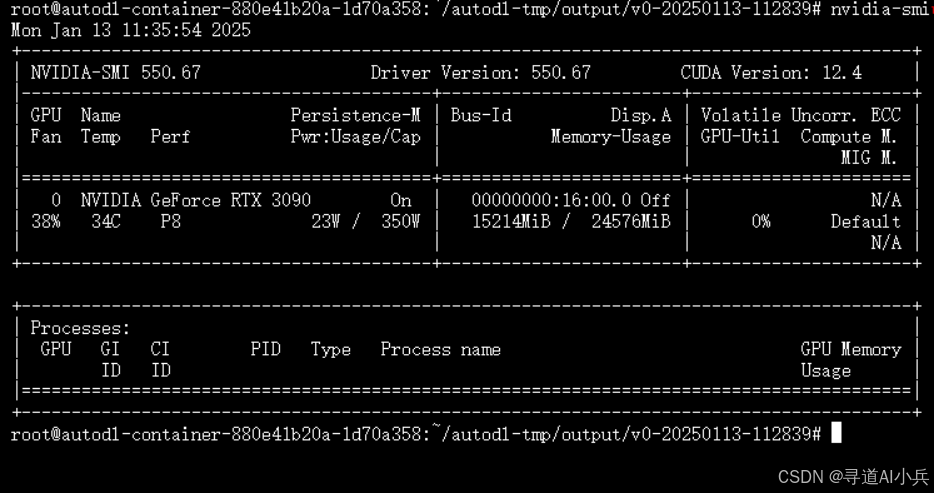
五、模型合并&推理
1. 合并与加速推理
合并 LoRA(Low-Rank Adaptation)并使用 vLLM(Vectorized Longformer Large Models)进行推理加速。以下是具体的推理命令:
# CUDA_VISIBLE_DEVICES环境变量同样设置为0,指定使用GPU 0。
# swift infer是推理命令,用于启动推理过程。
# --adapters指定模型检查点的路径。
# --stream设置为true,表示推理过程中数据流是连续的。
# --merge_lora设置为true,表示合并LoRA模型,这是一种模型压缩技术,可以减少模型大小同时保持性能。
# --infer_backend设置为vllm,表示使用vLLM作为推理后端,这是一种优化的推理引擎,可以加速长文本模型的推理过程。
# --max_model_len设置为8192,表示模型的最大长度限制为8192个token。
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/v0-20250113-112839/checkpoint-31 \
--stream true \
--merge_lora true \
--infer_backend vllm \
--max_model_len 8192
2. 推理命令执行与结果
执行上述命令后,模型将使用合并后的权重进行推理。在推理过程中,输入一些测试问题,观察模型的响应速度和质量。由于使用了 vLLM 推理后端,模型的推理速度应该会有明显的提升,特别是对于长文本的处理。
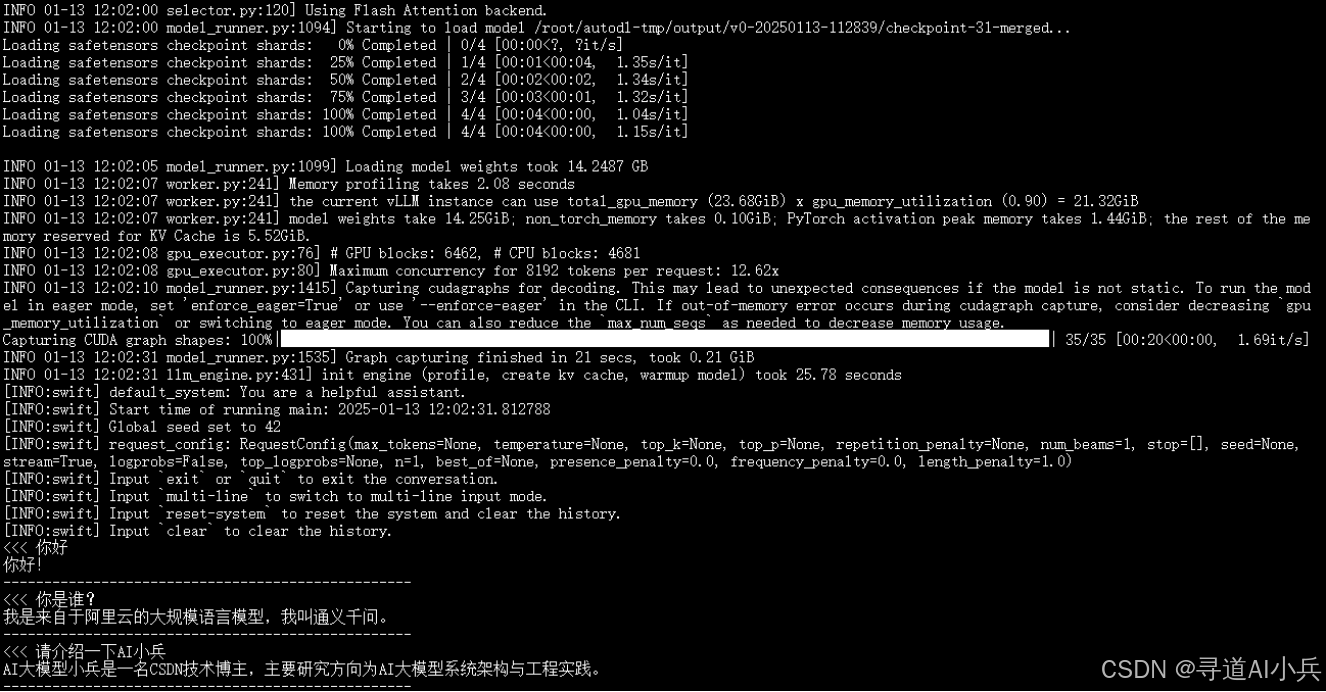
3. 合并后的权重文件
合并后的权重文件将保存到指定的路径,例如 /root/autodl-tmp/output/v0-20250113-112839/checkpoint-31-merged。这个权重文件包含了合并后的模型参数,可以用于后续的部署和应用。
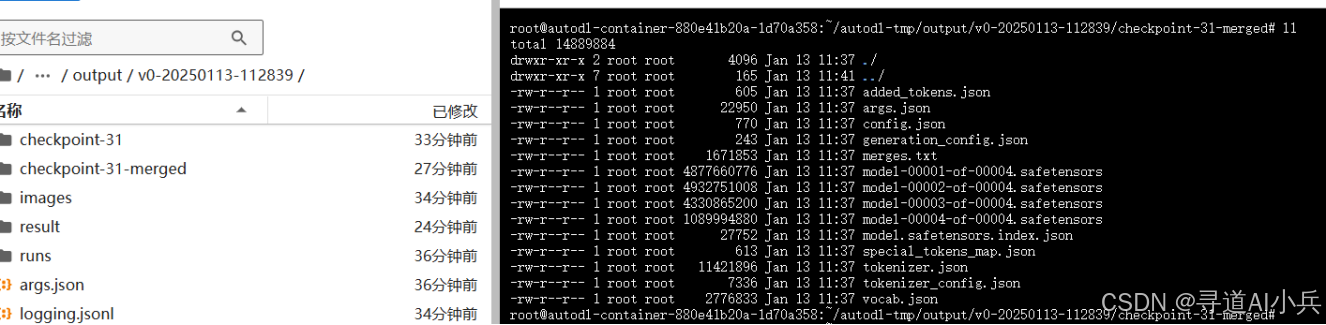
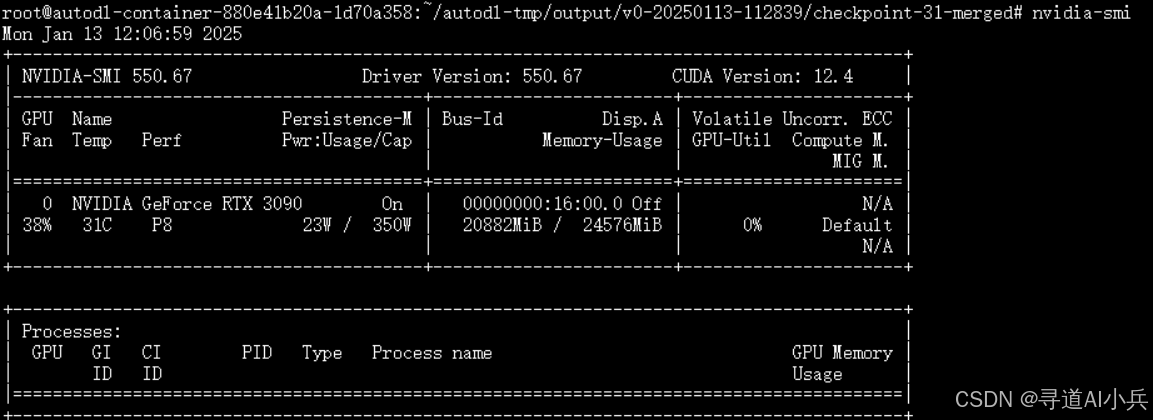
4. 资源消耗
同样,在合并和推理过程中,记录资源消耗情况,包括 GPU 使用率、内存占用等。对比合并前后的资源消耗和推理性能,评估模型合并和使用 vLLM 推理后端的效果。
结语
通过本实战指南,我们详细介绍了如何使用 Swift 框架对自定义数据集进行微调,从模型准备、数据集准备,到模型微调、推理,再到模型合并与加速推理,完成了整个微调流程。通过对自定义数据集的微调,模型能够更好地适应特定场景的需求,提高回答的准确性和相关性。同时,通过合并 LoRA 模型和使用 vLLM 推理后端,可以进一步提升模型的推理性能和效率。希望本指南能够帮助你更好地利用 Swift 框架进行模型微调,推动你的 AI 项目取得更好的成果。在实际应用中,你可以根据具体需求调整微调参数和数据集,不断优化模型的性能。如果你在实践过程中遇到任何问题,可以查阅 Swift 框架的官方文档或寻求社区的帮助。

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!



















 1558
1558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











