






数据简介
今天我们分享的数据是观鸟数据集,该数据整理中国观鸟记录中心的鸟类报告数据,在2024年获取了该网站种鸟类的报告信息,详情信息以及鸟种信息,分别整理为各省的数据,方便大家研究使用,方便大家研究使用。
该数据集涵盖中国各省鸟类报告信息,可用于分析鸟类分布规律、迁徙路线与生态环境关联等,助力生态保护研究。同时服务于生物多样性研究、环境变化监测,为制定针对性保护措施提供依据,推动相关科研与实践发展。
数据详情
数据来源:中国观鸟记录中心
数据时间:1980-2024
数据范围:中国各省
数据格式:csv
数据概览
该数据集分三种文件夹存储,其中各文件夹内数据的指标分别是:
报告
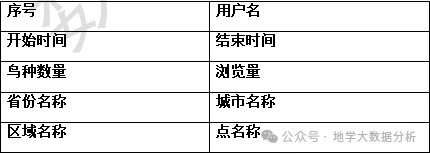
详情
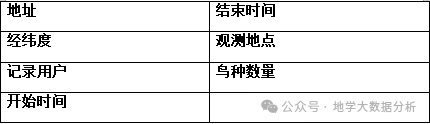
鸟种
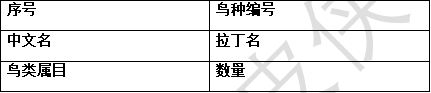
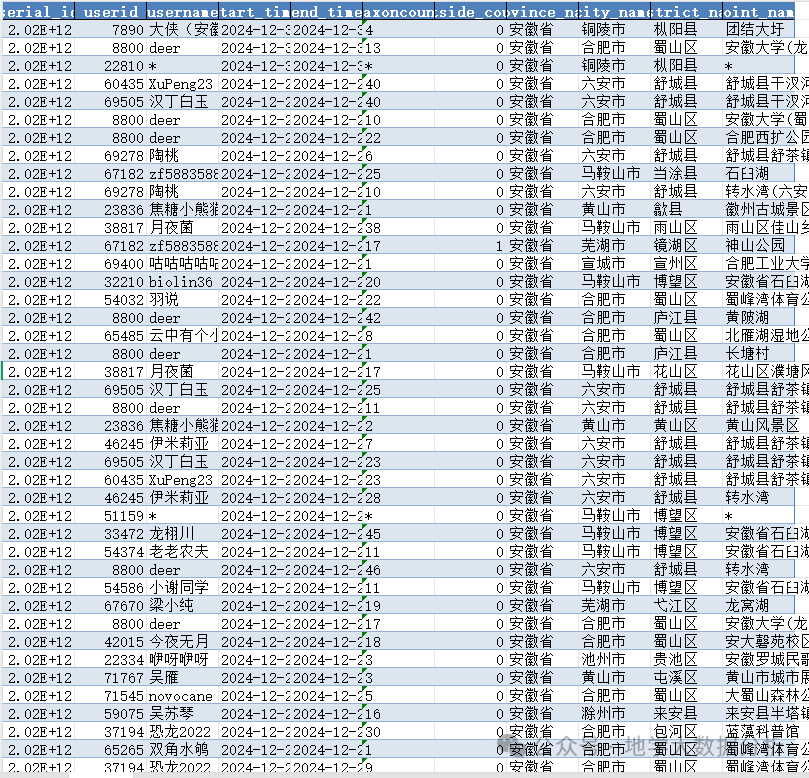
数据概览如下:
参考文献
[1]Meng L, Liu P, Zhou Y, et al. Blaming the wind? The impact of wind turbine on bird biodiversity[J]. Journal of Development Economics, 2025, 172: 103402.

















 3591
3591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









