







一、认识ResNet
ResNet(Residual Network)是一种深度神经网络结构,被广泛应用于图像分类、目标检测和语义分割等计算机视觉任务中。它是由微软亚洲研究院的何凯明等人于2015年提出的,通过引入残差连接(residual connections)解决了深层网络训练过程中的梯度消失和梯度爆炸问题,有效地加深了网络的深度。
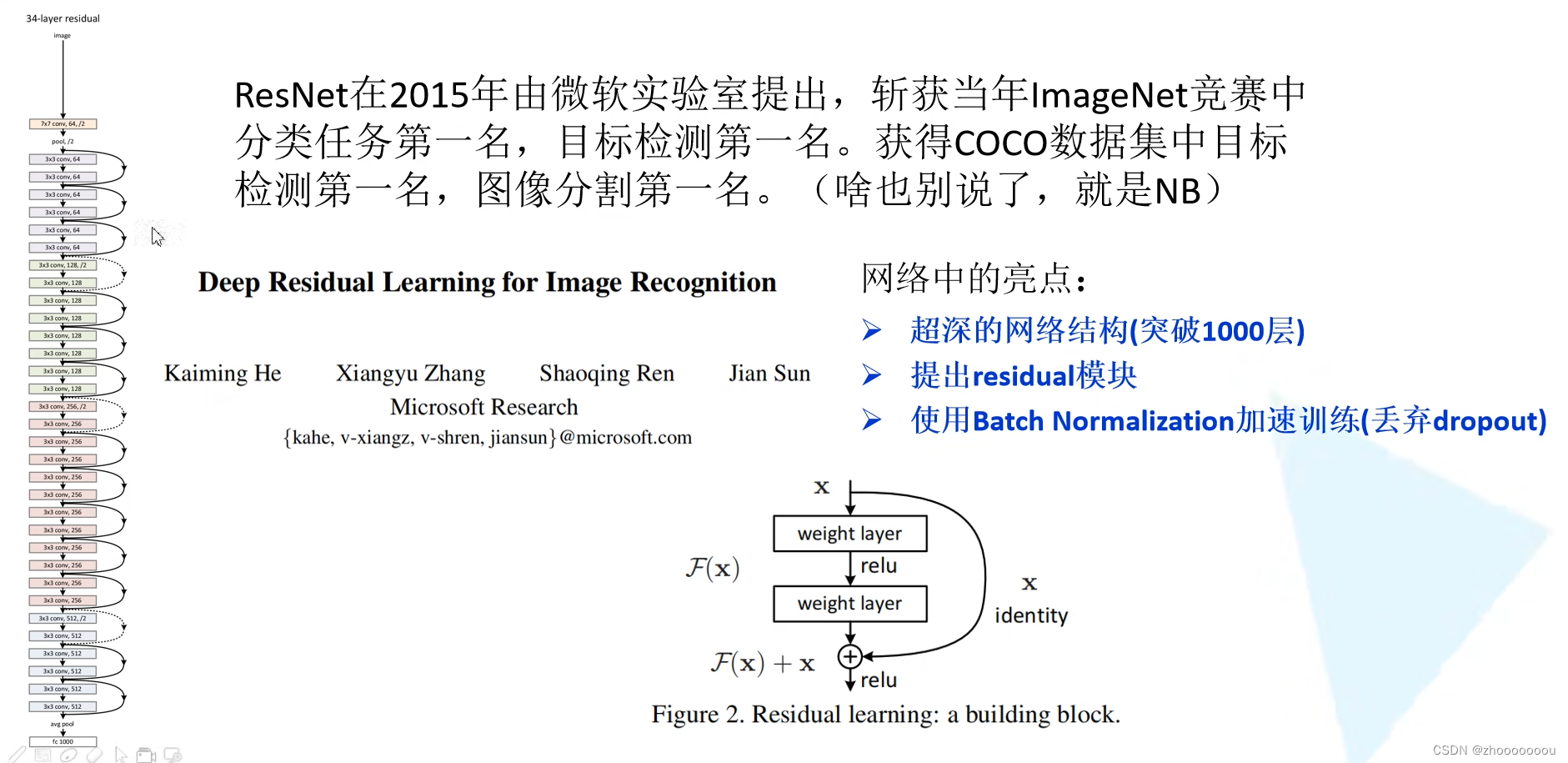
网络亮点
1、超深的网络结构(突破1000层)
其他网络比如VGG。GoogleNet、AlexNet深度也就在十几层到二十几层。
如果将一系列的卷积和池化不断叠加,也能得到一个超深的网络。但是数据结果表明不是层数越深结果越好。
左边图中是将卷积层和池化层进行简单的堆叠所搭建的网络结构。橙黄色表示是20层网络结构所训练出来的效果,红色的线表示56层网络结构训练出来的效果,很明显可以看出20层的比56层结构所训练出来的效果要好很多。
造成这样的层数加深,训练效果变差的原因是什么呢?
==》1、随着网络的层数不断加深,梯度消失或者梯度爆炸这个现象会越来越明显。
梯度消失:假设每一层的误差梯度是小于1的数,在反向传播过程中,每向前传播一次,都要乘一个小于1的系数,当网络越来越深的时候,乘的小于1的系数越多就越趋近于0,这样梯度会越来越小,这就是常说的梯度消失现象。
梯度爆炸:反之,如果每一层的梯度是一个大于1的数,在反向传播过程中,每经过一层都要乘一个大于1的数,随着层数不断加深,那么梯度就会越来越大,这就是梯度爆炸。
梯度消失和梯度爆炸怎么解决?
对数据进行标准化处理、权重初始化、batch normalization
==》2、退化问题(degradation problem)
在resnet网络中提出了残差的结构,可以很好解决退化问题。
右图就是resnet所搭建的一些网络,有20层、32层、44层、56层、110层,实线代表验证集的错误率虚线代表训练集的错误率。
通过看验证集中的数据显示层数越深,错误率越小,模型效果是越好的。

那我们就可以使用残差结构来不断加深网络,以获得一个更好的结果。
2、提出residual(残差)模块
左边图中主要针对网络层数较少的网络所使用的残差结构
右边图中的残差结构主要针对50层、101层、152层提出的。
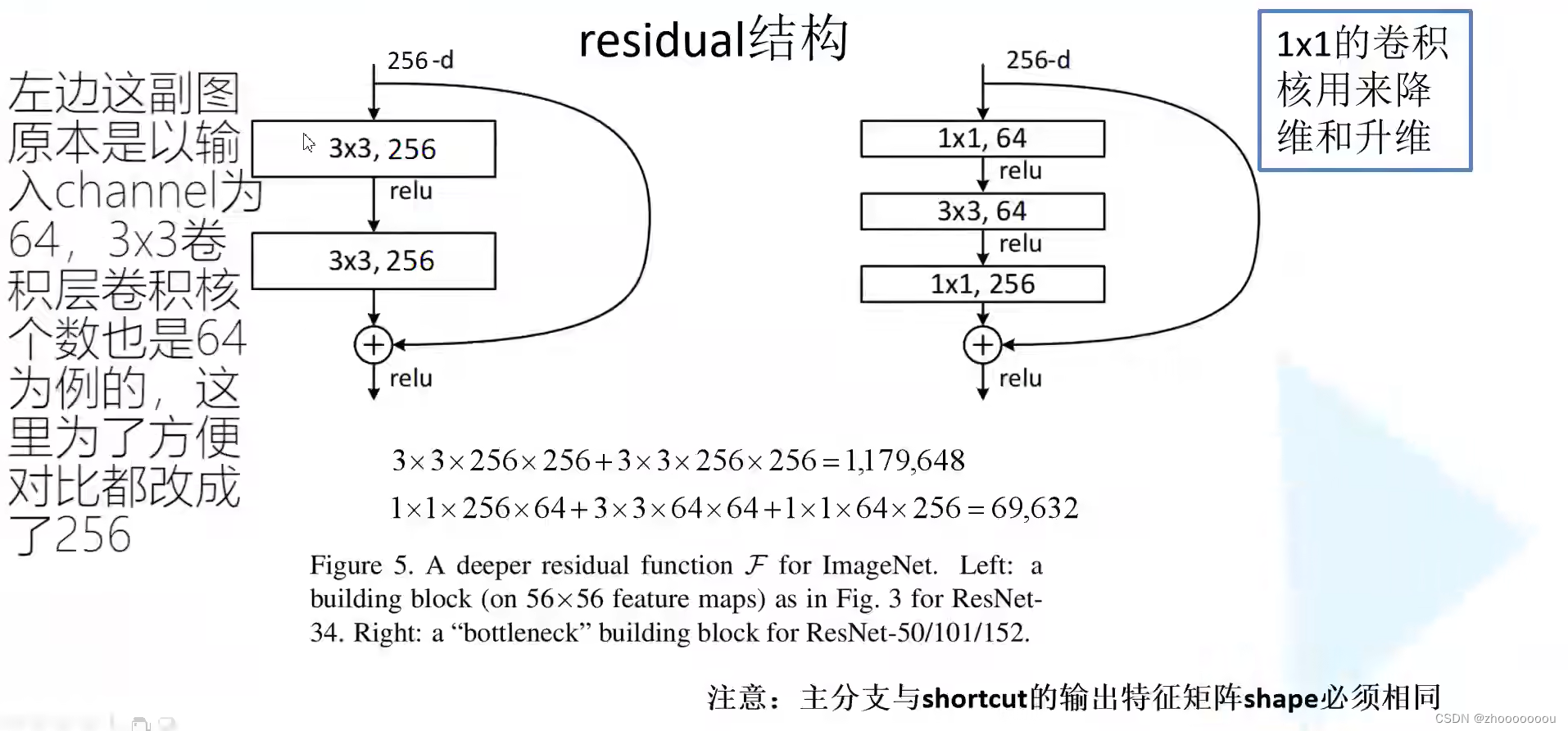
左边图中:
使用两个3x3的卷积层得到一个结果,主线上经过一系列卷积层后所得到的特征矩阵再与输入特征矩阵进行相加,相加之后再通过relu激活函数得到结果。
注意:主分支与shortcut(捷径)的输出特征矩阵shape必须相同(在高度、宽度、深度)三个维度都要相同,这样才可以保证两个特征矩阵在相同的维度进行参数的累加。
右边图中:
比左边图中在输入输出上多加了两个1x1的卷积层。第一个1x1卷积层主要是用来降维,将输入的256维的卷积层降维到64维(高度、宽度不变),第二个1x1卷积层主要是用来升维,将输出变为256维,以此实现与输入特征矩阵的shape相同,然后进行相加。
参数数目 = 长 x 宽 x 输入通道数 x 卷积核个数
上面的式子是没有进行降维所需要的参数,下面的式子是使用了降维所需要的参数。很明显经过降维后所需要的参数大大降低。

在实现网络时,使用一系列的残差结构进行堆叠,使用的残差越多,那么节省的所需要参数也就越多
3、使用batch normalization加速训练(丢弃dropout)
batch normalization的目的是使我们的一批数据所对应的feature map(每个channel所对应的维度)都满足均值为0,方差为1的分布规律。
二、34层网络结构详解
论文中给出的18层、34层、50层、101层、152层网络的搭建。给出的这几个网络整个网络的框架是基本上类似的。

注意:浅层结构(18层、34层) 的conv2不需要虚线残差结构,因为输出与下一层的输入正好一样,而深层结构(50层、101层、152层)的conv2需要进行虚线残差结构,以保证输出与期望的输入维度相同。
以34层网络结构为例:
首先是7x7的卷积层
第二层是 3x3 的最大池化下采样。
将残差结构分为 conv2_x、conv3_x、conv4_x、conv5_x 这四部分的一系列结构。表格中的个数表示了有几个残差结构



图中实线残差结构与虚线残差结构的区别
实线残差结构:因为输入特征矩阵与输出特征矩阵的shape是一模一样的,所以可以直接进行相加
虚线残差结构:输入输出特征矩阵shape不同。虚线处高宽减半,通道数加倍。
右边图中对应的 conv3_x的输入矩阵为 56 x 56 x 64,而输出矩阵为 28 x 28 x 128,通过虚线残差结构得到输出后,再将输出输入到实线残差结构中,才能保证他的输入特征矩阵与输出特征矩阵的shape是相同的。
实线与虚线残差结构的不同之处:
1、第一个3 x 3的卷积层,步距stride变为了2 ,将高和宽缩减为原来的一半,通过128个卷积核改变特征矩阵的深度。
2、shortcut部分加上了1x1的卷积核,通过步距为2,高和宽缩减为原来的一半,通过128个卷积核改变特征矩阵的深度,这样保证主分支与shortcut分支的shape一样,从而进行相加。

对于更深层的网络
右边图中对应的 conv3_x的输入矩阵为 56 x 56 x 256,而输出矩阵为 28 x 28 x 512.
在主线上:通过 1x1,128的卷积层进行降维,将深度由256降到128,不改变高和宽。
第二个3x3的卷积层,stride为2将高和宽缩减为原来的一半,变成28x28x128.
第三个1x1,512的卷积层,进行升维,增加深度,变为28x28x512
shortcut 采用 1x1,512,stride=2的卷积层将高和宽减半,深度变为原来的2倍。

后续继续补充。。。














 127
127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









