






 本文详细介绍了搜索算法中的暴力搜索、深度优先搜索(DFS)及其优化,包括广度优先搜索(BFS)的应用,以及树型数据结构如倍增和并查集在搜索优化中的作用。通过实例演示和优化策略,展示了如何提升算法性能并解决实际问题。
本文详细介绍了搜索算法中的暴力搜索、深度优先搜索(DFS)及其优化,包括广度优先搜索(BFS)的应用,以及树型数据结构如倍增和并查集在搜索优化中的作用。通过实例演示和优化策略,展示了如何提升算法性能并解决实际问题。
搜索
前言:搜索是算法中的一个大分类,它包含许许多多的算法,例如枚举、深度优先搜索、启发式搜索等;
一、暴力搜索
暴力搜索一般会被用来骗分(不到万不得已不要骗分),这种搜索很容易就能写出来,是所有搜索的基础,任何搜索算法都是由暴力搜索衍生出来的,甚至某些数据结构也是由搜索算法衍生出来的;
由于暴力算法过于简单,这里不过多赘述;
二、深度优先搜索(DFS)
深度优先搜索(DFS)是一种递归类搜索,利用系统栈来实现搜索,原理如下:
1.判断当前节点是否有连接其他未被访问过的节点的边,如果有边,递归下去,否则,回溯到上一节点,继续判断;
2.判断是否满足条件,如果是,直接返回,否则,继续遍历;
3.判断是否有必要继续遍历下去,即剪枝(后面会讲到);
例题:
这道题既可以用深度优先搜索,也可以用**广度优先搜索(BFS,后面会讲到)**来做;
这里只出示深度优先搜索的思路及代码;
首先可以从题目知道一件事——每一个节点最多可以连接到两个节点,这样我们就可以构造出一棵搜索树(可以理解为一棵包含所有的深度优先搜索步骤的树),也就可以写出如下代码:
#include <bits/stdc++.h>
using namespace std;
#define INF 2147483647
int length, a_start, a_end;
int a[207];
int ans = INF;
void dfs(int node, int step){
if(node == a_end){
ans = min(ans, step);
return;
}
if(node + a[node] <= length){
dfs(node + a[node], step + 1);
}
if(node - a[node] >= 1){
dfs(node - a[node], step + 1);
}
}
int main(){
cin >> length >> a_start >> a_end;
for(int i = 1; i <= length; i++){
cin >> a[i];
}
dfs(a_start, 0);
cout << (ans == INF ? -1 : ans);
return 0;
}
但这份代码有一个严重的漏洞——会重复遍历同一个节点,这个漏洞导致了提交到洛谷上只有 12 分 M e m o r y L i m i t E x c e e d e d \mathrm{\color{orangered} 12分 \ Memory \ Limit \ Exceeded} 12分 Memory Limit Exceeded;
我们可以加入visit数组来记录是否经过这个节点,这样就可以写出如下代码:
#include <bits/stdc++.h>
using namespace std;
#define INF 2147483647
int length, a_start, a_end;
int a[207];
int visit[207];
int ans = INF;
void dfs(int node, int step){
if(step >= ans) return; // 优化
if(node == a_end){
ans = step;
return;
}
visit[node] = 1; // 递归
if(node + a[node] <= length && !visit[node + a[node]]){
dfs(node + a[node], step + 1);
}
if(node - a[node] >= 1 && !visit[node - a[node]]){
dfs(node - a[node], step + 1);
}
visit[node] = 0; // 回溯
}
int main(){
cin >> length >> a_start >> a_end;
for(int i = 1; i <= length; i++){
cin >> a[i];
}
dfs(a_start, 0);
cout << (ans == INF ? -1 : ans);
return 0;
}
这样我们就得到了一份 64 分 T i m e L i m i t E x c e e d e d \mathrm{\color{blue}64分 \ Time \ Limit \ Exceeded} 64分 Time Limit Exceeded的代码,那为什么只有64分呢?
因为这份代码里有许多没有必要的搜索过程:当你搜索到一个节点时,如果你当前的step值已经大于等于以前搜索到着的最小值,那么就没有必要搜下去了,因为无论你怎么搜,都不可能是最优解,所以就有了如下代码:
#include <bits/stdc++.h>
using namespace std;
#define INF 0x3f3f3f3f
#define Byte_INF 0x3f
int length, a_start, a_end;
int a[207];
int ans[207];
void dfs(int node, int step){
if(step >= ans[node]) return; // 优化
ans[node] = step;
if(node == a_end){
return;
}
if(node + a[node] <= length){
dfs(node + a[node], step + 1);
}
if(node - a[node] >= 1){
dfs(node - a[node], step + 1);
}
}
int main(){
cin >> length >> a_start >> a_end;
for(int i = 1; i <= length; i++){
cin >> a[i];
}
memset(ans, Byte_INF, sizeof(ans));
dfs(a_start, 0);
cout << (ans[a_end] == INF ? -1 : ans[a_end]);
return 0;
}
这样我们就 100 分 A c c e p t e d \mathrm{\color{green}100分 \ Accepted} 100分 Accepted了;
三、广度优先搜索(BFS)
先来看一道题目:luogu P2895 [USACO08FEB] Meteor Shower S;
观察题目,不难看出,这道题目是标准的搜索,所以,让我们用上一章的DFS来套一套吧;
但这样会有一个非常致命的问题,超时,为什么呢?
注意看 X i X_i Xi和 Y i Y_i Yi的范围,一次遍历最差会有 X i ⋅ Y i X_i \cdot Y_i Xi⋅Yi次节点访问,而遍历这 X i ⋅ Y i X_i \cdot Y_i Xi⋅Yi个节点需要 O ( 2 X i ⋅ Y i ) O(2^{X_i \cdot Y_i}) O(2Xi⋅Yi)的时间复杂度,而且 X i ⋅ Y i = 9 × 1 0 4 X_i \cdot Y_i = 9 \times 10^4 Xi⋅Yi=9×104,远大于计算机1s所能运行的次数(约 2 27 2^{27} 227);
注:这里暂时不考虑优化,后面也会说明如何用DFS写;
那该如何解呢?
如果我们用一个队列queue1去存储所有的搜索结果,我们就得到了广度优先搜索(BFS),那它有什么用呢?
设想一个有十分大(或者无限)的地图,要求你求最短路(后面会讲到),这时候你就可以用BFS了;
再看这道题,如果用BFS,再注意下细节,就可以很轻松的AC了;
注:代码暂略,后面可能会补上;
四、树型数据结构及算法(拓展)
注:这里不再赘述二叉树(binary_tree)的内容了,只是拓展一下;
严格来讲,树的遍历不完全算是搜索,它是属于树的一个基础知识,但毕竟跟搜索也沾点边,就也讲一下了;
拓展1:倍增;
倍增实际上是一种对单一方向且搜索方向上无分支的快速遍历,常用的算法是最近公共祖先(LCA);
首先,先了解一下倍增的算法过程;
倍增是一个预处理,将被倍增的数组中的所有节点的前/后第1、2、4、8……个节点都存起来,这样访问的速度就可以达到 O ( log 2 n ) O( \log_2 n) O(log2n)了;
在树上应用时可以很方便的遍历;
拓展2:并查集;
并查集是属于集合一类的,但由于它的结构与树类似,所以也放在这里了;
并查集是一个处理一个点的某个关系链接的唯一点一类的问题十分高效的数据结构,一般用于处理**强连通分量个数(图论,后面会讲到)**之类的问题;
并查集分为基础的并查集,多棵树的并查集,带权并查集,其中,基础的和有多棵树的并查集代码类似,只是根的数量不同,带权并查集这里先不讲,因为要涉及到图论中的权值;
并查集的原理十分简单,就是开一个数组,将每个节点的父亲记录下来就行,代码如下:
int fa[Length]; // 父节点
int a[Length]; // 节点信息
int find(int x){ // 找根
return (fa[x] == x ? x : find(fa[x])); // 简写,意义:该节点点如果是根,则返回,否则继续递归到它的父节点
}
int add(int x, int y){ // 将y设为x的子节点
int fx = find(x), fy = find(y);
if(fx != fy){
fa[y] = fx;
}
}
但是find()函数有点慢,怎样提高它的速度呢?这时候就用到一个并查集的一个十分重要的操作——路径压缩,路径压缩,顾名思义,其本质就是将节点直接接到根上,这样就可以压缩时间复杂度了,代码如下:
#include <bits/stdc++.h>
using namespace std;
int fa[Length]; // 父节点
int a[Length]; // 节点信息
int find(int x){ // 找根
return (fa[x] == x ? x : fa[x] = find(fa[x])); // 简写,意义:该节点点如果是根,则返回,否则继续递归到它的父节点,并将它的父节点更新成find(fa[x])的返回值,也就是根节点
}
int add(int x, int y){ // 将y设为x的子节点
int fx = find(x), fy = find(y);
if(fx != fy){
fa[y] = fx;
}
}
int main(){
return 0;
}
注意:不是所有题目都能用路径压缩的,要根据实际情况选择;
并查集的应用十分广泛,很多地方都应用到它,比如求一些包含问题,求根节点的问题等等,建议多练习;
新手建议练P3367(模板)
五、搜索优化
本节只讲DFS的优化,其他算法的优化后面讲到时会顺便讲;
第三节时我们提到了搜索优化,这一节就专门讲关于优化的内容;
搜索优化就是将时空复杂度降低一些,可能是降低常数,也可能是降低理论复杂度,比如上一节的并查集find()函数的修改就是优化;
理论复杂度是指将算法复杂度降低一个层次,比如 O ( n 4 ) O(n^4) O(n4)降到 O ( n 3 ) O(n^3) O(n3)就是降低复杂度,但要注意,理论复杂度终究是理论,也要注意常数;
补充:复杂度对比
不是说指数复杂度就一定比多项式复杂度时间长的,比如
O
(
2
n
)
O(2^n)
O(2n)和
O
(
n
4
)
O(n^4)
O(n4):

但超过65536后, O ( 2 n ) O(2^n) O(2n)会再次超过 O ( n 4 ) O(n^4) O(n4):
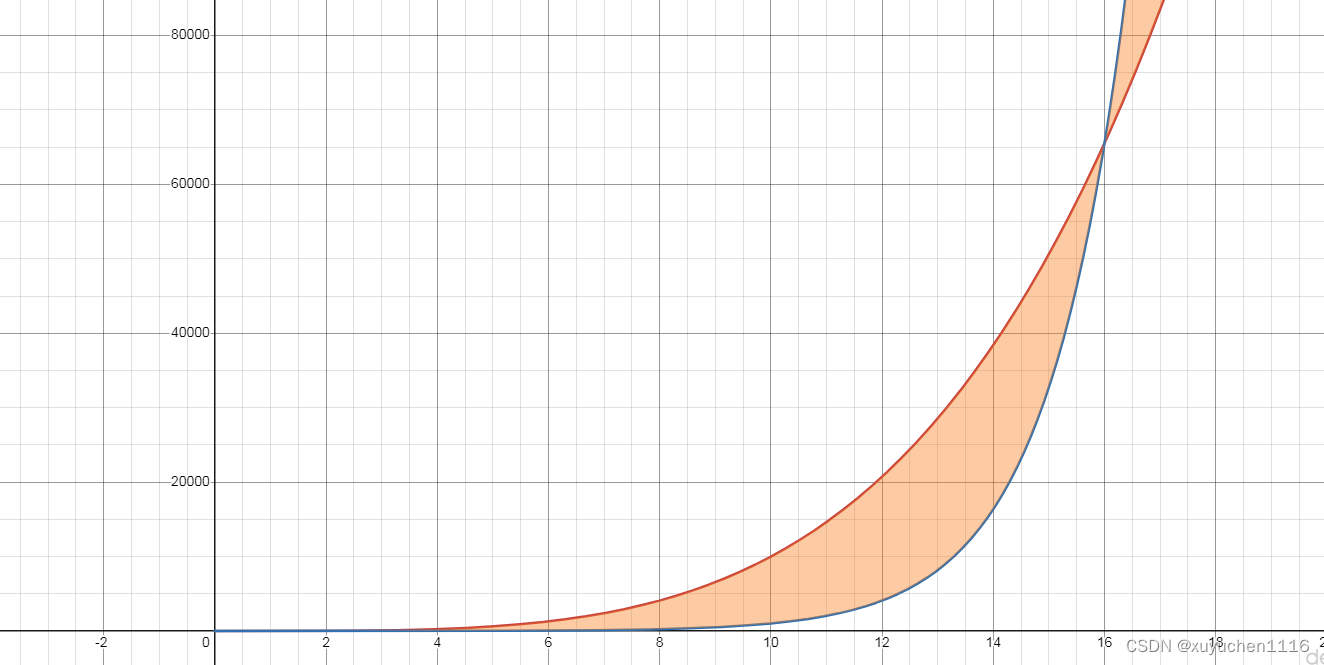
一般情况多项式会更优;
讲完了算法复杂度,接下来就是如何优化了;
再看P2895,如何用DFS写?
- 思考1:
如果将不必要的搜索剪掉(剪枝),那么就可以大幅度地减少复杂度了,但这样还是不能AC,那怎么办? - 思考2:
如果将所有节点地最短路都预处理出来,这样不就可以将复杂度降到多项式了吗?我们就可以愉快地AC了;
未完结,后面几节会写到(二)里面;















 885
885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









