






数据集加载
下载数据集,并且实现加载
# Download data from open datasets
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
train_dataset = MnistDataset("MNIST_Data/train", shuffle=False)
print(type(train_dataset))
数据集迭代 /预处理
意义:
数据访问:迭代器提供了一种顺序访问数据集元素的方式,无需加载整个数据集到内存中,尤其对于大型数据集,这种方式更加高效。
批处理:迭代器可以逐批处理数据,每次处理一小部分数据,有助于优化内存使用和处理速度。这在机器学习模型训练过程中尤为重要。
数据预处理:在迭代过程中,可以对数据进行预处理操作,如归一化、增强、转换等,以确保数据在使用前符合预期格式和标准。
可视化和验证:通过迭代,可以方便地抽取样本数据进行可视化和验证。这有助于检查数据是否符合预期,是否存在异常值,标签是否正确等。
简化代码:使用迭代器可以简化代码结构,避免显式的索引操作,使代码更清晰、更易维护。
延迟加载:迭代器支持延迟加载数据,仅在需要时加载数据,减少初始加载时间和内存占用,提高效率。
create_tuple_iterator 或 create_dict_iterator接口创建数据迭代器,,迭代访问数据。访问的数据类型默认为Tensor;若设置output_numpy=True,访问的数据类型为Numpy。
下面定义一个可视化函数,迭代9张图片进行展示。
def visualize(dataset):
figure = plt.figure(figsize=(4, 4))
cols, rows = 3, 3
plt.subplots_adjust(wspace=0.5, hspace=0.5)
for idx, (image, label) in enumerate(dataset.create_tuple_iterator()):
figure.add_subplot(rows, cols, idx + 1)
plt.title(int(label))
plt.axis("off")
plt.imshow(image.asnumpy().squeeze(), cmap="gray")
if idx == cols * rows - 1:
break
plt.show()
#这段代码定义了一个名为 visualize 的函数,用于可视化给定数据集中的图像。函数创建一个 4x4 英寸的绘图对象,并设置3行3列的子图布局,
#通过调整子图之间的间距来避免图像和标签的重叠。然后,从数据集中迭代获取图像和标签,将它们依次添加到子图中,显示对应的标签标题,
#关闭坐标轴,以灰度图形式显示图像。最多显示9个图像,一旦达到9个就停止迭代,最终展示完整的绘图。
数据集操作
1 shuffle : 指的是对数据集中的样本进行随机打乱。这样做有以下几个重要意义:
提高模型泛化能力:在训练机器学习模型时,随机打乱数据集可以避免模型在训练过程中对特定的样本顺序产生依赖,从而提高模型的泛化能力。
避免过拟合:通过打乱数据顺序,可以防止模型记住样本的顺序,从而减小过拟合的风险。这有助于模型更好地适应新数据。
平衡批次数据:在批处理数据时,打乱数据可以确保每个批次的数据分布更加均匀和多样,减少批次之间的差异,避免批次间数据分布的不均匀性导致的训练偏差。
消除数据相关性:如果数据集中的样本是有序排列的(如按时间、类别等顺序排列),直接使用有序数据进行训练可能会引入不必要的相关性,影响模型的学习效果。打乱数据顺序可以消除这种相关性。
train_dataset = train_dataset.shuffle(buffer_size=64)
visualize(train_dataset)
2 map:是数据预处理的关键操作。将一个或多个函数应用于数据集中的每个样本。这种操作有助于数据预处理、特征提取和数据增强。map 操作可以简化代码,使数据处理流水线更加清晰和易于维护。 可简单理解为——全局处理数据集,这样做有以下几个重要意义:
数据预处理:可以对数据集中的每个样本进行预处理操作,例如归一化、标准化、填补缺失值等。例如,对于图像数据,可以将每个图像像素值归一化到 [0, 1] 范围内。
特征提取:可以对数据集中的每个样本进行特征提取。例如,对于文本数据,可以将每个句子转换为其词向量表示。
数据增强:可以对数据集中的每个样本进行数据增强操作,例如图像的随机裁剪、旋转、翻转等,以增加数据的多样性,提高模型的泛化能力。
标签处理:可以对数据集中的标签进行处理,例如将标签转换为独热编码。
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype)
#输出为 (28, 28, 1) UInt8
#接下来 这里我们对Mnist数据集做数据缩放处理,将图像统一除以255,数据类型由uint8转为了float32。
train_dataset = train_dataset.map(vision.Rescale(1.0 / 255.0, 0), input_columns='image')
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype)
#输出为(28, 28, 1) Float32
3 :batch: 将数据集打包为固定大小的batch是在有限硬件资源下使用梯度下降进行模型优化的折中方法,可以保证梯度下降的随机性和优化计算量。将数据集分成多个小批次,每个批次包含一定数量的样本 这种操作在机器学习和深度学习中非常常见,主要用于训练和评估模型。将数据集分成批次有以下几个重要意义:
内存效率:在处理大数据集时,将数据集分成批次可以避免一次性加载整个数据集,从而节省内存。每次只加载和处理一个批次的数据,降低内存消耗。
计算效率:批处理能够利用现代硬件(如 GPU)的并行计算能力,加速模型训练。一次处理多个样本比逐个处理样本更加高效。
梯度估计:在模型训练中,使用批次数据来计算梯度,可以在一定程度上减少噪声,提高梯度估计的稳定性。相比于单样本梯度,批量梯度能够提供更稳定的方向,从而更好地更新模型参数。
优化过程:批量梯度下降(mini-batch gradient descent)结合了全局梯度下降和随机梯度下降的优点,既有全局收敛的特性,又能够更快地找到最优解。
train_dataset = train_dataset.batch(batch_size=32)
# batch后的数据增加一维,大小为batch_size。
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype)
#输出为 (32, 28, 28, 1) Float32
至于为什么batch_size的设置会增加一维度,我们可以讲起我们设置了一个批次,每一个批次有batch_size(32)个样本(每个样本是(28,28,1)【姑且视为长宽高吧,总之每一个维度不少!】)于是每一个处理批次就变为了 (32, 28, 28, 1) ,通过batch批次的设置,让机器去一部分一部分的迭代,从而实现任务,而不是一口气干掉工作
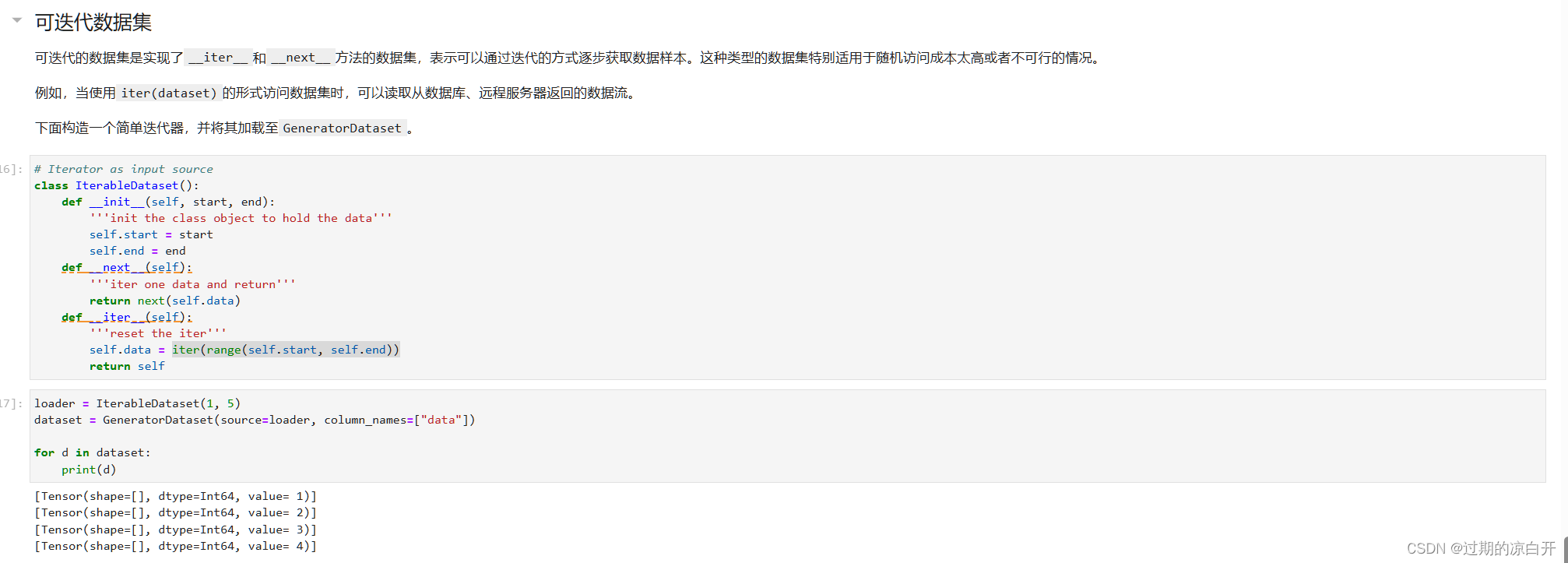
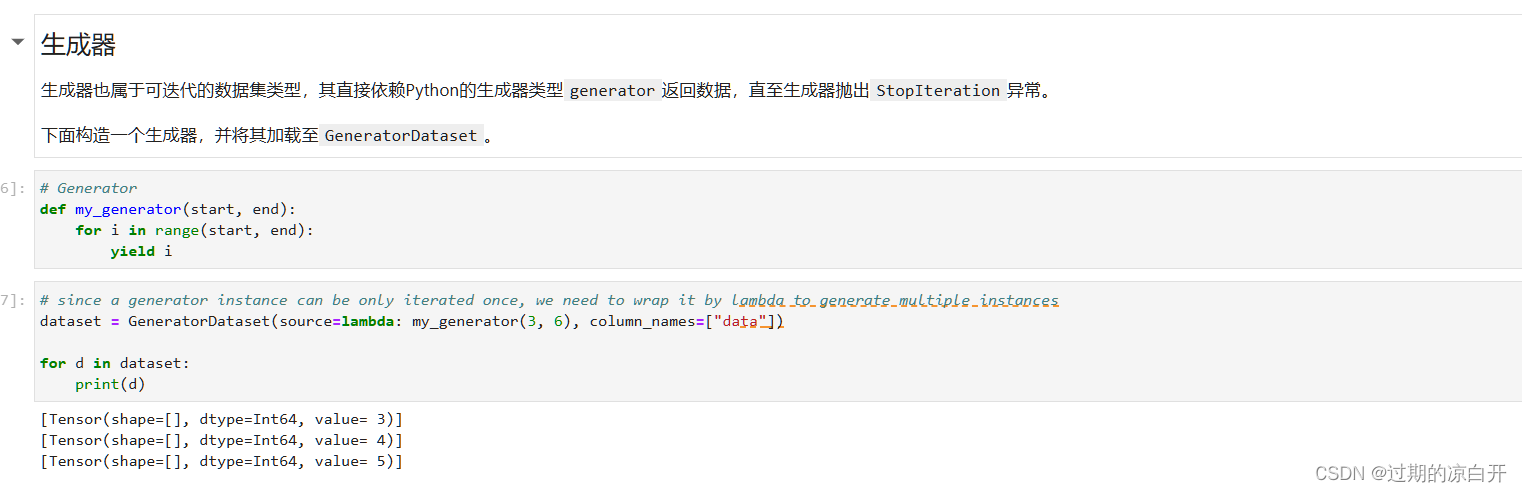
自定义数据集
















 447
447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









