







观前提醒
本文默认读者已对三种排序的基本实现思路有了解,旨在分享在学习数据结构与算法时的一些粗浅看法
本文使用的三种排序的代码与冒泡采用的优化
count=0,cntwai=0,cntnei=0;这三个变量是计算排序算法在对应环节的执行次数
count:所需的交换操作
cntwai:所经过的外层循环次数
cntnei:所经过的内层循环次数,插入排序因为交换拆分了所以count跟cntnei是一样的
冒泡排序:
void maopao(int a[],int len){
int flag=1,i,t;int count=0,cntwai=0,cntnei=0;
while(len-- && flag){
flag=0;cntwai++;
for(i=0;i<len;i++){cntnei++;
if(a[i]>a[i+1]){//顺序前小后大
flag=1;count++;
t=a[i];
a[i]=a[i+1];
a[i+1]=t;
}
}
}
printf("maopao的count=%d,cntwai=%d,cntnei=%d\n",count,cntwai,cntnei);
}
ps: 优化后冒泡:仅以较普遍的提前退出优化法:即有flag标记的冒泡。至于鸡尾酒双向优化,个人感觉性价比不如直接使用其他排序,故在此不作比较
选择排序:
void xuanze(int a[],int len){//==选择排序对于较有序的的数组会做很多无用功
int i,j,k,t,cntwai=0,count=0,cntnei=0;
for(i=0;i<len;i++){
k=i;count++;
for(j=i+1;j<len;j++){cntwai++;
if(a[j]<a[k]){
k=j;cntnei++;
}
}
t=a[i];
a[i]=a[k];
a[k]=t;
} printf("xunaze的外层和交换count=%d,应该跟冒泡差只因为flag提前结束的cntwai=%d,找最小值移动的cntnei=%d\n",count,cntwai,cntnei);
}//啥子哦,选择还是比冒泡多走呀,虽然确实count对标交换是少,嗯,难道就是少的这里?(直接)插入排序:
void inset(int a[],int len){
int i,j,t;
int count=0,cntwai=0,cntnei=0;
for(i=1;i<len;i++){
t=a[i];cntwai++;
for(j=i;j>=1 && /*a[j]*/t<a[j-1];j--){count++;cntnei++;
//t=a[j];//2024.6.28优化减少赋值操作
a[j]=a[j-1];
//a[j-1]=t;
}a[j]=t;//为什么可以j? 因为如果t是>=a[j-1]t得赋给a[j],如果是因为j==0,上一次赋值也把a[1]=a[0]可以搞a[0]了
}
printf("inset的count=%d,cntwai=%d,cntnei=%d\n",count,cntwai,cntnei);
}冒泡、选择、(直接)插入排序哪个快?
先给第一个问题的答案:
当数据量足够大时:插入 > 选择 > 优化后冒泡
、
当数据量较小时:插入 > 优化后冒泡 >= 选择
ps: 数据量足够大一般指以千及以上为单位时,数据量较小一般指以百、十为单位时。
插入排序因为只需要较短的交换路程和一次遍历就能结束的优势,能保证任何情况下都快过剩下的两排序。这也是为什么在众多语言中的 sort 函数都会使用快速排序+插入排序的组合拳---当数据量较小时使用插入排序,数据量大时用快速排序
为什么选择和冒泡明明走的都是两重循环但选择排序快过优化后冒泡排序?
回答:因为冒泡操作一般多于选择
对选择和冒泡排序我们最直观的想到就是:
选择排序是每一次遍历找到一个最小(最大)值,然后通过交换放在有序部分,必定遍历n次(也是导致其在小规模数据量时比不过冒泡的原因)。
冒泡排序是每次遍历时通过相邻两数对比和交换,在当次遍历中逐渐将最大(最小)值“冒泡”交换到最后,可以优化在当其中某次遍历没有遇到需要交换的情况时直接退出。
同时,两种排序都使用最多的操作就是:比较和交换操作
所以猜想答案是:对于比较操作,两种排序都是二重循环,也就是n*(n-1)*(n-2)*(n-3)*......*1次比较,是一样的。对于交换操作,因为冒泡每次遍历可能需要多次交换操作,而选择排序只需要一次遍历交换一次元素。而交换操作需要的步骤正常来说需要三步---打开冰箱,拿出食物,关上冰箱(bushi),所以冒泡的操作理论上来说总数会比选择排序多。
但你也许会问,冒泡在优化后不是可以提前结束嘛?他可以早换早结束呀!
没错!在一些情况下,冒泡确实会比选择排序快,所以对于小规模数据,冒泡是有可能快过选择的。 但,flag的提前结束优化是有极限的(*`皿´*)ノ!当数据量大起来时,你冒泡还是步长为1的慢慢去交换对比交换对比,flag也没法在没冒完泡时帮你超过选择呀!
flag:(╬ ̄皿 ̄)=○#( ̄#)3 ̄) :冒泡
所以就有了上面的小规模冒泡快选择,大规模选择快冒泡,插入永远快过选择冒泡
下面实例图说话
实例图使用说明:
main函数(看着很长而已,内核不多只是为了让大家知道之后的显示顺序,刚学c时代的代码,命名多是拼音直译(╥╯^╰╥))
int main (){
int n,i;
scanf("%d",&n);
int a[n],b[n],c[n];
suiji(a,n);//========自动挡
/*for(i=0;i<n;i++){
scanf("%d",&a[i]);//手动挡
}*/
printf("随机生成的是:");
for(i=0;i<n;i++){
printf("%d ",a[i]);
b[i]=a[i];
c[i]=a[i];
}
printf("\n");
clock_t begin1 = clock();
maopao(a,n);
clock_t end1 = clock();
double duration1 = (end1 - begin1);
printf("maopao函数耗时=%lf\n排序之后的是:",duration1);
for(i=0;i<n;i++){
printf("%d ",a[i]);
}
printf("\n");
clock_t begin2 = clock();
inset(b,n);
clock_t end2 = clock();
double duration2 = (end2 - begin2);
printf("inset函数耗时=%lf\n排序之后的是:",duration2);
for(i=0;i<n;i++){
printf("%d ",b[i]);
}
printf("\n");
clock_t begin3 = clock();
xuanze(c,n);
clock_t end3 = clock();
double duration3 = (end3 - begin3);
printf("xuanze函数耗时=%lf\n排序之后的是:",duration3);
for(i=0;i<n;i++){
printf("%d ",c[i]);
}
return 0;
}及使用的计时是clock_t类型,是获取处理器时钟的,想了解更多的可以看
C 语言中的 time 函数总结 | 菜鸟教程 (runoob.com)
随机化函数用的时间种子,可以看C 库函数 – srand() | 菜鸟教程 (runoob.com)
---
较小数据时(50)
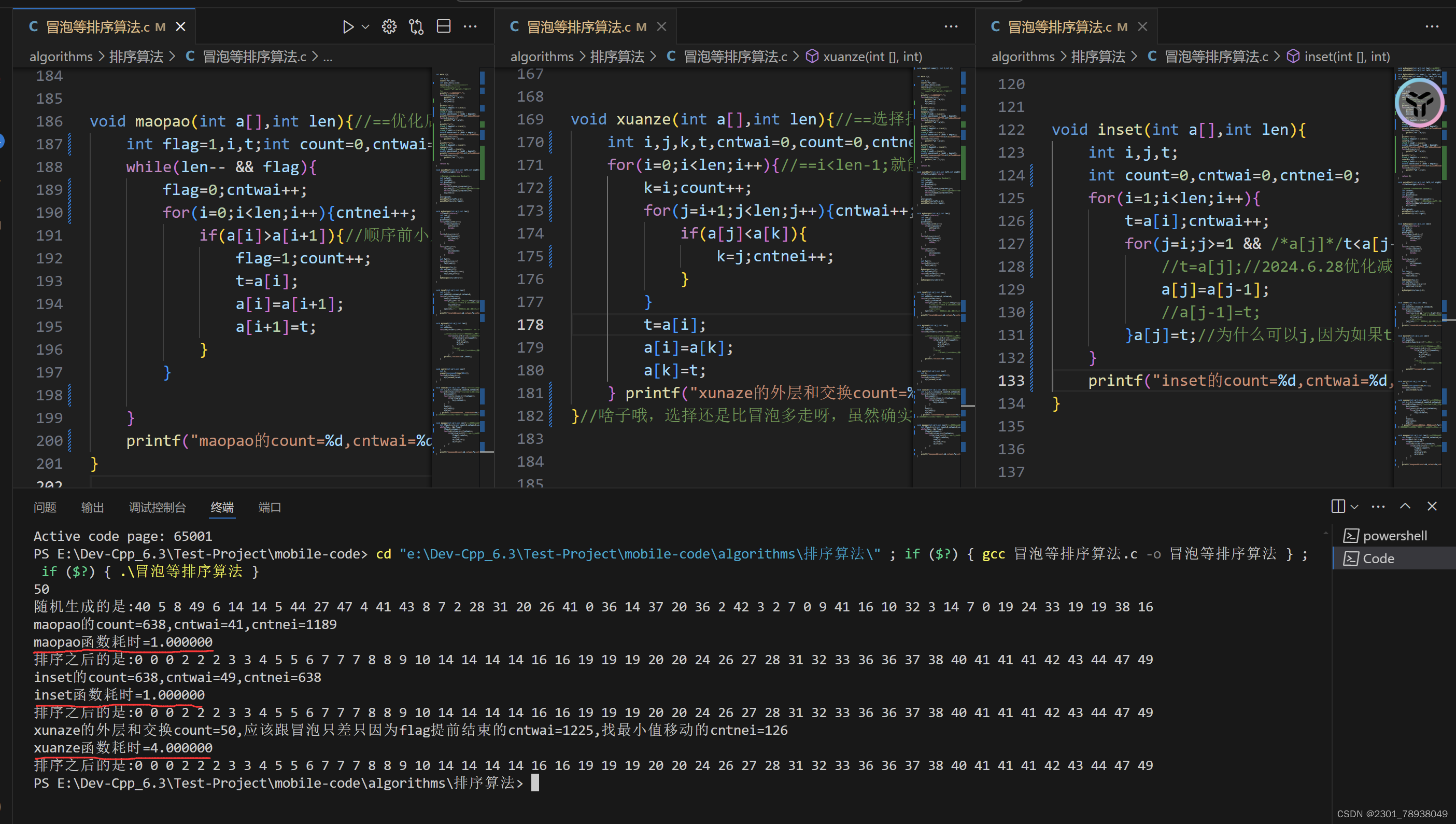
可以看出,当仅需排序50位时,这次例子优化冒泡甚至跟插入不相上下,都仅耗时1个cpu时间
较小规模实例2(500)
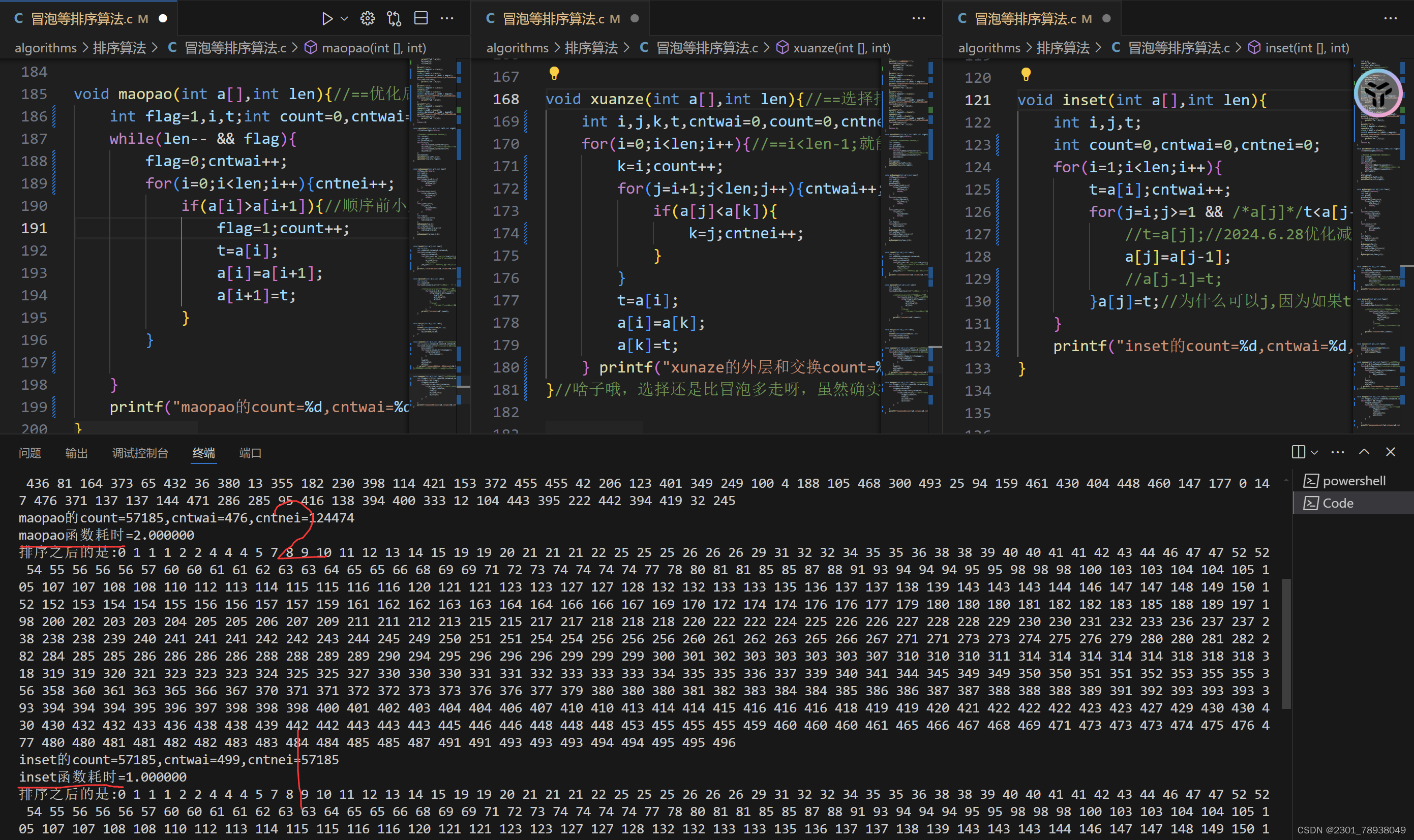
之后输出较多的,都分两张或者多张图了
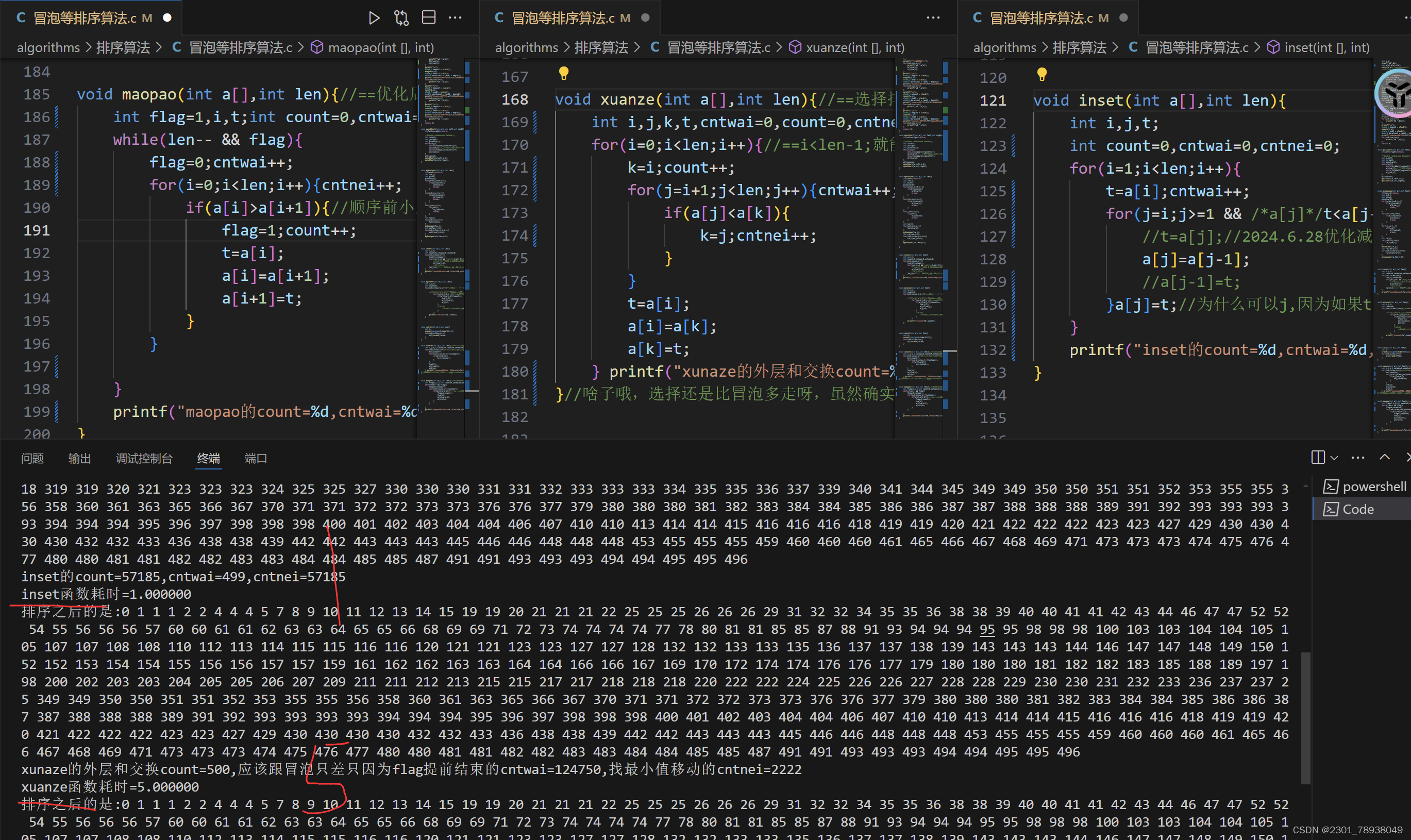
可以看出此次冒泡2,选择5,插入1 冒泡还是快过选择一点
数据以千计时(5000)
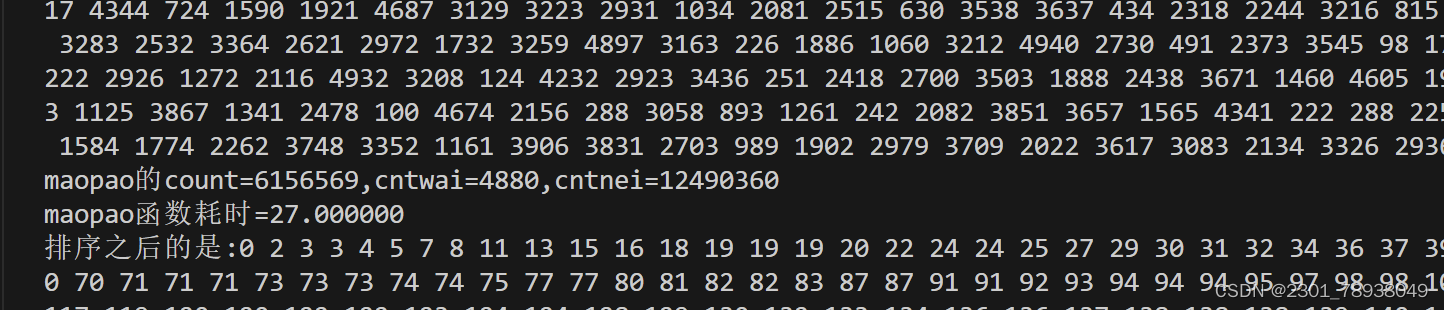
冒泡用时27

选择用时20
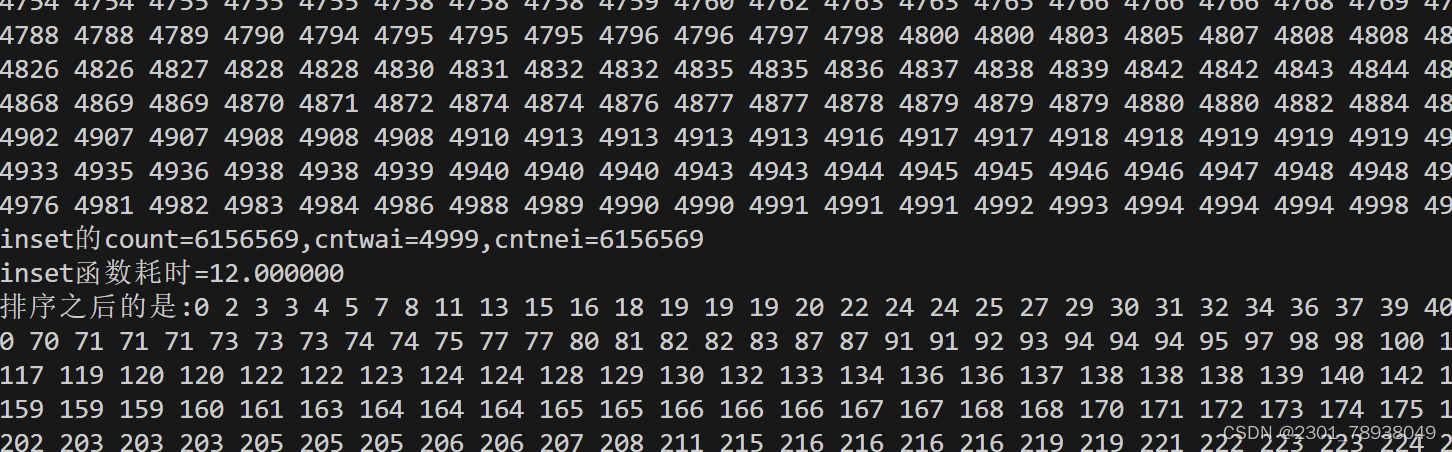
插入用时12
数值为五千往后都能稳定保持排序用时:冒泡 > 选择 > 插入
这篇只是今日看到前辈的视频个人在实现时的小记录,含量不是很高,水水的今天就不镇楼了(;´д`)ゞ
前辈算法系列小视频指路为什么选择排序比冒泡排序快 2 倍?_哔哩哔哩_bilibili















 1686
1686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









