






进程内缓存
缓存空间和代码程序位于同一台机器的同一进程内
其实就是常见的,在本机内存中开辟一块空间用于数据缓存,由于内存的读写速度远高于磁盘,所以,对于系统性能会有很大的提升
JDK Map
- HashMap:底层基于hash表,用一个唯一的key作为数据的标识符,并且,通过一定的算法,将key转换为数据的索引,用于在底层数组进行快速读写,hashMap底层是哈希表+红黑树+双向链表
- ConcurrentHashMap:是JUC并发包提供的一个线程安全的hashMap,在多线程同时执行数据更新操作时,通过底层加锁,保证数据的安全
- LinkedHashMap:保留了元素的插入顺序,在一些特殊的业务场景中,发挥作用
- TreeMap:底层基于红黑树
ConcurrentHashMap
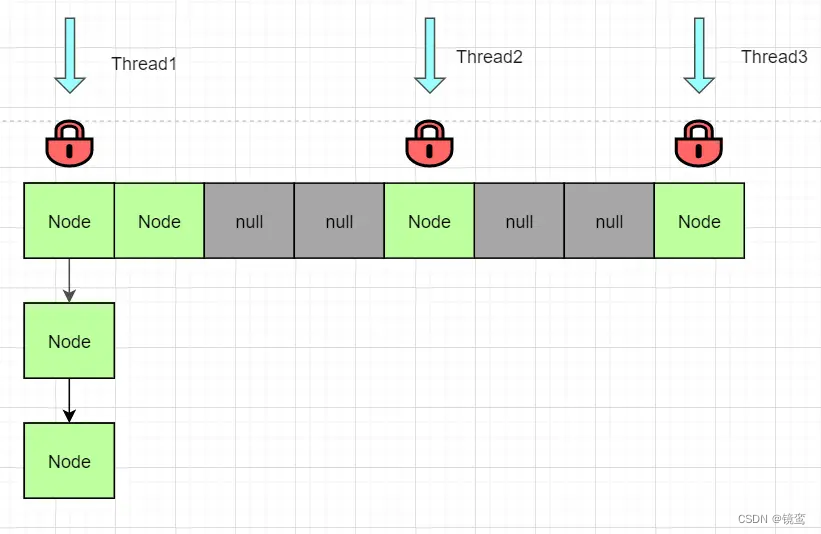
为什么ConcurrentHashMap可以保证线程安全?
细粒度的锁:
ConcurrentHashMap只对哈希表中的头节点加锁,锁的粒度小,减少了对整体性能的影响
应用:
springIoC的bean单例池
本地缓存框架
使用缓存框架比单纯的使用JDK原生Map,可以实现的功能更多,例如,实现缓存的清理,缓存定期淘汰等,因为内存是十分宝贵的资源,所以,必须要将缓存所占用的内存空间控制在合理的范围内
不能让缓存无限的增大,不然,会使本机的内存资源耗尽,最终,让本机直接宕机
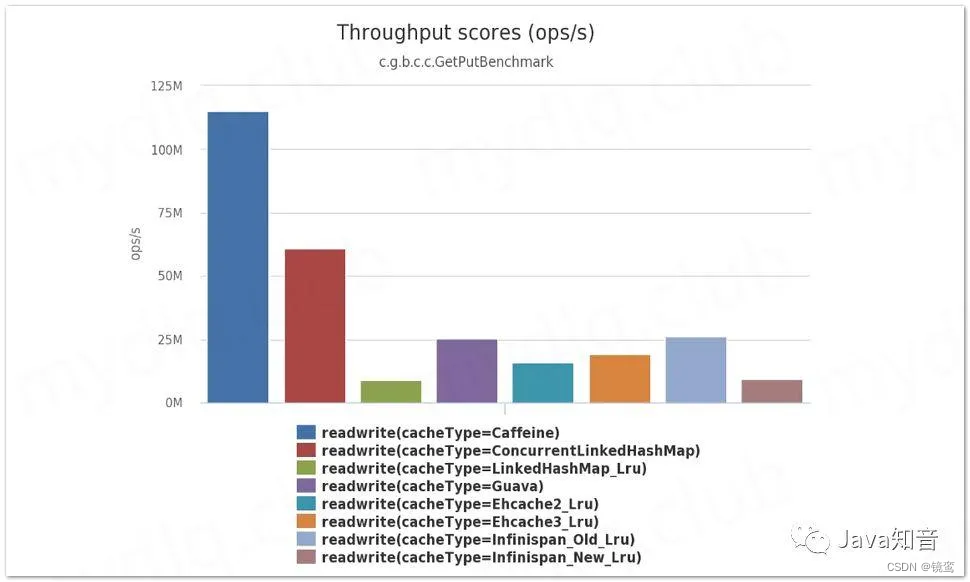
Caffeine
咖啡因框架,在一众缓存框架中性能最高,使用W-TinyLFU淘汰策略,支持缓存的容量控制,统计信息等
<!-- https://mvnrepository.com/artifact/com.github.ben-manes.caffeine/caffeine -->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.1.8</version>
</dependency>
可以整个spring服务共用一个Caffeine缓存,只要在配置类中创建并且注入到SpringIoC容器中就行了
可以看到Caffeine依然是基于索引来标识缓存的
@Configuration
public class CaffeineConfig {
@Bean
public Cache<String,Object> caffeine(){
return Caffeine
.newBuilder()
.maximumSize(1000)
.expireAfterWrite(5, TimeUnit.MINUTES)
.build();
}
}
cache.put("test1",1);
cache.put("test2",2);
cache.put("test3",3);
System.out.println(cache);
System.out.println(cache.getIfPresent("test1"));
//通过让key失效删除缓存
cache.invalidate("test1");
//返回有关缓存的统计信息:例如缓存命中次数或者缓存命中率等
CacheStats stats = cache.stats();
System.out.println(stats.hitCount());
System.out.println(stats.hitRate());
- maximumSize: 指定缓存可以包含的最大条目数。 请注意,缓存可能会在超出此限制之前逐出条目,或者在逐出时暂时超出阈值。
当缓存大小接近最大值时,缓存会逐出不太可能再次使用的条目。 例如,缓存可能会驱逐某个条目,因为它最近或不经常使用。
当大小为零时,元素在加载到缓存后将立即被驱逐。 这在测试中很有用,或者在不更改代码的情况下暂时禁用缓存。
由于驱逐是在配置的执行器上安排的,因此测试可能更喜欢将缓存配置为直接在同一线程上执行任务。 此功能不能与 MaximumWeight
结合使用。 参数: MaximumSize – 缓存的最大大小 返回: 这个咖啡因实例(用于链接) - expireAfterWrite 指定在创建条目或最近替换其值后经过固定持续时间后,应自动从缓存中删除每个条目。 过期条目可能会计入
Cache.estimatedSize() 中,但对于读或写操作永远不可见。 作为 javadoc
类中描述的例行维护的一部分,过期的条目将被清除。 可以配置调度器(Scheduler)来及时删除过期条目。 如果您可以将持续时间表示为
Duration(在可行的情况下应首选),请改用 expireAfterWrite(Duration)。 参数: 持续时间 –
条目创建后应自动删除的时间长度 单位 – 持续时间表示的单位 返回: 这个咖啡因实例(用于链接) 投掷:
IllegalArgumentException – 如果持续时间为负数 IllegalStateException –
如果已设置生存时间或变量到期时间
Cache、LoadingCache、AsyncCache 和 AsyncLoadingCache 实例的构建器,具有以下功能的组合:
自动将条目加载到缓存中,可以选择异步 当超过基于频率和新近度的最大值时,基于大小的驱逐 基于时间的条目到期时间,自上次访问或上次写入以来测量
当第一个条目的过时请求发生时异步刷新 键自动包装在弱引用中 值自动包装在弱引用或软引用中 写入传播到外部资源
驱逐(或以其他方式删除)条目的通知 缓存访问统计数据的累积 这些功能都是可选的; 可以使用全部或不使用其中任何一个来创建缓存。
默认情况下,Caffeine 创建的缓存实例不会执行任何类型的驱逐。
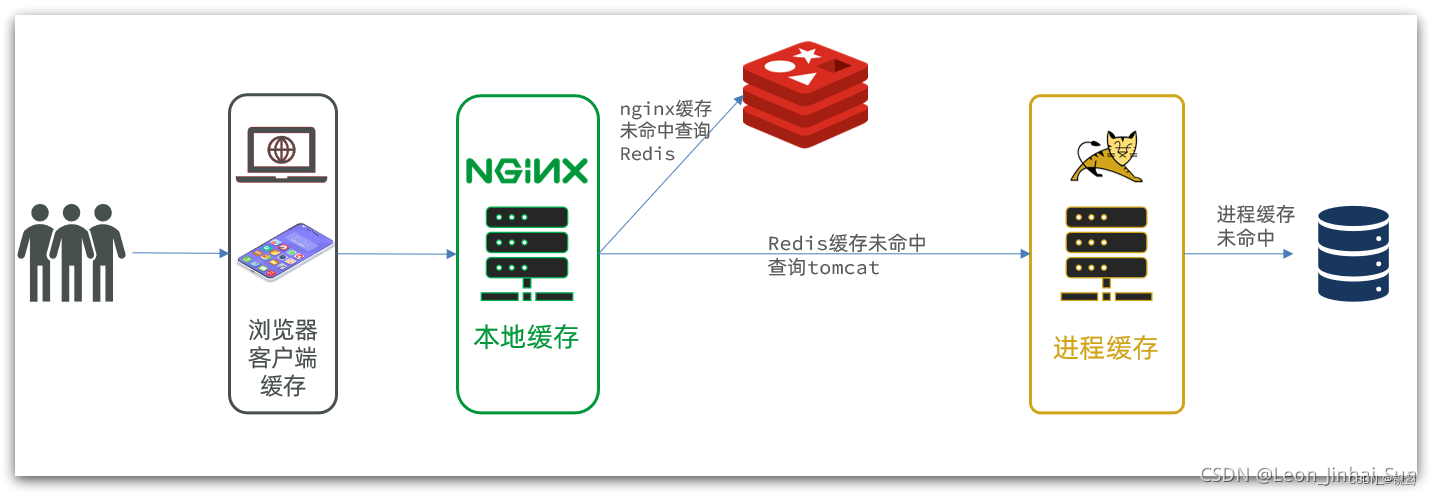
分布式缓存
将缓存存到其他机器上,最主流的使用redis远程缓存库,就行缓存读写管理
多级缓存
构建多级缓存,可以提升数据访问效率,同时能有效减少mysql压力
一级缓存:进程内缓存,使用本地缓存框架
二级缓存:分布式缓存/远程缓存,使用redis远程缓存库















 653
653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









