






 本文围绕图的子图和模体展开,介绍了子图和模体的定义、重要性评估方法,如用随机图作空模型通过Z分数评估。还阐述了神经子图匹配,利用图神经网络预测子图同构。此外,探讨了寻找频繁子图的挑战及解决办法,如用表示学习和SPMiner模型识别高频模体。
本文围绕图的子图和模体展开,介绍了子图和模体的定义、重要性评估方法,如用随机图作空模型通过Z分数评估。还阐述了神经子图匹配,利用图神经网络预测子图同构。此外,探讨了寻找频繁子图的挑战及解决办法,如用表示学习和SPMiner模型识别高频模体。
子图是网络的构建基块:
它们具有表征和区分网络的能力
在许多领域中,经常出现的结构组件决定了图的功能或行为
1) 子图和模体
▪ 定义子图和模体
▪ 确定模体重要性
2) 神经子图表示
3) 挖掘频繁模体
"网络构建基块" 的形式化有两种方法:
1. 给定图 𝑮 = (𝑽, 𝑬):
定义1. 节点诱导子图:取节点的子集以及由这些节点诱导的所有边:
- 若 𝐺′ = (𝑉′, 𝐸′) 是一个节点诱导子图,满足以下条件:
- 𝑉′ ⊆ 𝑉
- 𝐸′ = {(𝑢, 𝑣) ∈ 𝐸 | 𝑢, 𝑣 ∈ 𝑉′}
- 𝐺′ 是由 𝑉′ 在 𝐺 中诱导的子图
替代术语: "诱导子图"
定义2. 边诱导子图:取边的子集以及所有相应的节点
- 若 𝐺′ = (𝑉′, 𝐸′) 是一个边诱导子图,满足以下条件:
- 𝐸′ ⊆ 𝐸
- 𝑉′ = {𝑣 ∈ 𝑉 | (𝑣, 𝑢) ∈ 𝐸′ 对于某个 𝑢}
替代术语: "非诱导子图" 或仅称 "子图"
请注意,我在文本中使用了斜体来表示数学符号,以及缩进和符号 "▪" 来表示项目符号。如果您有特定的格式需求或调整,还请告诉我,我会根据您的要求进行修改。
- 最佳定义取决于领域!
例子:
- 化学:节点诱导(功能团)
- 知识图谱:通常是边诱导(关注于代表逻辑关系的边)
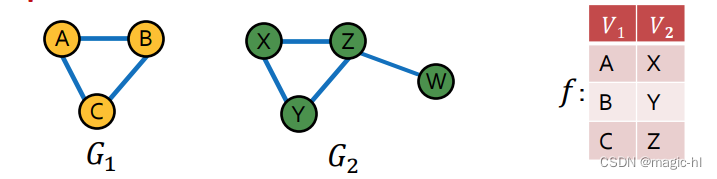
前面的定义在 𝑉′ ⊆ 𝑉 和 𝐸′ ⊆ 𝐸 时定义了子图,即从原图 G 中取出节点和边。但如果 𝑽′ 和 𝑬′ 来自完全不同的图呢?例如:
我们希望说 𝑮𝟏 “包含在” 𝑮𝟐 中。
图同构问题:检查两个图是否相同:
- 若存在双射 𝑓: 𝑉1 → 𝑉2,使得 (𝑢, 𝑣) ∈ 𝐸1 当且仅当 𝑓(𝑢), 𝑓(𝑣) ∈ 𝐸2,那么 𝐺1 = (𝑉1, 𝐸1) 和 𝐺2 = (𝑉2, 𝐸2) 是同构的。
- 𝑓 被称为同构映射。
目前我们不知道图同构问题是否是 NP 难问题,也没有找到用于解决图同构的多项式算法。
如果 𝐺2 的某个子图同构于 𝐺1,则称 𝐺2 是 𝐺1 的子图同构。
- 我们通常也说 𝐺1 是 𝐺2 的子图。
- 我们可以使用节点诱导或边诱导的子图定义。
- 这个问题是 NP 难问题。
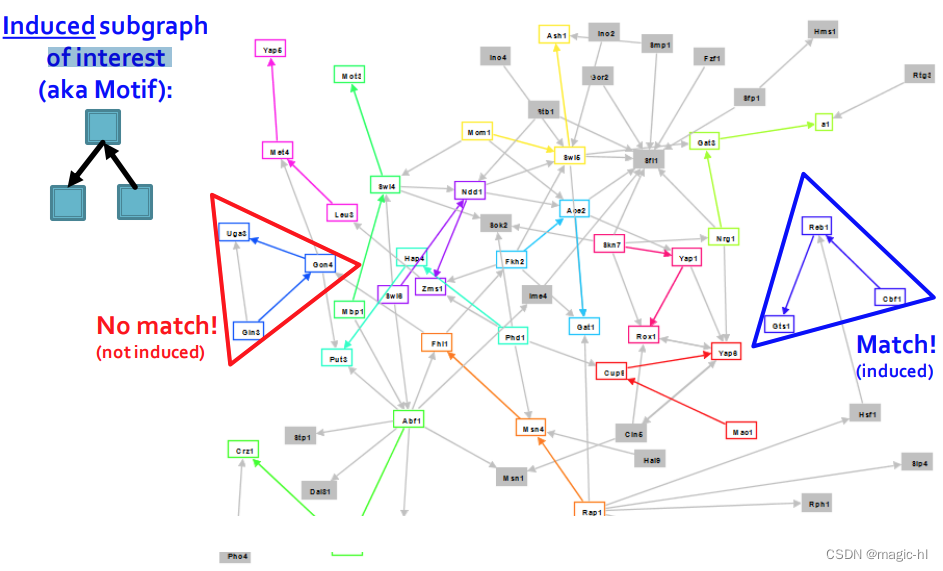
网络模体motifs: "重复出现的、具有重要互连模式的图案"
如何定义网络模体:
▪ 模式:小型(节点诱导)子图
▪ 重复出现:被多次发现,即具有高频率。如何定义频率?
▪ 重要性:比预期更频繁出现,即在随机生成的图中?如何定义随机图?
为什么我们需要motif?
模体:
▪ 帮助我们理解图的运作方式
▪ 基于图数据集中的存在与缺失,帮助我们做出预测
例子:
▪ 前馈环:在神经网络中发现,可以消除 "生物噪声"
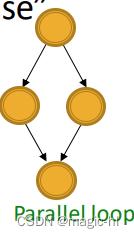
▪ 平行环:在食物网中发现
▪ 单输入模块:在基因控制网络中发现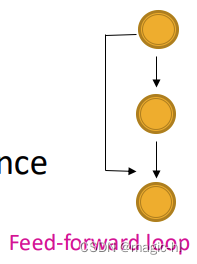

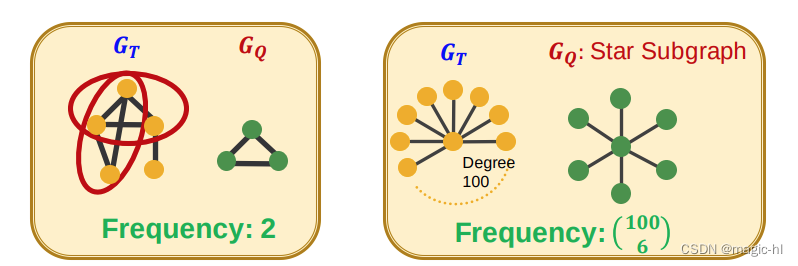
假设 𝐺𝑄 是一个小图,𝐺𝑇 是一个目标图数据集。
图级别子图频率定义
𝐺𝑄 在 𝐺𝑇 中的频率:对于 𝐺𝑇 的节点子集 𝑉𝑇,使得 𝐺𝑇 中由节点 𝑉𝑇 诱导的子图同构于 𝐺𝑄 的唯一子集数量。
假设 𝐺𝑄 是一个小图,𝑣 是 𝐺𝑄 中的一个节点("锚点"),𝐺𝑇 是一个目标图数据集。
节点级别子图频率定义:
- 在 𝐺𝑇 中存在一些子图同构于 𝐺𝑄 并且同构映射将节点 𝑢 映射到节点 𝑣,计算这样的节点 𝑢 的数量。
称 (𝐺𝑄, 𝑣) 为节点锚定子图
对异常值具有鲁棒性
如果数据集包含多个图,我们想要计算数据集中子图的频率怎么办?
解决方法:将数据集视为一个巨大的图 𝐺𝑇,其中断开的组件对应于各个独立的图。
要定义重要性,我们需要一个空模型(即比较的基准)。
关键思想:在真实网络中出现频率远高于随机网络的子图具有功能上的重要性。
目标:生成具有给定度序列 k1、k2、… kN 的随机图。
作为网络的 "空" 模型很有用:
▪ 我们可以将真实网络 𝐺real 与具有与 𝐺real 相同度序列的 "随机" 𝐺rand 进行比较。
配置模型:
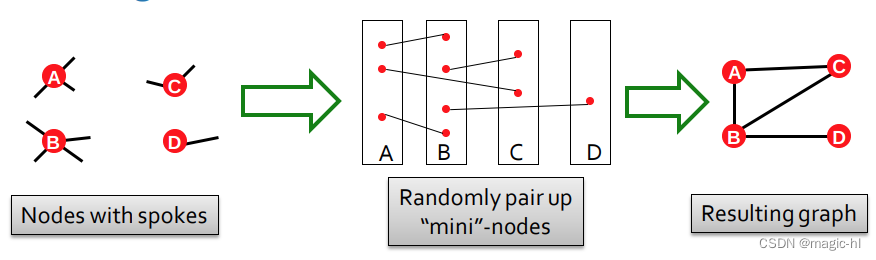
从给定的图 𝑮 开始
重复切换步骤 𝑄 ⋅ |𝐸| 次:
▪ 随机选择一对边 A→B,C→D
▪ 交换端点以得到 A→D,C→B
▪ 仅当不会生成多重边或自环边时才交换边
结果:一个随机重连的图:
▪ 节点度数相同,边随机重连
选择足够大的 𝑄(例如,𝑄 = 100)以确保过程收敛
直觉:与随机图相比,图中的模体被过度呈现:
步骤1:在给定的图中(𝐺real)计数模体
步骤2:生成具有相似统计数据的随机图(例如,节点数、边数、度序列),并在随机图中计数模体
步骤3:使用统计度量来评估每个模体的重要性
▪ 使用 Z 分数
𝑍𝑖 衡量模体 𝒊 的统计显著性:
𝑍𝑖 = (𝑁𝑖real−𝑁𝑖rand)/std(𝑁𝑖rand)
▪ 𝑁𝑖real 表示在图 𝐺real 中的 #(模体 𝑖)
▪ 𝑁𝑖rand 表示在随机图实例中的 #(模体 𝑖) 平均值
网络显著性概况(SP):
▪ 𝑆𝑃 是一组标准化的 Z 分数
▪ 维度取决于考虑的模体数量
▪ 𝑆𝑃 强调子图的相对重要性:
▪ 对于不同大小的网络进行比较很重要
▪ 通常情况下,较大的图显示出更高的 Z 分数
对于每个子图:
▪ Z 分数度量能够对子图的 "重要性" 进行分类:
▪ 负值表示欠表示
▪ 正值表示过表示
我们创建一个网络显著性概况:
▪ 一个特征向量,包含所有子图类型的值
接下来:将不同图的概况与随机图进行比较:
▪ 调控网络(基因调控)
▪ 神经网络(突触连接)
▪ 万维网(页面间的超链接)
▪ 社交网络(友谊)
▪ 语言网络(单词邻接)
在 𝐺real 中计数模体 𝑖
在随机图 𝐺rand 中计数模体 𝑖:
▪ 空模型:每个 𝐺rand 具有与 𝐺real 相同的节点数量、边数量和度分布
为模体 𝑖 分配 Z 分数:
▪ 𝑍𝑖 = (𝑁𝑖real−𝑁𝑖rand)/std(𝑁𝑖rand)
▪ 高 Z 分数:模体 𝑖 是一个网络模体
扩展:
▪ 有向和无向
▪ 带颜色和不带颜色
▪ 时间和静态模体
概念的变种:
▪ 不同的频率概念
▪ 不同的重要性度量
▪ 欠表示(反模体)
▪ 不同的空模型
子图和模体是图的构建基块
▪ 子图同构和计数是 NP 难问题
理解数据集中哪些模体是频繁或显著的,可以洞察该领域的独特特征
使用随机图作为空模型,通过 Z 分数评估模体的重要性
2. 神经子图匹配(neural subgraph matching)
给定:
大型目标图(可以是不连通的)
查询图(连通的)
决定:
查询图是否是目标图的子图?
节点颜色指示节点的正确映射关系
大型目标图(可以是不连通的)
查询图(必须是连通的)
使用图神经网络(GNN)来预测子图同构:
直觉:利用嵌入空间的几何形状,捕捉子图同构的特性。
考虑一个二元预测:如果查询图同构于目标图的子图,则返回 True;否则返回 False。
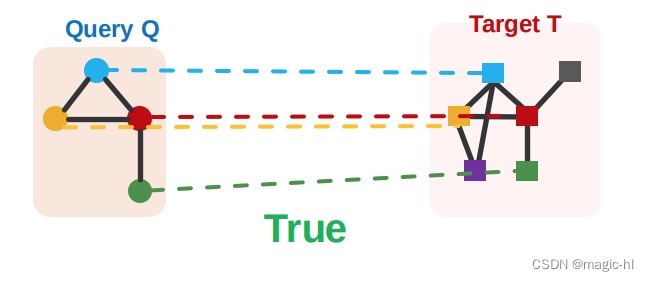
在此讲座中不会涵盖查找查询图 Q 和目标图 T 之间节点对应关系的另一个具有挑战性的问题。
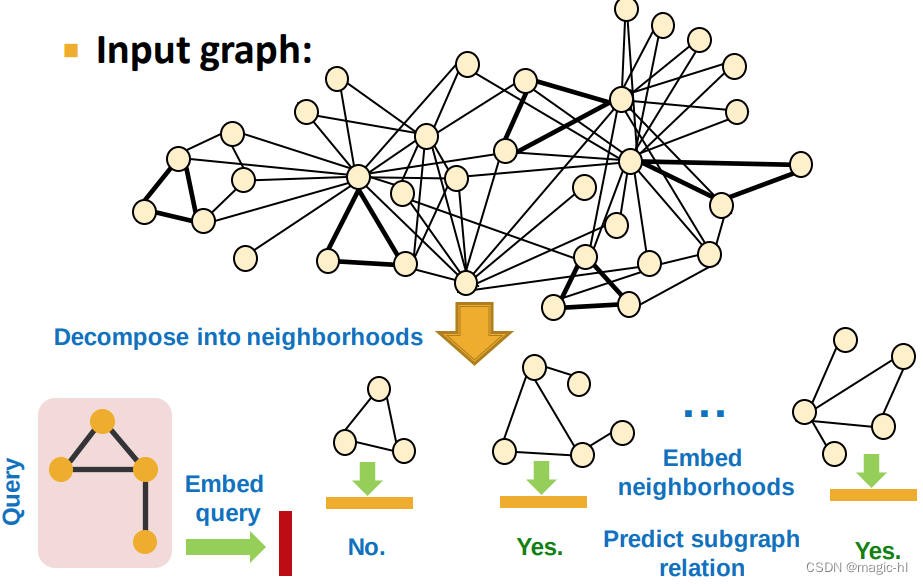
(1) 我们将使用节点锚定的定义进行工作:
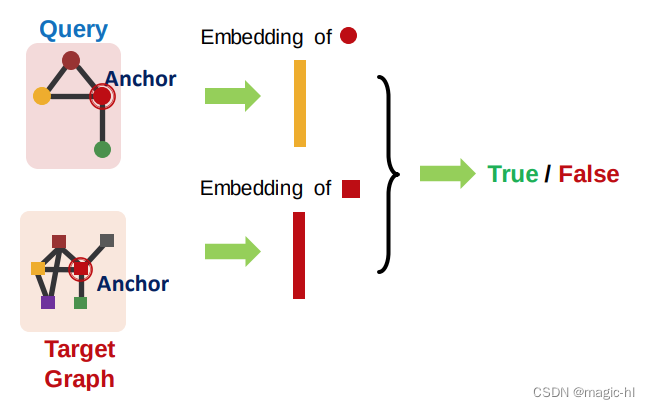
(2) 我们将使用节点锚定的邻域进行工作:
使用图神经网络(GNN)获取节点 𝑢 和 𝑣 的表示
预测节点 𝒖 的邻域是否同构于节点 𝒗 的邻域:
如何利用嵌入来进行预测?
回顾节点级别频率定义:
在图 𝐺𝑇 中存在一些子图同构于 𝐺𝑄 并且同构映射将节点 𝑢 映射到节点 𝑣 的节点 𝑢 数量
我们可以使用 GNN 计算节点 𝑢 和 𝑣 的嵌入
使用嵌入来判断节点 𝑢 的邻域是否同构于节点 𝑣 的邻域的子图
我们不仅预测是否存在映射,还可以识别相应的节点(𝑢 和 𝑣)!
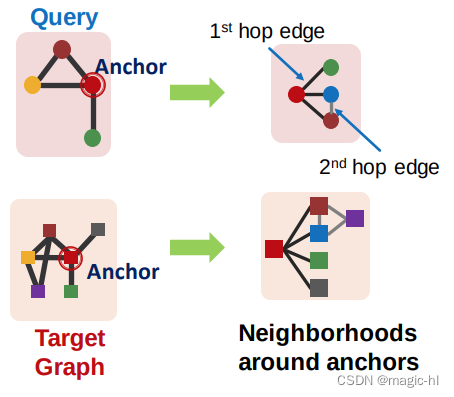
对于 𝑮𝑻 中的每个节点:
▪ 获取以锚点为中心的 k 跳邻域
▪ 可以使用广度优先搜索(BFS)来执行
▪ 深度 𝑘 是一个超参数(例如,3)
▪ 更大的深度会导致更昂贵的模型
同样的过程适用于 𝐺𝑄 以获取邻域
我们使用 GNN 嵌入这些邻域
▪ 通过为各自邻域中的锚点节点计算嵌入
将图 𝐴 映射到一个高维(例如,64维)嵌入空间中的点 𝑧𝐴,使得 𝑧𝐴 在所有维度上都是非负的,捕捉偏序(传递性):
直觉:子图在其超图的左下方(在 2D 中)。
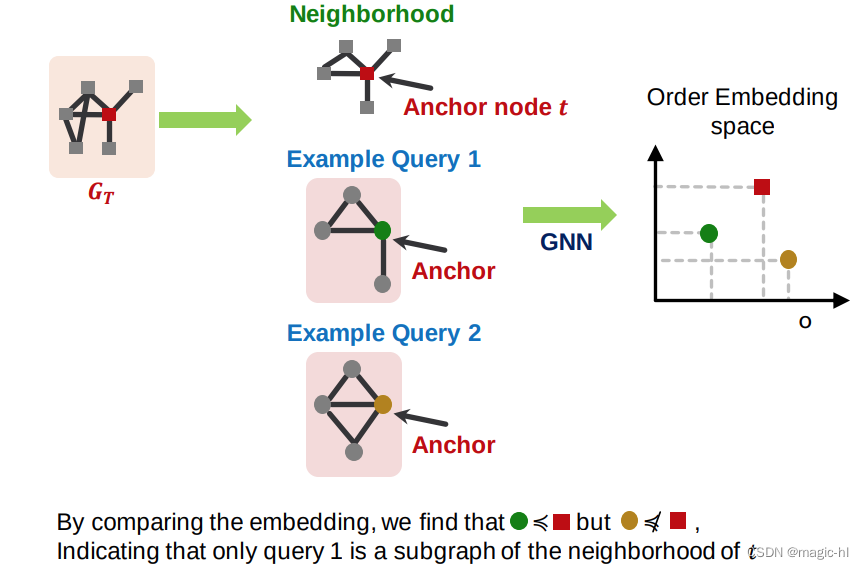
子图同构关系可以很好地在次序嵌入空间中进行编码:
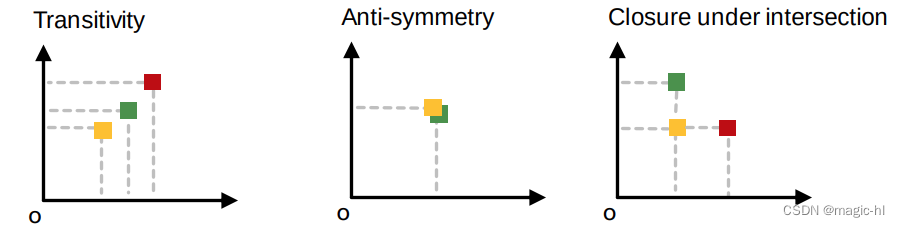
▪ 传递性:如果 𝐺1 是 𝐺2 的子图,𝐺2 是 𝐺3 的子图,那么 𝐺1 也是 𝐺3 的子图。
▪ 反对称性:如果 𝐺1 是 𝐺2 的子图,并且 𝐺2 是 𝐺1 的子图,则 𝐺1 同构于 𝐺2。
▪ 交集闭包性:只含一个节点的平凡图是任何图的子图。
▪ 所有这些性质在次序嵌入空间中都有对应。
我们使用图神经网络(GNN)来学习嵌入邻域,并保持次序嵌入结构。
我们应该使用什么损失函数,以便所学的次序嵌入反映子图关系?
我们基于次序约束设计损失函数:
▪ 次序约束指定了理想的次序嵌入属性,反映子图关系。
我们指定次序约束以确保子图属性在次序嵌入空间中得以保留。

GNN 嵌入是通过最小化最大间隔损失来学习的。
将 𝐸 𝐺𝑞,𝐺𝑡 = σ𝑖=1𝐷(max(0, 𝑧𝑞[𝑖] − 𝑧𝑡[𝑖]))2,定义为图 𝐺𝑞 和 𝐺𝑡 之间的 "间隔"。
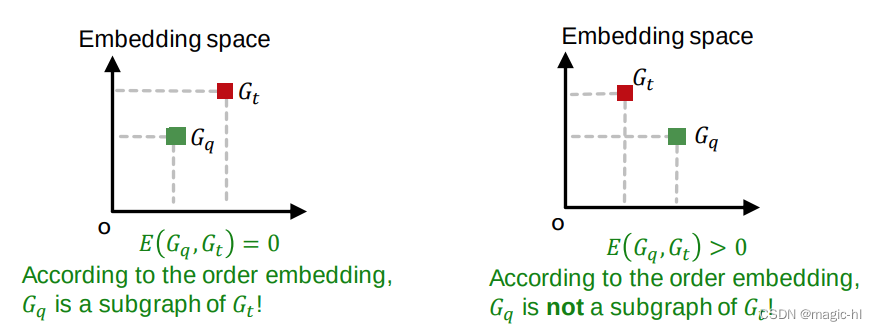
为了学习正确的次序嵌入,我们希望学习 𝒛𝒒, 𝒛𝒕,以使:
▪ 当 𝐺𝑞 是 𝐺𝑡 的子图时,𝐸 𝐺𝑞, 𝐺𝑡 = 0
▪ 当 𝐺𝑞 不是 𝐺𝑡 的子图时,𝐸 𝐺𝑞, 𝐺𝑡 > 0
为了学习这种嵌入,构建训练样本 (𝐺𝑞,𝐺𝑡) 其中一半时间,𝐺𝑞 是 𝐺𝑡 的子图,另一半时间,它不是。
通过最小化以下最大间隔损失进行训练:
▪ 对于正例:当 𝐺𝑞 是 𝐺𝑡 的子图时,最小化 𝐸(𝐺𝑞, 𝐺𝑡)
▪ 对于负例:
最小化 max(0, 𝛼 − 𝐸 𝐺𝑞,𝐺𝑡)
▪ 最大间隔损失阻止模型学习将嵌入不断拉开的退化策略。
需要从数据集 𝐺 中生成训练查询 𝐺𝑄 和目标 𝐺𝑇。
从随机锚点 𝑣 中选择 𝐺𝑇,并选择距离 𝑣 不超过 𝐾 的所有节点。
正例:从 𝐺𝑇 中生成诱导子图 𝐺𝑄。使用 BFS 采样:
▪ 初始化 𝑆 = 𝑣 , 𝑉 = ∅
▪ 令 𝑁(𝑆) 表示 S 中节点的所有邻居。每一步,在 𝑁 𝑆 ∖ 𝑉 中采样 10% 的节点,将它们放入 𝑆 中。将 𝑁 𝑆 中剩余的节点放入 𝑉 中。
▪ 经过 𝐾 步,以 𝑞 为锚点在 𝑆 中提取 𝐺 的诱导子图。
负例(𝐺𝑄 不是 𝐺𝑇 的子图):通过添加/删除节点/边来“破坏” 𝐺𝑄,使其不再是子图。
需要采样多少训练样本?
▪ 每次迭代,我们采样新的训练对
▪ 好处:每次迭代,模型都会看到不同的子图示例
▪ 改善性能并避免过拟合 – 因为可以从指数数量的可能子图中进行采样
BFS 采样的深度是多少?
▪ 一个调整运行时间和性能的超参数
▪ 通常使用 3-5,取决于数据集的大小
给定:查询图 𝐺𝑞 以节点 𝑞 为锚点,目标图 𝐺𝑡 以节点 𝑡 为锚点
目标:输出查询是否为目标的节点锚定子图
过程:
▪ 如果 𝐸 𝐺𝑞, 𝐺𝑡 < 𝜖,则预测为“True”;否则为“False”
▪ 𝜖 是一个超参数
为了检查 𝐺𝑄 是否同构于 𝐺𝑇 的子图,对于所有 𝑞 ∈ 𝐺𝑄,𝑡 ∈ 𝐺𝑇 重复此过程。这里的 𝐺𝑞 是围绕节点 𝑞 在 𝐺𝑄 中的邻域。
总结:
神经子图匹配使用基于机器学习的方法来学习子图同构的 NP 难问题:
▪ 给定查询图和目标图,它将这两个图嵌入到一个次序嵌入空间中
▪ 利用这些嵌入,它计算 𝐸 𝐺𝑞, 𝐺𝑡 以确定查询是否是目标的子图
将图嵌入到次序嵌入空间中,可以通过图嵌入的相对位置高效地表示和测试子图同构。
3. Finding Frequent Subgraphs
通常情况下,找到最频繁的大小为 𝑘 的网络模体需要解决两个挑战:
1) 枚举所有大小为 𝑘 的连通子图
2) 计算每种子图类型的出现次数
仅仅知道某个特定的子图是否存在于图中,是一个难解的计算问题!
▪ 子图同构是 NP 完全问题
计算时间随子图大小的增加而呈指数增长
▪ 传统方法可行的模体大小相对较小(3 到 7)
寻找频繁子图模式是计算上困难的任务
▪ 可能模式数量的组合爆炸
▪ 计算子图频率是 NP 难问题
表示学习可以解决这些挑战:
▪ 组合爆炸 → 组织搜索空间
▪ 子图同构 → 使用 GNN 进行预测
表示学习可以解决这些挑战:
1) 计算每种子图类型的出现次数
▪ 解决方法:使用 GNN 来 "预测" 子图的频率
2) 枚举所有大小为 𝑘 的连通子图
▪ 解决方法:不枚举子图,而是逐步构建大小为 𝑘 的子图
▪ 注意:我们只对高频子图感兴趣
目标图(数据集)𝐺𝑇,大小参数 𝑘
所需结果数量 𝑟
目标:在所有可能的𝑘个节点的图中,识别在𝐺𝑇中具有最高频率的𝑟个图。
我们使用节点级别的定义:
在𝐺𝑇中,节点𝑢的数量,其中𝐺𝑇的某个子图同构于𝐺𝑄,且同构将节点𝑢映射到节点𝑣。
SPMiner: 一个用于识别频繁模体的神经模型
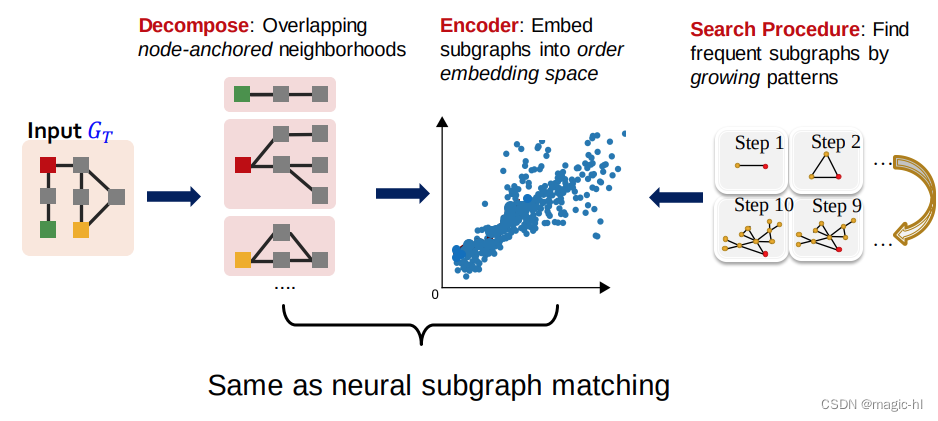
将输入图 𝐺𝑇 分解成邻域
将邻域嵌入到次序嵌入空间
次序嵌入的主要优势是:
我们可以快速地“预测”给定子图 𝐺Q的频率
给定:图 𝐺𝑇 的一组子图(“节点锚定邻域”)𝐺𝑁𝑖(随机采样)
关键思想:通过计数满足𝑧𝑄 ≤ 𝑧𝑁𝑖 条件的嵌入𝑧𝑁𝑖的𝐺𝑁𝑖的数量来估计𝐺𝑄 的频率
▪ 这是次序嵌入空间特性的结果
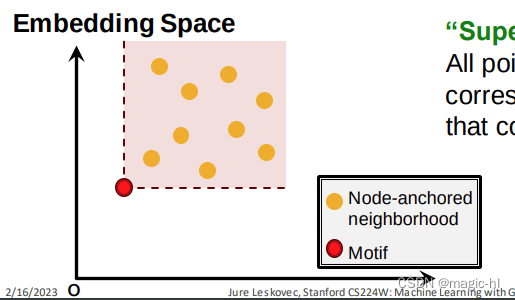
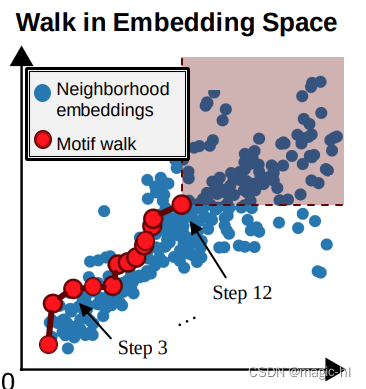
“超图”区域:
红色阴影区域中的所有点对应于包含𝐺𝑄的𝐺𝑇中的邻域
优势:超快速子图频率计数!
初始步骤:从目标图 𝐺𝑇 中随机选择一个起始节点 𝑢。设置 𝑆 = {u}。
阴影区域中的每个点表示目标图中包含模体模式的邻域
最初,所有邻域都包含平凡子图。
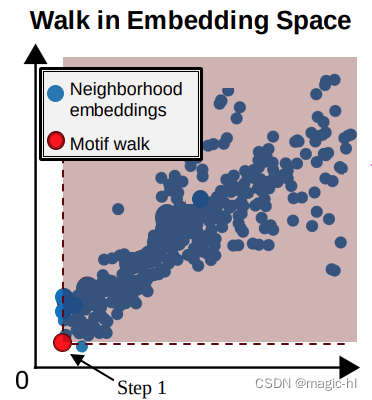
• 小型模体通过添加邻居进行扩展
• 它们的嵌入对应于左侧的红点
目标:在 𝑘 步后,最大化红色阴影区域中的邻域数量!
终止:达到所需的模体大小后,取由𝑆引发的目标图的子图。
识别的大小为 12 的频繁模体:
在所有可能的大小为 12 的子图的嵌入中,它在超图区域中具有最多的蓝点。
如何在每一步中选择要添加的节点?
定义:子图 𝐺 的总违反次数:
不包含 𝐺 的邻域的数量。
• 不满足 𝑧𝑄 ≼ 𝑧𝑁𝑖 的邻域𝐺𝑁𝑖 的数量
• 最小化总违反次数 = 最大化频率
贪心策略(启发式):
在每一步中,添加导致总违反次数最小的节点。 
真实情况:通过蛮力精确枚举(昂贵)在数据集中找到前 10 个最频繁的模体
问题:模型能否识别频繁模体?
结果:模型分别识别出前 10 个模体中的 9 个和 8 个。
问题:识别出的模体频率如何比较?
结果:SPMiner 识别出的模体出现频率比基线高出 10-100 倍。
4. 总结
子图和模体是重要的概念,可以为节点/图提供结构洞察。它们的频率可以用作节点/图的特征。
我们介绍了用于预测子图同构关系的神经方法。
次序嵌入具有理想的特性,可以用来编码子图关系。
基于次序嵌入空间的神经嵌入引导搜索可以使机器学习模型识别比现有方法更频繁的模体。

















 1052
1052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









