






数据处理
对于数据处理,我们关注数据的频率和质量。数据的频率依赖于聚类和去重。我们构建了一个支持 LSH-like 特征和密集嵌入特征的大规模去重和聚类系统。这个系统可以在几小时内对万亿级别的数据进行聚类和去重。基于聚类,个别文档、段落和句子都被去重并评分。这些评分然后用于预训练中的数据抽样。在数据处理的不同阶段,训练数据的大小如下图所示,绝对匹配去重 29.89% 数据,启发式方法去除 1.77%,句子级别的质量过滤 3%,句子级别和段落级别去重 14.47%,文档级别去重 19.13%
分词器
分词器需要平衡两个关键因素:利于高效推理的高压缩率和适当大小的词汇表,以确保每个词嵌入的充分训练。我们考虑了这两个方面。我们将词汇表的大小从 Baichuan 1 的 64,000 扩展到 125,696,旨在在计算效率和模型性能之间取得平衡。
- 使用 SentencePiece 的字节对编码(BPE)来对数据进行 tokenize 处理
- 没有对输入文本应用任何规范化,并且没有像 Baichuan 1 那样添加虚拟前缀
- 将数字拆分成单个数字以更好地编码数字数据
- 为了处理包含额外空格的代码数据,我们向分词器添加了仅包含空格的 token。字符覆盖率设置为 0.9999,罕见字符回退到 UTF-8 字节
- 将最大 token 长度设置为 32,以考虑长的中文短语。Baichuan2 分词器的训练数据来自 Baichuan2 预训练语料库,包括对于代码示例和学术论文更多采样以提高覆盖率
位置编码
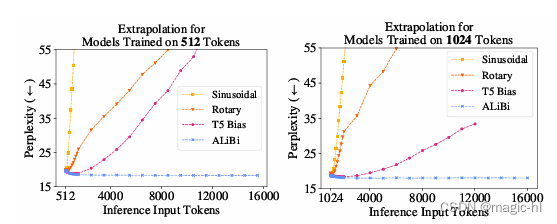
- Baichuan 2-7B 采用了 Rotary Positional Embedding,对于 Baichuan 2-13B,采用了 ALiBi
- ALiBi 是一种较新的位置编码技术,已经显示出更好的外推性能。然而,大多数开源模型使用 RoPE 作为位置嵌入,并且像 Flash Attention 这样的优化的注意力实现目前更适合 RoPE,因为它是基于乘法的,无需将 attention_mask 传递给注意力操作
- 然而,在初步实验中,位置嵌入的选择对模型性能影响不大。为了进一步研究基于偏置和基于乘法的注意力,我们在 Baichuan 2-7B 上应用 RoPE,而在 Baichuan 2-13B 上应用 ALiBi,与 Baichuan 1 保持一致
ALiBi
外推能力强
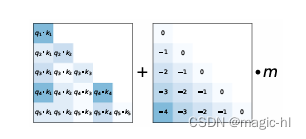
![]() ,加入偏差,m是关于head的系数
,加入偏差,m是关于head的系数
关于ALiBi的讨论:
ALiBi 是一定程度上能解决 Early Token Curse 的问题。
ALiBi 这些还是没有真正的外推性,还是训练多长,推理就多长,只是因为它用的相对位置向量,所以表面上看起来好像能用很长长度进行推理,但实际还是训练时的长度。
Flash Attention
高效利用gpu内存
激活函数和归一化
SwiGLU 激活函数,是 GLU 的变体,有一定效果提升。
RMSNorm
xformers(训练推理加速库)
优化器
使用 AdamW,其中 β1 和 β2 分别设置为 0.9 和 0.95。我们采用了权重衰减(weight decay)为 0.1,并将梯度范数(grad norm)剪裁为 0.5。
BFloat16 混合精度
NormHead
Max-z 损失

















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









