







八、应用机器学习的建议
1. 决定下一步要做什么
假如你现在想用一个常规的线性回归算法去预测房屋的价格,但是你发现预测的结果与实际结果偏差很大,那么你可以考虑下面的这几点:
- 尝试获得更多的数据集去训练模型。
- 尝试减少的特征值,有时可能会因为过拟合导致结果不精确。
- 尝试增加的特征值,有时可能项目太大,但是特征值太少。
- 尝试增加多项式特征(x12,x22,x1x2等)。
- 尝试增加λ值。
- 尝试减小λ值。
当然,有时候你可能做完了项目才发现某些算法并不理想,所以后面的内容将介绍该如何排除一些不适合的算法,并且告诉你上面这些方法可以用来解决哪些问题。
2. 评估假设函数
这节课,我们来讲讲该如何去评估你的假设函数,因为有时候误差很小并不是一件好事,可能是过拟合了,当特征量特别多的时候,就很难通过画图去评估假设函数,所以要用到接下来要讲的方法。

首先,对于数据集的处理,我们可以分为两个部分:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rn0PTBOg-1669855788009)(吴恩达机器学习.assets/image-20211111205202002.png)]](https://img-blog.csdnimg.cn/01f756195721458babf004e0a81bf3e9.png)
一部分为训练集,一部分为测试集,而我们通常将训练集和测试集按照7:3的比例进行划分,这里要注意,所划分的数据集要是随机的。
训练和测试线性回归的步骤:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3sGhmeEb-1669855788011)(吴恩达机器学习.assets/image-20211111205653269.png)]](https://img-blog.csdnimg.cn/cd539d1521c14db48f04122f7a33deae.png)
- 将70%的数据集拿去训练,然后计算出最小的训练误差,得到θ值。
- 计算测试误差。
训练和测试逻辑回归的步骤:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ybvD3KBz-1669855788012)(吴恩达机器学习.assets/image-20211111210207405.png)]](https://img-blog.csdnimg.cn/c4287554d2fb46b78aa70e8bb79d3370.png)
- 将70%的数据集拿去训练,然后计算出最小的训练误差,得到θ值。
- 计算测试误差。
还有一种度量方式是0/1错误分类度量(Misclassification error),可能更好理解一些:
- 当err为1时,说明分类错误即当hθ(x)≥0.5时,将y判断成了0。
- 当err为0时,说明此时分类正确。
3. 模型选择和训练、验证、测试集
这节课我们来看看该如何去选择一个合适的模型,首先先来回顾一下之前的模型选择步骤:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hZOU6V6Y-1669855788013)(吴恩达机器学习.assets/image-20211112113324422.png)]](https://img-blog.csdnimg.cn/ef203b551a674409896230341cceca26.png)
我们之前是用训练集来最小化每一个模型得到θ,然后用同一个训练集来测试哪个误差最小,选出最优的那个模型,而其中出现的d代表的是多项式的阶数。我们假设上面模型中最优的是第五个即d=5,但是这个结果可能过于乐观了,因为它只是针对于训练集训练出的结果,如果放在新样本中可能效果就不会那么好了,所以接下来就要引出验证集了。

为了更好的选择模型,我们现在不再只划分两个数据集,而是三个,分别是训练集、交叉验证集(验证集)和测试集,比例通常在6:2:2,并且选择时也是随机选择的。

接下来就可以分别计算出训练/验证/测试误差,然后进行模型选择。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C6wTo9TQ-1669855788022)(吴恩达机器学习.assets/image-20211112114038240.png)]](https://img-blog.csdnimg.cn/76d1146e7fd04863b276fda41486f4d7.png)
这里和上面不同,虽然还是先用训练集去最小化代价得到θ,但是用于选择模型的数据集变成了验证集,这样就多了一个测试集出来,用于评估所得模型。
4. 诊断偏差和方差
在训练模型的时候,你可能会遇到两种问题,一种就是高偏差问题,一种就是高方差问题,如何判断是否遇到了这两个问题是我们这节课要学的内容,先来看看训练误差和验证误差与多项次数d的关系。
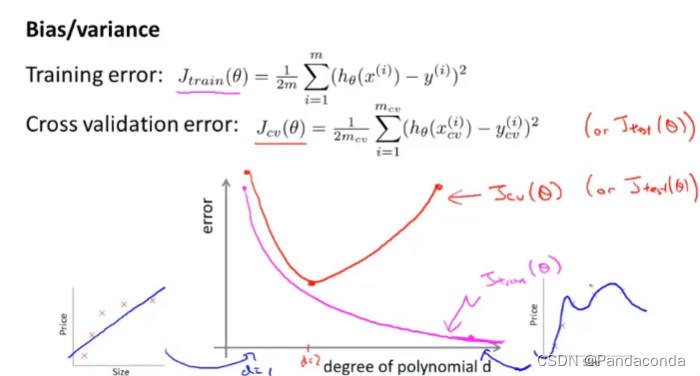
由图中可以看到,当d很小的时候,会处于欠拟合状态,所以训练和验证误差会非常的大,当d很大的时候,训练误差会非常的小因为处于过拟合状态,所以这时候验证误差会变得很大。而在中间能够找到一个合适的d,使验证误差达到最小,所以我们就可以进行总结了。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8duVeRvN-1669855788029)(吴恩达机器学习.assets/image-20211112203833342.png)]](https://img-blog.csdnimg.cn/65d456e43c7945159b8979843b1ecbca.png)
当训练误差和验证误差都很大的时候,处于欠拟合状态,那就是出现了高偏差问题。
当训练误差很小并且远小于验证误差时,处于过拟合状态,那就是出现了高方差问题。
5. 正则化和偏差、方差
这节课我们来更深入的理解一下正则化和偏差、方差的关系,我们先来看看加了正则化的模型该如何去选择。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FKD6Hkyg-1669855788030)(吴恩达机器学习.assets/image-20211112135149044.png)]](https://img-blog.csdnimg.cn/478a76e6db784d2396be5388d5346137.png)
这里选择模型需要我们尝试各个λ的值,然后通过验证集去拟合参数计算验证误差得到最优解,假设我们得到的是θ(5),那么我们就可以像上面讲的一样,用测试集来评估这个选出来的模型如何。
接下来我们来看看λ对于J(θ)的曲线的影响如何。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 858
858











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









