







Java高频面试专题合集解析:

当然在这还有更多整理总结的Java进阶学习笔记和面试题未展示,其中囊括了Dubbo、Redis、Netty、zookeeper、Spring cloud、分布式、高并发等架构资料和完整的Java架构学习进阶导图!

更多Java架构进阶资料展示



- CPU Boost 调度情况。
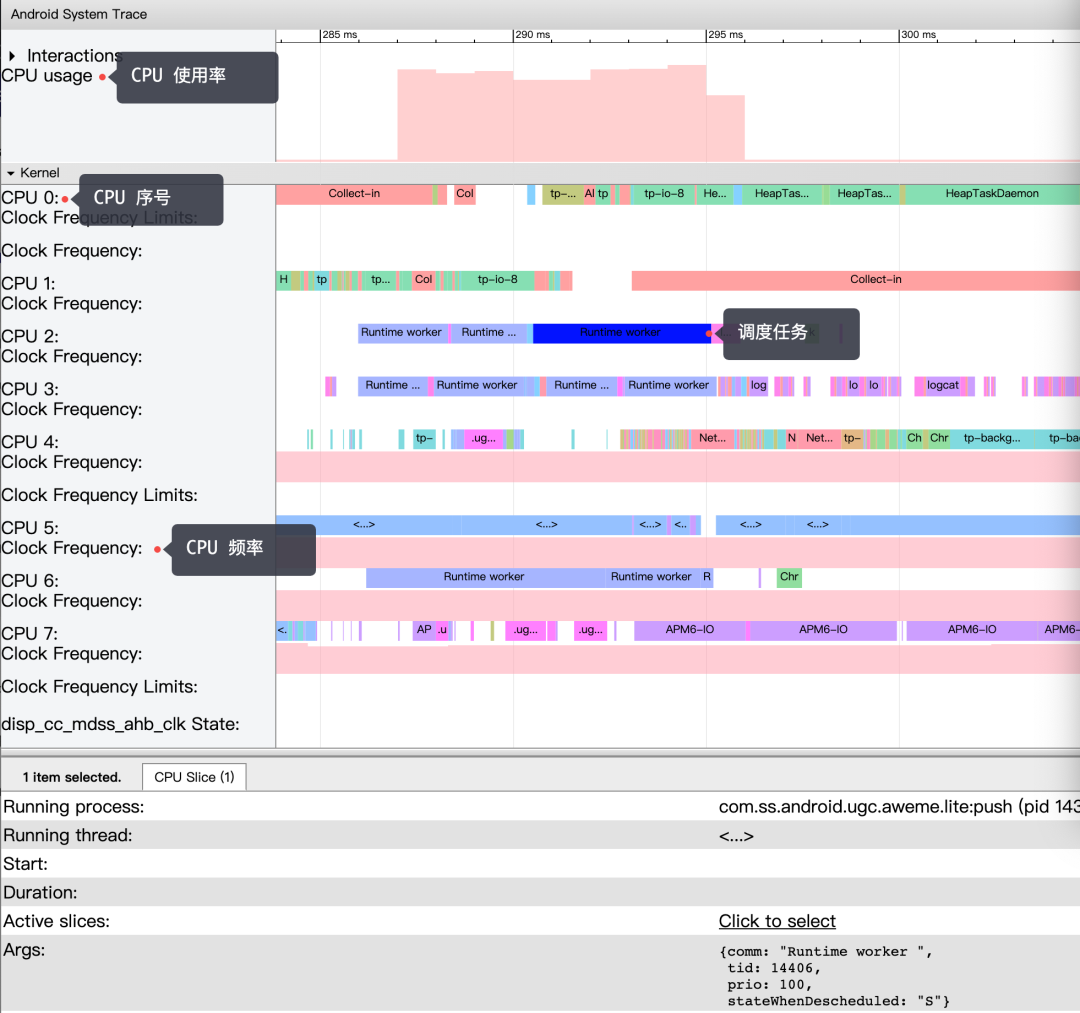
关于图中一些标签释义。
-
CPU 使用率:右边柱状图越高,表明使用率越高。
-
CPU 序号:标识 CPU 核心序号,表示该设备有 8 个核心,编号 0 -7。
-
CPU 频率:右边对应的粉色柱状图表示其频率变化趋势。
-
调度任务:标识在该 CPU 核心上正在运行的任务,点击任务可查看其 ID、优先级等信息。
这些信息 App 可以直接读取 /sys/devices/system/cpu 节点下相关信息获得,而另外一部分标识线程状态信息则只能通过系统或者 adb 才能获取,且这些信息不是统一节点控制,需要激活各自对应的事件节点,让 ftrace 记录下不同事件的 tracepoint。内核在运行时,根据节点的使能状态,会往 ftrace 缓冲中记录事件。
例如,激活线程调度状态信息记录,需要激活类似如下相关节点。
events/sched/sched_switch/enable
events/sched/sched_wakeup/enable
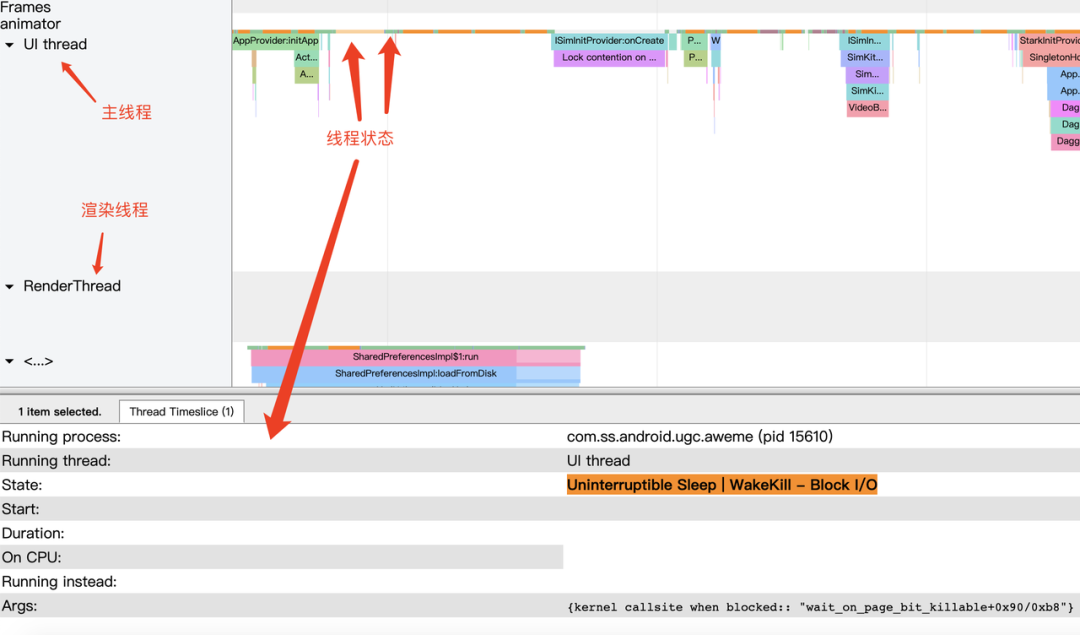
激活后,则可以获取到线程调度状态相关的信息,比如:
-
Running: 线程在正常执行代码逻辑。
-
Runnable: 可执行状态,等待调度,如果长时间调度不到,说明 CPU 繁忙。
-
Sleeping: 休眠,一般是在等待事件驱动。
-
Uninterruptible Sleep: 不可中断的休眠,需要看 Args 描述来确定当时状态。
-
Uninterruptible Sleep - Block I/O: IO 阻塞。
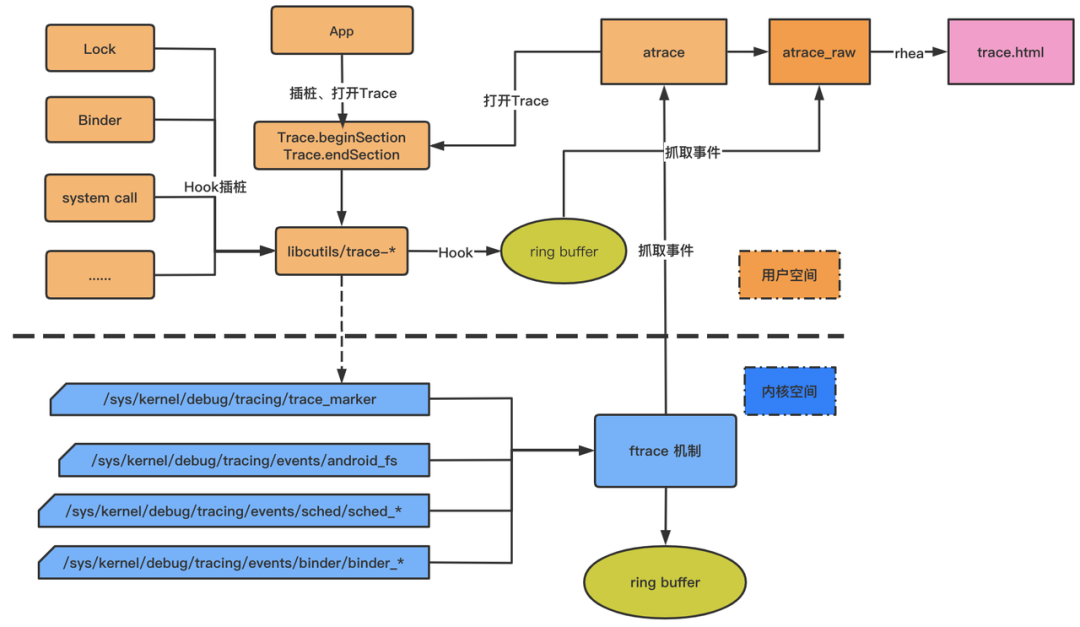
最终,上述两大类事件记录都汇集到内核态同一缓冲中, Systrace 工具是通过指定抓取 trace 类别等参数,然后触发手机端 /system/bin/atrace 开启对应文件节点信息,接着 atrace 会读取 ftrace 缓存,生成只包含 ftrace 信息的 atrace_raw 信息,最终通过脚本转换成可视化 HTML 文件,大致流程如下。
RheaTrace 揭秘
本章节将从 RheaTrace 重点优势一一介绍。
Systrace 源码分析
Systrace 提供 Trace#beginSection(String) 和 Trace.endSection() 采集 atrace 数据,首先,我们大致了解下 atrace 工作原理,以 android.os.Trace#beginSection 作为分析入口。
public static void beginSection(@NonNull String sectionName) {
if (isTagEnabled(TRACE_TAG_APP)) {
if (sectionName.length() > MAX_SECTION_NAME_LEN) {
throw new IllegalArgumentException(“sectionName is too long”);
}
nativeTraceBegin(TRACE_TAG_APP, sectionName);
}
}
android.os.Trace#beginSection 会调用 nativeTraceBegin 方法,该方法实现参考 frameworks/base/core/jni/android_os_Trace.cpp。
static void android_os_Trace_nativeTraceBegin(JNIEnv* env, jclass,
jlong tag, jstring nameStr) {
withString(env, nameStr, tag {
atrace_begin(tag, str);
});
}
atrace_begin 方法实现参考 system/core/libcutils/include/cutils/trace.h。
#define ATRACE_BEGIN(name) atrace_begin(ATRACE_TAG, name)
static inline void atrace_begin(uint64_t tag, const char* name)
{
if (CC_UNLIKELY(atrace_is_tag_enabled(tag))) {
void atrace_begin_body(const char*);
atrace_begin_body(name);
}
}
atrace_begin_body 方法实现参考 system/core/libcutils/trace-dev.cpp。
void atrace_begin_body(const char* name)
{
WRITE_MSG(“B|%d|”, “%s”, name, “”);
}
atrace_begin_body 最终实现在宏 WRITE_MSG 实现,代码如下:
#define WRITE_MSG(format_begin, format_end, name, value) { \
…
write(atrace_marker_fd, buf, len); \
}
通过 WRITE_MSG 实现,可知,atrace 数据是实时写入 fd 为 atrace_marker_fd 的文件中,如果多线程同时写入,则会出现锁问题,导致性能损耗加大。
RheaTrace 核心优势
效率提升
RheaTrace 会在 App 编译期间自动插入 Trace 跟踪函数,大大提高效率。针对不同 Android Gradle Plugin 版本,我们支持 Proguard 之后插桩,这样可以减少 App 方法插桩量,同时也过滤 Empty、Set/Get 等简单方法。
思路基于 matrix-gradle-plugin 大量改造实现。
rheaTrace {
compilation {
//为每个方法生成唯一 ID,若为 true,Trace#beginSection(String) 传入的是方法 ID。
traceWithMethodID = true
//决定哪些包名下的类您不需要做性能跟踪。
traceFilterFilePath = “${project.rootDir}/rhea-trace/traceFilter.txt”
//一些特定方法保持 ID 值固定不变。
applyMethodMappingFilePath = “${project.rootDir}/rhea-trace/keep-method-id.txt”
}
runtime {
…
}
}
-
为减少包体积、性能影响,我们也借鉴 matrix 慢函数思路,支持为每个函数生成唯一 ID,
traceWithMethodID为 true,Trace#beginSection(String)传入的是方法 ID,不再是方法名。有时候我们想某些方法 ID 固定不变,同样借鉴 matrix 慢函数思路,我们提供applyMethodMappingFilePath配置规则文件路径。 -
为进一步减少 App 方法插桩量,我们提供
traceFilterFilePath文件配置让您决定哪些包、类、方法不做自定义事件跟踪,关于其用法请参考 RheaTrace Gradle Config。
性能提升
在 Systrace 概述中,我们了解到 atrace 数据是实时写入文件,且存在多线程同时写入带来的锁问题。因此,我们采取策略是拿到 atrace 文件 fd,在 atrace 数据写入前,先将其写至 LockFreeRingBuffer内存中,然后再将循环读取内存中 atrace 数据,写入我们定义的文件中。
首先我们通过 dlopen 获取 libcutils.so 对应句柄,通过对应 symbol 从中找到 atrace_enabled_tags 和 atrace_marker_fd 对应指针,设置 atrace_enabled_tags 用以打开 atrace,代码实现片段如下。
int32_t ATrace::InstallAtraceProbe() {
…
{
std::string lib_name(“libcutils.so”);
std::string enabled_tags_sym(“atrace_enabled_tags”);
std::string marker_fd_sym(“atrace_marker_fd”);
…
…
atrace_marker_fd_ = reinterpret_cast<int*>(
dlsym(handle, marker_fd_sym.c_str()));
if (atrace_marker_fd_ == nullptr) {
ALOGE(“‘atrace_marker_fd’ is not defined”);
dlclose(handle);
return INSTALL_ATRACE_FAILED;
}
if (*atrace_marker_fd_ == -1) {
*atrace_marker_fd_ = kTracerMagicFd;
}
dlclose(handle);
return OK;
}
思路参考 profilo#installSystraceSnooper,本文不做过多介绍。
接着,通过 PLT Hook libcutils.so 中 write、write_chk 方法,判定该方法传入 fd 是否与 atrace_marker_fd 一致,若一致,则将 atrace 数据写入我们定义的文件中。
ssize_t proxy_write(int fd, const void* buf, size_t count) {
BYTEHOOK_STACK_SCOPE();
if (ATrace::Get().IsATrace(fd, count)) {
ATrace::Get().LogTrace(buf, count);
return count;
}
…
ATRACE_END();
return ret;
}
有时候,我们可能仅需要关注主线程 atrace 数据,如果能将子线程 atrace 数据过滤掉,那么整体性能将进一步提升。一种很简单的思路,就是将 Trace#beginSection(String) 包装一层,如下代码片段。
static void t(String methodId) {
if (!isMainProcess) {
return;
}
if (mainThreadOnly) {
if (Thread.currentThread() == sMainThread) {
Trace.beginSection(methodId);
}
} else {
Trace.beginSection(methodId);
}
}
该方法仅能过滤我们为 App 方法插桩的 atrace 数据,系统层 atrace 数据无法过滤。为更彻底实现仅采集主线程数据,我们通过 PLT Hook 代理 atrace_begin_body 和 atrace_end_body 实现,在该方法进入前,判断当前线程 id 是否为主线程,如果不是,则不记录该条数据,代码实现片段如下。
void proxy_atrace_begin_body(const char *name) {
BYTEHOOK_STACK_SCOPE();
if (gettid() == TraceProvider::Get().GetMainThreadId()) {
BYTEHOOK_CALL_PREV(proxy_atrace_begin_body, name);
}
}
void proxy_atrace_end_body() {
BYTEHOOK_STACK_SCOPE();
if (gettid() == TraceProvider::Get().GetMainThreadId()) {
BYTEHOOK_CALL_PREV(proxy_atrace_end_body);
}
}
针对降低性能损耗,RheaTrace 提供编译配置供用户选择,针对不同使用场景配置合理参数。
rheaTrace {
…
runtime {
mainThreadOnly false
startWhenAppLaunch true
atraceBufferSize “500000”
}
}
上述配置释义如下。
-
mainThreadOnly:为 true 表示仅采集主线程 trace 数据。 -
startWhenAppLaunch:是否 App 启动开始就采集 trace 数据。 -
atraceBufferSize:指定内存存储 atrace 数据 ring buffer 的大小,如果其值过小会导致 trace 数据写入不完整,若您抓取多线程 trace 数据,建议将值设为百万左右量级;最小值为 1 万,最大值为 5 百万。
实用性提升
针对已有的 atrace 数据,额外拓展 IO 等信息;另外为通过 Python 脚本彻底解决方法因执行异常导致 trace 数据闭合异常问题,保证每个方法 trace 数据的准确性。
目前我们基于 JVMTI 方案,在 Android 8.0 及以上设备可以获取类加载以及内存访问相关 trace 数据,目前仅支持编译类型为 debuggable 的 App,目前处于实验功能,本文暂先不过多介绍。
IO 数据拓展
背景简介
在抖音启动性能优化时,我们曾统计冷启动的耗时,其中占比最长的是进程处于 D 状态(不可中断睡眠态,Uninterruptible Sleep ,通常我们用 PS 查看进程状态显示 D,因此俗称 D 状态)时间。此部分耗时占总启动耗时约 40%,进程为什么会被置于 D 状态呢?处于 uninterruptible sleep 状态的进程通常是在等待 IO,比如磁盘 IO,其他外设 IO,正是因为得不到 IO 响应,进程才进入 uninterruptible sleep 状态,所以要想使进程从 uninterruptible sleep 状态恢复,就得使进程等待 IO 恢复,类似如下。

但在使用 Systrace 进行优化时仅能得到如上内核态的调用状态,却无法得知具体的 IO 操作是什么。
方案介绍
因此,我们专门设计一套获取 IO 耗时信息方案,其包括用户空间和内核空间两部分。
一是在用户空间,为采集所需 IO 耗时信息,我们通过 Hook IO 操作标准函数簇,包括 open,write,read,fsync,fdatasync 等,插入对应 atrace 埋点用于统计对应的 IO 耗时,以 fsync 为例。

其对应 hook 代码逻辑如下:
int proxy_fsync(int fd) {
BYTEHOOK_STACK_SCOPE();
ATRACE_BEGIN_VALUE(“fsync:”, FileInfo(fd).c_str());
int ret = BYTEHOOK_CALL_PREV(proxy_fsync, fd);
ATRACE_END();
return ret;
}
二是在内核空间,除 systrace 或 atrace 可直接支持启用功能外,ftrace 还提供其他功能,并包含对调试性能问题至关重要的一些高级功能(需要 root 访问权限,通常也可能需要新内核)。我们基于此添加显示定制 IO 信息等功能,开启/sys/kernel/debug/tracing/events/android_fs节点下 ftrace 信息,用于收集 IO 相关的信息。内核空间 IO 信息是通过 python 脚本开启,详见 io_extender.py。
解决方法闭合错误问题
背景介绍
RheaTrace 会自动在每个方法入口、出口处分别插入 Trace#beginSection(String) 和 Trace#endSection() ,一个方法有且只有一个入口,但会有多个出口,方法出口对应的结束字节码指令有 return 和 throw 等。
public static void testCrash() {
try {
testA();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void testA() {
testB();
testC();
}
public static void testB() {
int ret = 2 / 0; // <----- crash event
testD(ret);
}
public static void testC() {
Log.d(“btrace”, “do some things.”);
}
public static void testD(int num) {
Log.d(“btrace”, "box size: " + num);
}
上面的代码很简单,即 testCrash -> testA -> testB,其中 testB 出现异常,最终是在 testCrash 中捕获。通过本示例可知,testA、testB 方法出口均未正常执行完成,这也就导致 trace 数据不闭合,生成的 trace 数据如下,从中可以看出,B 和 E 数量上并不匹配,且仅从 trace 上看,我们也无法知道 E 属于哪个方法。
5108949.231989: B|28045| TestCrash:a
5108949.232055: B|28045| TestCrash:b
5108949.232554: B|28045| TestCrash:c
5108949.232580: E|28045
方案介绍
为解决该问题,RheaTrace 做了取巧处理,方法的出口由插入 Trace#endSection()改为 Trace#beginSection(String)。那我们如何知道哪条 trace 是开始,哪条是结束?我们看如下示例。
5108949.231989: B|28045|B:TestCrash:a
5108949.232055: B|28045|B:TestCrash:b
5108949.232554: B|28045|B:TestCrash:c
5108949.232580: B|28045|E:TestCrash:a
如上 trace 数据,每个方法描述前都会加上 B: 或 E、T, B: 表示方法开始,E 表示方法 retrun 结束,T: 表示方法 throw 结束。然后通过 Python 脚本处理并还原正常 trace 数据。如此做以后,我们就可以明确知道方法开始和结束,同时针对异常结束方法,我们会做补全处理,处理后的 trace 数据如下。
5108949.231989: B|28045|TestCrash:a
5108949.232055: B|28045|TestCrash:b
5108949.232554: B|28045|TestCrash:c
5108949.232554: E|28045|TestCrash:c
5108949.232554: E|28045|TestCrash:b
5108949.232580: E|28045|TestCrash:a
关于 Python 脚本的处理过程,本文不做过多介绍,大家可以阅读相关源码即可。
RheaTrace 工作流程
流程概述
RheaTrace 作为线下性能分析利器,我们首先看下其整体工作流程。

最近我根据上述的技术体系图搜集了几十套腾讯、头条、阿里、美团等公司21年的面试题,把技术点整理成了视频(实际上比预期多花了不少精力),包含知识脉络 + 诸多细节,由于篇幅有限,这里以图片的形式给大家展示一部分

5: B|28045|TestCrash:b
5108949.232554: B|28045|TestCrash:c
5108949.232554: E|28045|TestCrash:c
5108949.232554: E|28045|TestCrash:b
5108949.232580: E|28045|TestCrash:a
关于 Python 脚本的处理过程,本文不做过多介绍,大家可以阅读相关源码即可。
RheaTrace 工作流程
流程概述
RheaTrace 作为线下性能分析利器,我们首先看下其整体工作流程。
[外链图片转存中…(img-qKfTgzs6-1715069605946)]
最近我根据上述的技术体系图搜集了几十套腾讯、头条、阿里、美团等公司21年的面试题,把技术点整理成了视频(实际上比预期多花了不少精力),包含知识脉络 + 诸多细节,由于篇幅有限,这里以图片的形式给大家展示一部分
[外链图片转存中…(img-jluK1Au0-1715069605946)]















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









