







内容:
·nan?
·优化None
·过滤nan
·填充nan
# pandas里面的空值是一个浮点类型,而python里面的空值,是一个对象类型
# 导包
import pandas as pd
import numpy as np
from pandas import Series, DataFrame
【nan】
pandas里面的空值是一个浮点类型,而python里面的空值,是一个对象类型
# nan不能参与运算,不是一个数值,只是一个展示符号
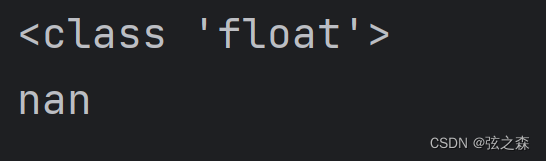
# 创建一个nan:
print(type(np.nan))
print(np.nan)
# 强制类型统一numpy
print()
运行结果:
【优化nan】
pandas的所有对象,都会将python中原有的None,优化成NaN
给pandas对象的某一个元素赋值为None,解释器会自动将其优化为NaN。
# pandas的所有对象,都会将python中原有的None,优化成NaN
# Series数组:
ser = Series(data=np.random.randint(0, 100, size=4), index=list("ABCD"))
print(ser)
# 给Series数组中某个数赋值为None,pandas对象会将None自动优化为NaN:
ser.loc["A"] = None
print(ser)运行结果:
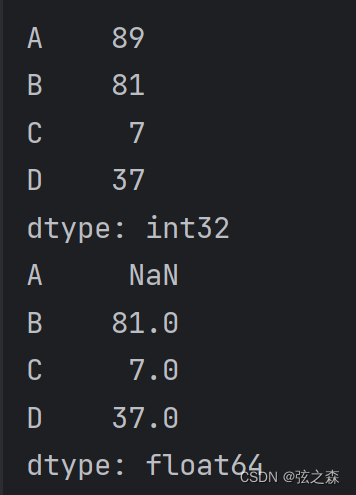
调用DataFrame的“.dtypes”方法,可以查看每一列元素的类型。
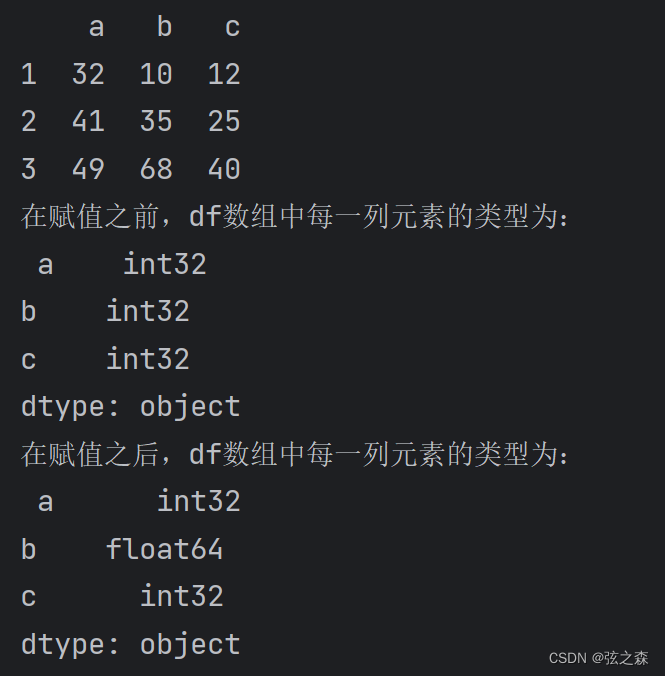
# DataFrame数组:
df = DataFrame(data=np.random.randint(0, 100, size=(3, 3)), columns=list("abc"), index=list("123"))
print(df)
# .dtypes函数可以查看每一列的数据元素类型:
print("在赋值之前,df数组中每一列元素的类型为:\n", df.dtypes)
df.loc["2", "b"] = None
print("在赋值之后,df数组中每一列元素的类型为:\n", df.dtypes)
print()运行结果:
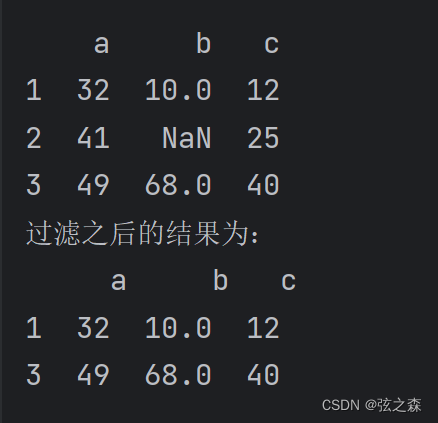
【过滤nan】
过滤函数.dropna():默认删除nan所在的行
"""过滤函数.dropna():默认删除行"""
print(df)
print("过滤之后的结果为:\n", df.dropna())
# 对于一个二维表格来讲,它的列方向是字段,行方向是数据
print()运行结果:
【填充nan】
(用一个数填充nan)
用一个数替换掉NaN:
在这种填充方式中,会将数组中所有的NaN替换成value传入的参数
注意:此处被填充的数字是10
# 用一个数替换掉NaN:
# 在这种填充方式中,会将数组中所有的NaN替换成value传入的参数
df = df.fillna(value=10)
print("用3填充掉NaN:\n", df)运行结果:

(使用每一列的某一个聚合指标对该列的nan进行填充)
使用每一列的某一个聚合指标来对每一列进行填充
原理:一个简单的DataFrame和Series数组的运算问题,在传入参数之后,会进行索引对齐,将NaN替换掉
# 使用每一列的某一个聚合指标来对每一列进行填充
# 原理:一个简单的DataFrame和Series数组的运算问题,在传入参数之后,会进行索引对齐,将NaN替换掉
df.loc["1", "a"] = np.nan
df.loc["2", "c"] = np.nan
df.loc["3", "b"] = np.nan
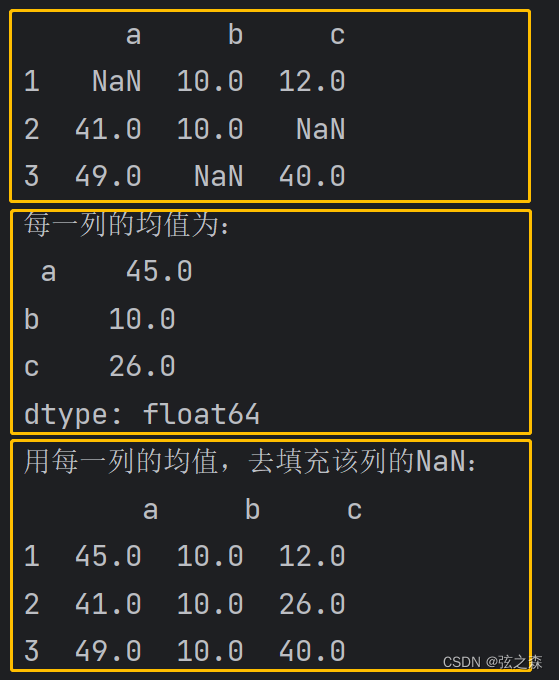
print(df)
print("每一列的均值为:\n", df.mean(),
"\n用每一列的均值,去填充该列的NaN:\n", df.fillna(value=df.mean()))运行结果:
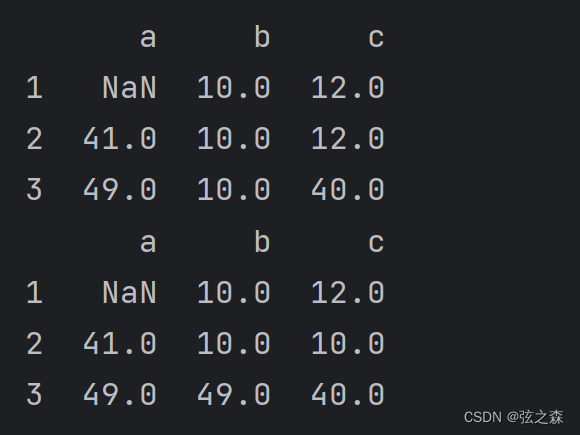
(axis=0/1,填充)
对于DataFrame数组,
axis=0:index/列
axis=1:columns/行
当axis=0时,在填充时会将表格按列看,每一列依次去填充
当axis=1时,在填充时会将表格按行看,每一行依次去填充
# 将NaN填充为其之前的值
print(df.fillna(axis=0, method='ffill'))
print(df.fillna(axis=1, method='ffill'))运行结果:
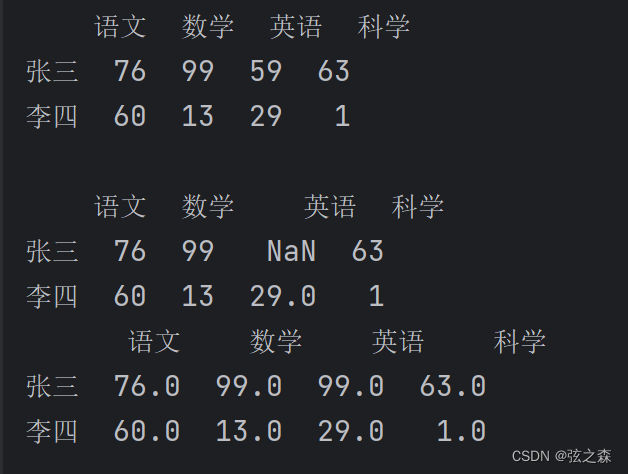
【练习】
columns = ["语文", "数学", "英语", "科学"]
index = ["张三", "李四"]
every_grade = DataFrame(data=np.random.randint(0, 100, size=(2, 4)), index=index, columns=columns)
print(every_grade)
print()
every_grade.loc["张三", "英语"] = np.nan
print(every_grade)
# 用数学成绩作为英语成绩,将nan填充
print(every_grade.fillna(axis=1, method="ffill"))
运行结果:
















 964
964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











