







import numpy as np
import pandas as pd
from pandas import Series, DataFrame内容:
·多层级索引
·构造多层级索引
【多层级索引】
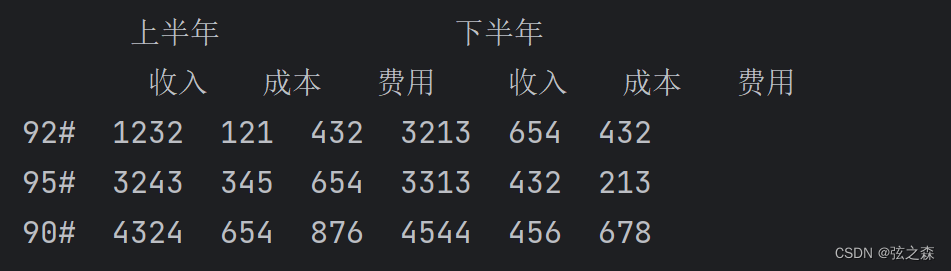
df = pd.read_excel("C:/Users/YHT/Desktop/数据.xlsx", header=[0, 1], index_col=[0])
print(df)
print()运行结果:
【构造多层级索引】
(概念)
构造多层级索引
构造多层级索引,主体就和构造DataFrame数组一样,确定data、columns(列索引)、index(行索引)
如果要将列索引构建为多层级,那么其余步骤不变,列索引columns要调用方法重新构造
通俗点说,构造多层级索引,就是构建一个新的行/列索引
(构造方法)
(一)
这里以构造多层列索引为例:
在pd.MultiIndex.from_product()中,传入参数为一个列表,该列表中的元素(列表)等级依次减小
其中,from_product()代表相乘关系:
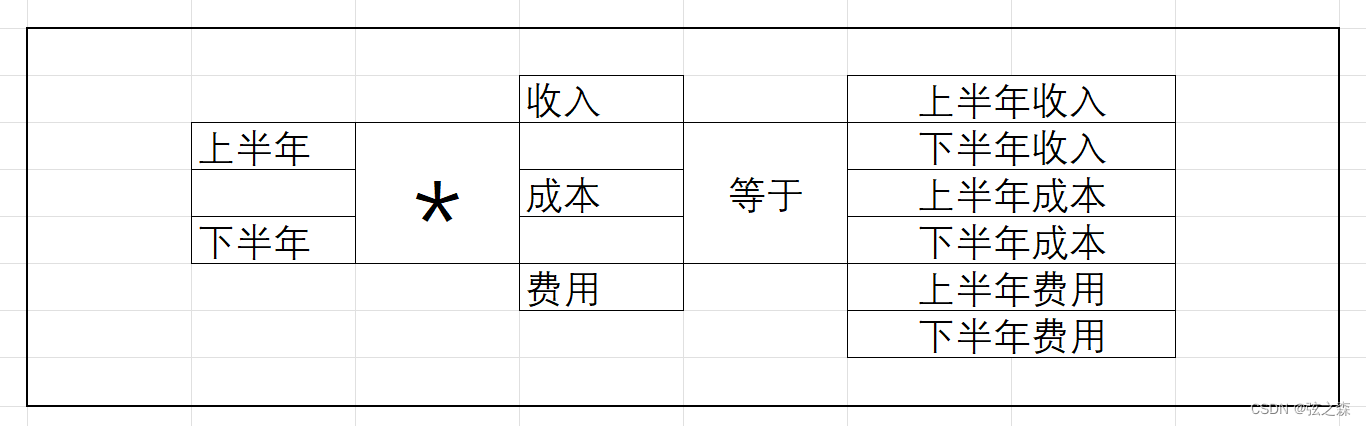
columns = pd.MultiIndex.from_product([["上半年", "下半年"], ["收入", "成本", "费用"]])
print(columns)
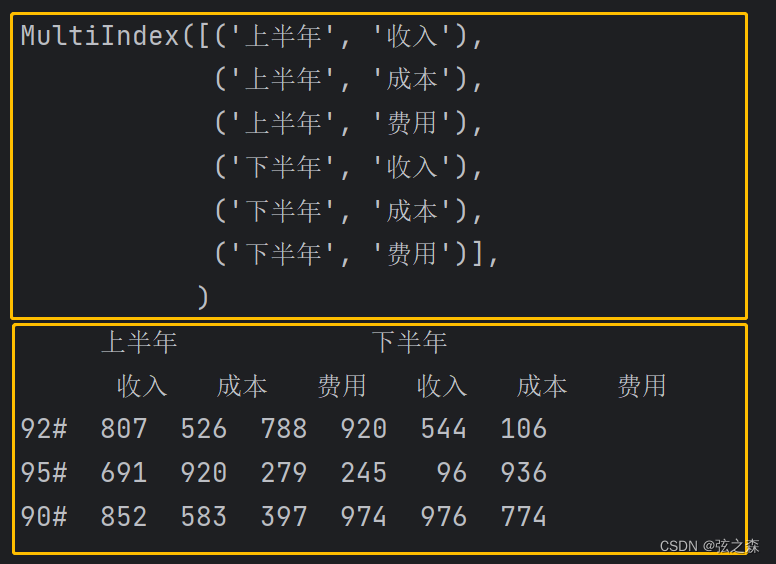
data = np.random.randint(0, 1000, size=(3, 6))
index = ["92#", "95#", "90#"]
df_things = DataFrame(data=data, index=index, columns=columns)
print(df_things)运行结果:
(二)
# 使用tuple元组:
tuples = (("上半年", "收入"), ("上半年", "成本"), ("上半年", "费用"), ("下半年", "收入"), ("下半年", "成本"), ("下半年", "费用"))
columns = pd.MultiIndex.from_tuples(tuples)
















 1181
1181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











