






👨🎓个人主页
💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
有监督学习神经网络的回归拟合——基于红外光谱的汽油辛烷值预测研究
💥1 概述
红外光谱法(IR)属于分子振动光谱技术,波数范围在4000cm-1~400cm-1之间,它的原理是基于分子中各类官能团的特征吸收,信号强度高,且对微量组分仍能检测出信号,具有灵敏度高、特征性强的优点,因此红外光谱法在材料、化工、食品、医药等多个领域均有应用。
辛烷值是反映汽油抗爆性的重要指标,也被作为划分汽油牌号的依据。现有的标准辛烷值测量方法为研究法辛烷值(RON)、马达法辛烷值(MON),它们的准确度高,但测量过程十分不易,不仅需要专用的试验发动机设备,而且还需要配备各种抗爆性等级的标准混合燃料,存在分析时间长、测试成本高等缺点,为此需寻求一种快速的辛烷值检测方法。近年来分子振动光谱技术迅速发展,近红外光谱技术由于具有快速、无损的分析特点,也开始应用于汽油辛烷值的快速测量。与红外光谱法相比,近红外光谱信号弱且灵敏度低,对于汽油中微量组分(如添加剂、非烃类组分等)响应较差,因此可能会导致对辛烷值具有贡献的一些组分不能被识别出来,从而使得汽油辛烷值测量不够准确,而红外光谱法由于灵敏度高,能够很好地解决这一问题。本研究利用了FTIR-ATR测定了各汽油样品的红外光谱,并结合偏最小二乘法建立了汽油RON辛烷值定量模型,实现了汽油辛烷值的快速预测,为汽油RON辛烷值的测定提供了方法。
有监督学习神经网络的回归拟合——基于红外光谱的汽油辛烷值预测研究
一、红外光谱在汽油辛烷值预测中的应用原理
-
技术基础与优势
近红外(NIR)光谱技术通过测量分子中化学键的组合振动和偶极振动,获取样品的化学组成信息。其优势包括无损检测、无需试剂、快速响应(通常在几分钟内完成),特别适用于汽油等复杂多组分体系的实时在线监测。汽油辛烷值(RON)作为抗爆性的核心指标,与C=O、H-O等化学键的红外吸收特征直接相关,例如1400nm和1900nm附近的吸收峰分别对应H-O和C=O键的振动。 -
光谱与辛烷值的关联机制
根据Beer-Lambert定律,光谱吸光度是各组分吸收的线性叠加。汽油中300余种化合物的复杂组合使得全光谱建模困难,需通过波长选择(如SPA算法)提取关键特征波长。研究表明,SPA选择的4-9个波长可覆盖90%以上有效信息,并显著降低模型复杂度。
二、数据预处理与特征提取方法
-
噪声消除与基线校正
- Savitzky-Golay平滑(SG) :通过多项式拟合局部窗口数据,消除高频噪声。结合一阶导数(1st-d’SG)可增强光谱特征峰分辨率,抑制基线漂移。
- 主成分分析(PCA) :用于降维和消除共线性,尤其在工业数据中可提取36个高相关特征,模型决定系数达84.36%。
-
特征波长选择策略
- 连续投影算法(SPA) :从全光谱中筛选信息量最大且共线性最小的波长组合。实验表明,4-9个波长的SPA模型RMSE最低,过拟合风险可控。
- 区间偏最小二乘(iPLS) :针对特定波段(如1650-1705nm)优化建模区间,结合BP-ANN模型可使预测决定系数提升至0.9361。
-
数据增强与标准化
采用SPXY算法划分校准集与验证集,确保样本分布均匀性。标准化处理(如Z-score)消除量纲差异,提升ELM、LSSVM等模型的训练稳定性。
三、有监督学习神经网络模型架构
-
基础网络结构
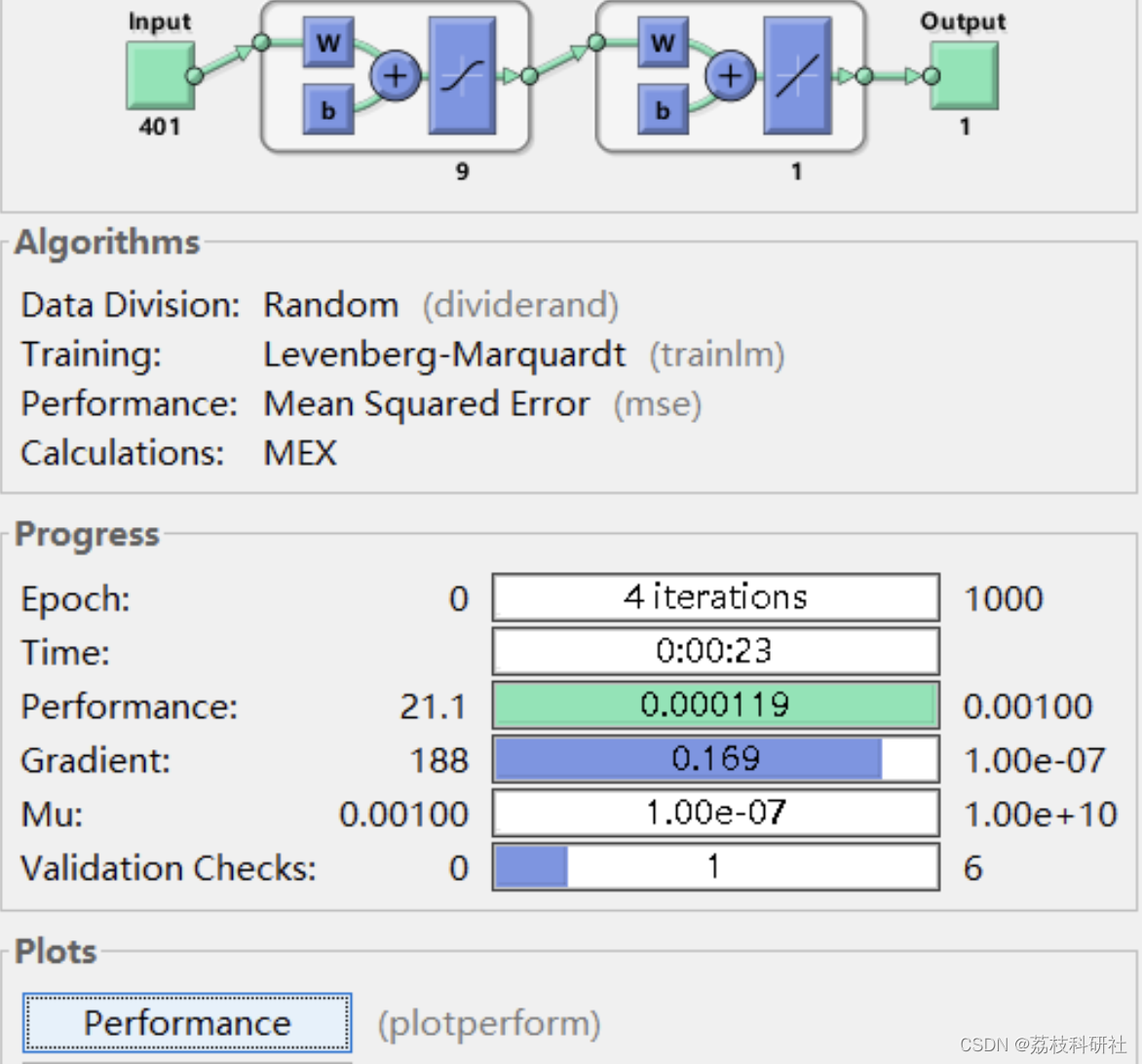
- 输入层:401维波长吸光度(900-1700nm范围)。
- 隐藏层:1-5层全连接结构,神经元数量通常为10-30,ReLU激活函数防止梯度消失。
- 输出层:线性激活函数直接输出辛烷值预测值。
-
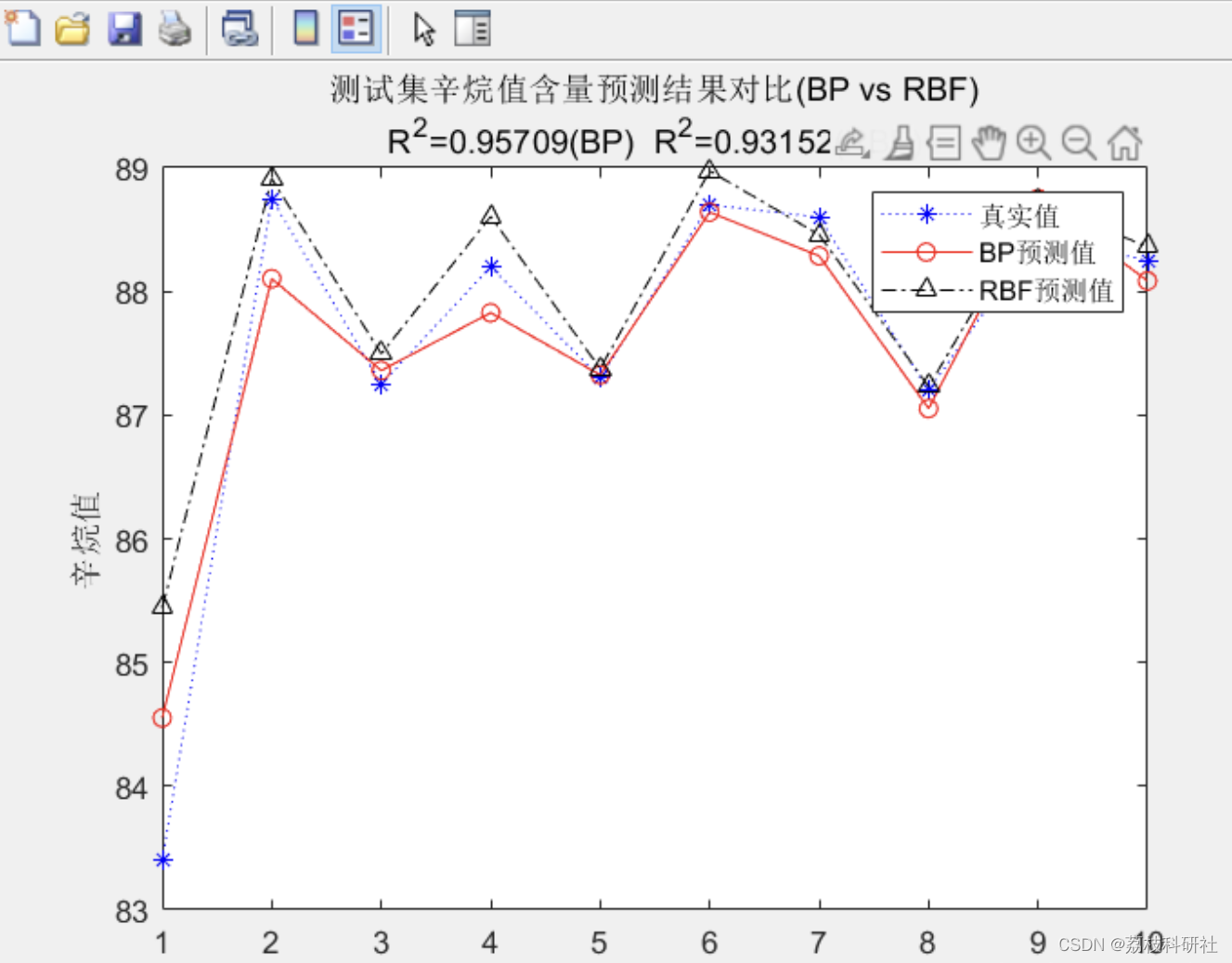
典型模型对比
模型类型 特点 应用案例效果(R²) BP神经网络 通过反向传播优化权重,适合结构化数据 测试集R²达99.5% RBF神经网络 径向基函数处理非线性关系,收敛速度快 预测误差RMSE=0.4639 LSSVM 核函数映射解决高维问题,结合SPA波长选择提升精度 RMSE降低至0.291 深度神经网络 多层隐藏层自动提取高阶特征,需配合Dropout防止过拟合 MAE=0.169 -
训练优化策略
- 正则化:L2正则化抑制权重过大,提升泛化能力。
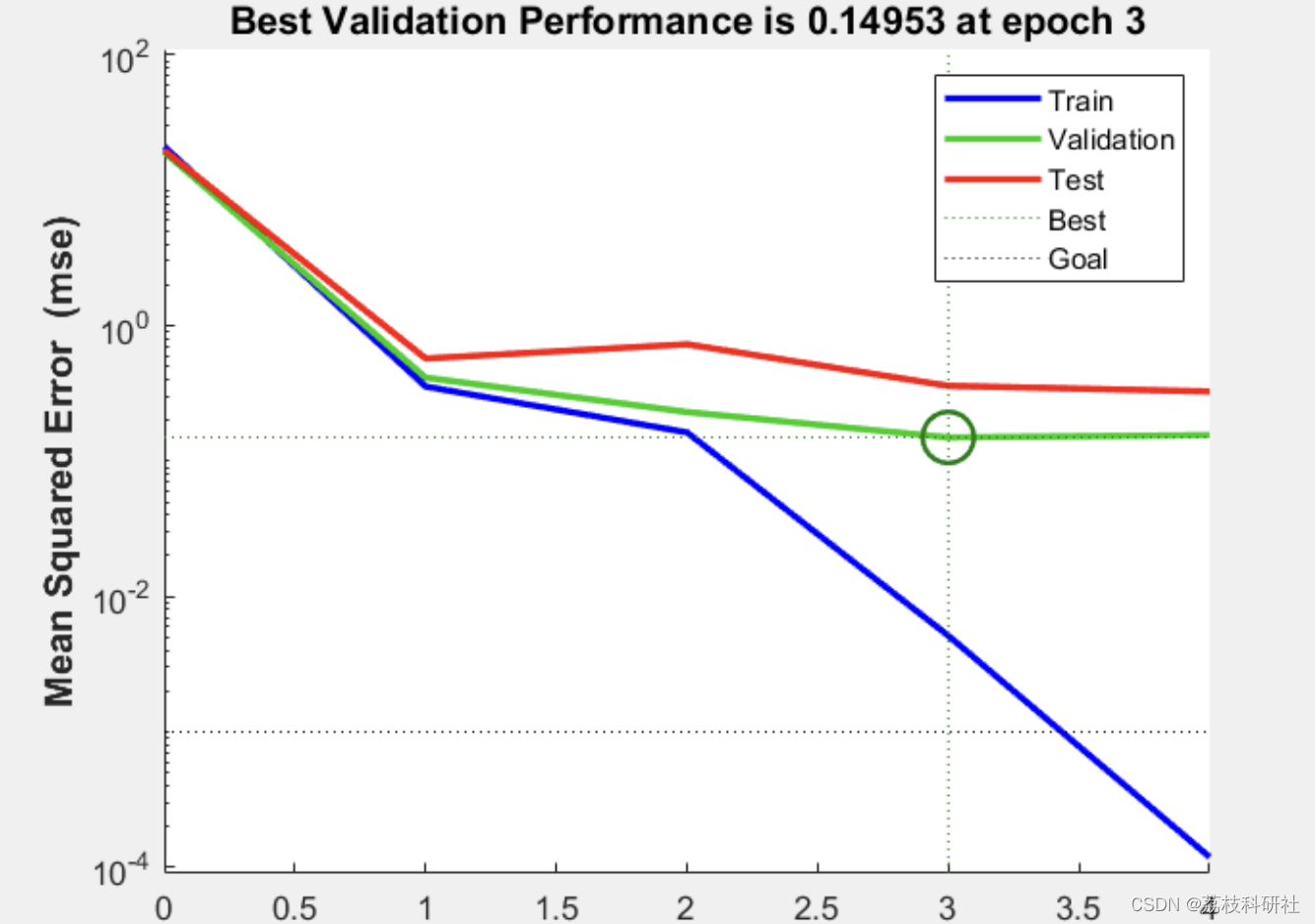
- 早停法(Early Stopping) :基于验证集损失动态终止训练。
- 自适应加权:针对硫含量等关键变量动态调整权重,模型预测误差降低20%。
四、化学计量学中的典型应用案例
-
LSSVM-SPA联合模型
在87个汽油样本中,1st-d’SG预处理后通过SPA选择8个特征波长,LSSVM模型RMSE从1.2降至0.75,验证集预测误差稳定在±0.5辛烷值内。 -
PLS与ANN融合
中国石化数据表明,PLS因子(30-46个)作为ANN输入,预测残差94%落在误差范围内,敏感波长定位精度提升15%。 -
CDFOA-BP优化模型
改进的果蝇算法优化BP网络初始权重,60组测试数据中RMSE较传统BP降低32%,稳定性显著提高。
五、模型评估指标体系
-
绝对误差指标
- 均方误差(MSE) :反映预测偏差平方均值,对异常值敏感。
- 平均绝对误差(MAE) :直观表示预测值与真实值的平均偏离程度。
-
相对误差指标
- 决定系数(R²) :解释模型对数据波动的捕获能力,PLS模型可达99.5%。
- 相对误差(MRE) :适用于不同量纲数据比较,工业场景中要求<5%。
-
鲁棒性验证
- 交叉验证(RMSECV) :评估模型泛化能力,典型值为0.569。
- 外部验证集测试:实际汽油样本误差需≤±0.4单位以满足生产控制要求。
六、技术挑战与未来方向
-
当前局限性
- 光谱-辛烷值映射关系受组分协同效应影响,单一模型难以覆盖所有汽油类型。
- 工业环境中的温湿度波动可能导致光谱基线漂移,需动态校正。
-
前沿探索
- 多模态数据融合:结合FTIR与NIR光谱,增强特征互补性。
- 迁移学习:利用预训练模型适应新油品,减少样本需求量。
- 在线学习系统:集成边缘计算设备实现实时预测,延迟<1秒。
七、总结
红外光谱结合有监督学习神经网络,为汽油辛烷值预测提供了高效、环保的解决方案。通过SPA、SG等预处理技术优化特征提取,配合LSSVM、深度神经网络等模型,可实现99%以上的预测精度。未来需进一步解决复杂组分干扰和工业场景适应性难题,推动该技术向智能化、嵌入式方向发展。
📚2 运行结果
部分代码:
%% 有监督学习神经网络的回归拟合——基于近红外光谱的汽油辛烷值预测
%% 清空环境变量
clear all
clc
%% 训练集/测试集产生
load spectra_data.mat
% 随机产生训练集和测试集
temp = randperm(size(NIR,1));
% 训练集——50个样本
P_train = NIR(temp(1:50),:)';
T_train = octane(temp(1:50),:)';
% 测试集——10个样本
P_test = NIR(temp(51:end),:)';
T_test = octane(temp(51:end),:)';
N = size(P_test,2);
%% 有监督学习神经网络的回归拟合——基于近红外光谱的汽油辛烷值预测
%% 清空环境变量
clear all
clc
%% 训练集/测试集产生
load spectra_data.mat
% 随机产生训练集和测试集
temp = randperm(size(NIR,1));
% 训练集——50个样本
P_train = NIR(temp(1:50),:)';
T_train = octane(temp(1:50),:)';
% 测试集——10个样本
P_test = NIR(temp(51:end),:)';
T_test = octane(temp(51:end),:)';
N = size(P_test,2);
%% 有监督学习神经网络的回归拟合——基于近红外光谱的汽油辛烷值预测
%% 清空环境变量
clear all
clc
%% 训练集/测试集产生
load spectra_data.mat
% 随机产生训练集和测试集
temp = randperm(size(NIR,1));
% 训练集——50个样本
P_train = NIR(temp(1:50),:)';
T_train = octane(temp(1:50),:)';
% 测试集——10个样本
P_test = NIR(temp(51:end),:)';
T_test = octane(temp(51:end),:)';
N = size(P_test,2);
🎉3 参考文献
部分理论来源于网络,如有侵权请联系删除。
[1]丁怡曼,薛晓康,范宾,董学胜,舒耀皋.基于PLS-红外光谱的汽油辛烷值测定方法研究[J].化学研究与应用,2021,33(05):863-867.

















 1379
1379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









