







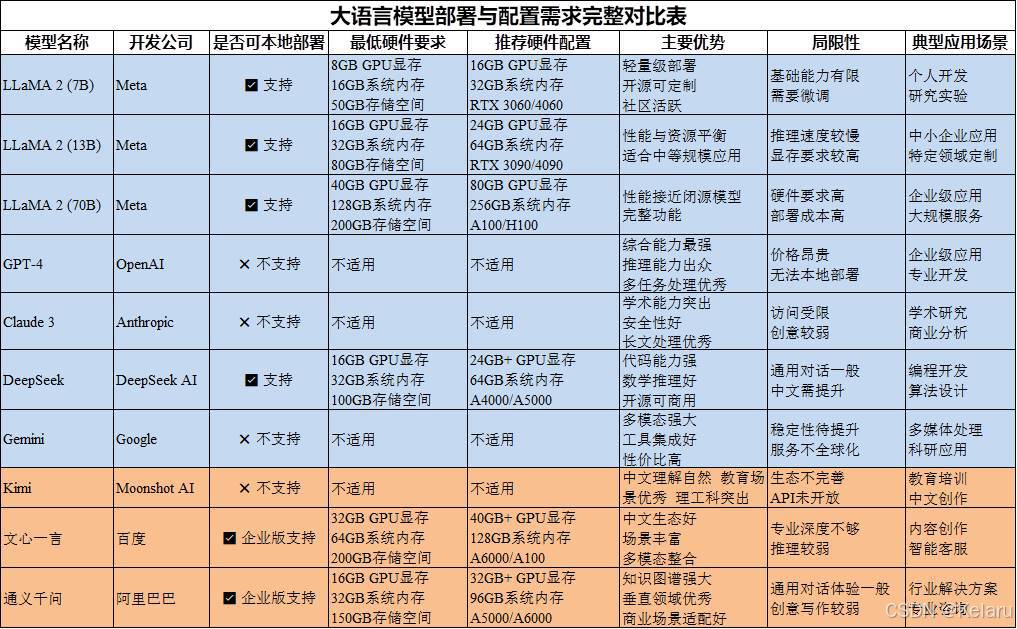
进行大模型部署之前请参考自己的电脑配置,以选择合适的大模型参数,下图是不同的大模型本地部署需要的硬件要求,请对照自己的电脑配置进行现在安装。
本次安装示例步骤:
Step 0:电脑配置与安装环境准备
硬件:Mac mini 24g / 512g
软件:macOS sequoia 15.3
环境:python 3.11
step 1: 下载 ollama
去ollama 官网下载:Ollama
下载安装,当桌面出现小羊驼标说明已经安装完毕

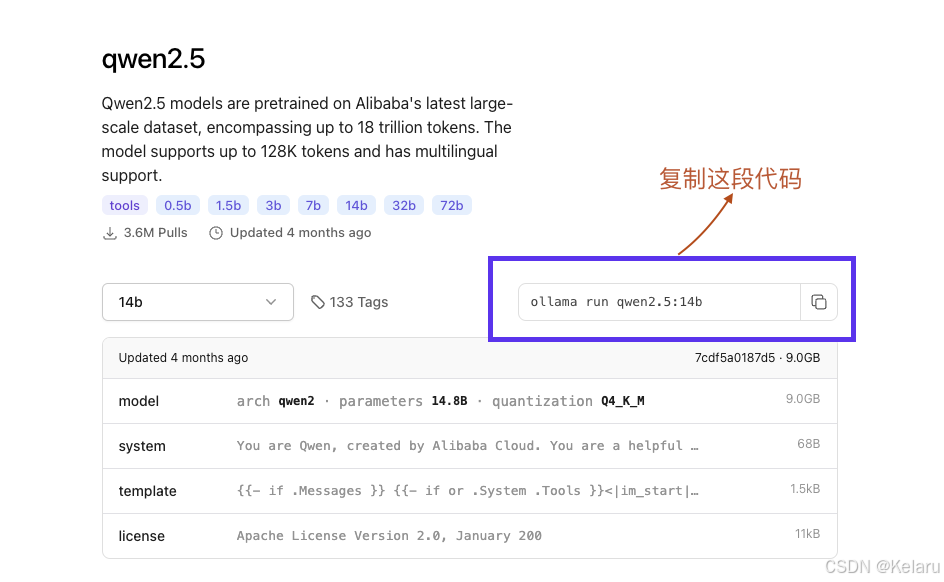
Step 2:下载大模型
进入ollama 官网,选择需要部署的大模型类型及size,点击下载即可
打开终端,运行以上复制的代码指令,等待下载完成(可能需要10分钟左右)
下载安装好后,即可本地与大模型进行交互了
为保证每次电脑打开ollama 无需加载,我们可以对其做一个设定
OLLAMA_KEEP_ALIVE=-1,让ollama 始终保持运行状态,避免一段时间过后ollama 退出且将大模型释放,下一次使用的时候再次加载,重复浪费时间
OLLAMA_HOST=0.0.0.0:11434 Ollama serve/ ollama 手机移动端可以通过局域网访问ollama
Step 3: 建立一个UI界面,让大模型使用起来更方便
1、环境准备
# 创建并进入项目目录
mkdir ollama-web-ui
cd ollama-web-ui
# 创建虚拟环境(推荐)
python -m venv venv
# 激活虚拟环境
# Windows:
venv\Scripts\activate
# Linux/Mac:
source venv/bin/activate
# 安装依赖包
pip install streamlit requests pandas
2、配置文件设置
# 创建 Streamlit 配置目录
# Linux/Mac:
mkdir -p ~/.streamlit
mkdir %UserProfile%\.streamlit
# Windows:
mkdir %UserProfile%\.streamlit
# 创建配置文件
# Linux/Mac:
cp config.toml ~/.streamlit/
# Windows:
copy config.toml %UserProfile%\.streamlit\
3、创建应用文件
# 创建应用文件
# Linux/Mac:
touch app.py
# Windows:
type nul > app.py
# 将前面提供的代码复制到 app.py 中
4、Ollama 设置
# 确认 Ollama 已安装并运行
ollama list
# 拉取所需模型
ollama pull qwen2.5-14b # 主模型
ollama pull llama2 # 可选
ollama pull mistral # 可选
# 确认模型已安装
ollama list
运行应用
# 启动应用
streamlit run app.py
5、创建的界面具备如下功能:
A. 基础功能:
- 访问 http://localhost:8501 打开界面
- 在左侧面板选择要使用的模型
- 调整模型参数(temperature、max_tokens等)
- 在底部输入框输入问题并发送
B. 文件处理:
- 点击"文件处理"展开面板
- 上传需要处理的文件(支持txt、json、csv、pdf、png、jpg)
- 上传后的文件会自动附加到下一个问题中
C. 对话管理:
- 导出对话:
- 展开"对话历史管理"面板
- 点击"导出当前对话"
- 对话将保存为CSV文件
- 导入对话:
- 展开"对话历史管理"面板
- 上传之前导出的CSV文件
- 点击"加载对话"
D. 高级设置:
- 展开"高级参数设置"面板可调整:
- Top P:控制采样范围
- Top K:控制候选词数量
- 重复惩罚:避免重复内容
- 常见问题排查
如果遇到问题,检查:
- Ollama 服务是否运行(默认端口11434)
- 选择的模型是否已安装
- 配置文件是否正确放置
- Python依赖是否完整安装
以上为全部的本地大模型部署的步骤展示,欢迎来交流学习~

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









