






每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

知名 AI IDE 产品 Cursor 日前宣布年经常性收入突破 3 亿美元,其代码库快速索引能力成为一大亮点。据介绍,Cursor 使用了默克尔树(Merkle Tree)结构来加快代码的索引速度。以下是其具体实现方式的详解。
默克尔树简述
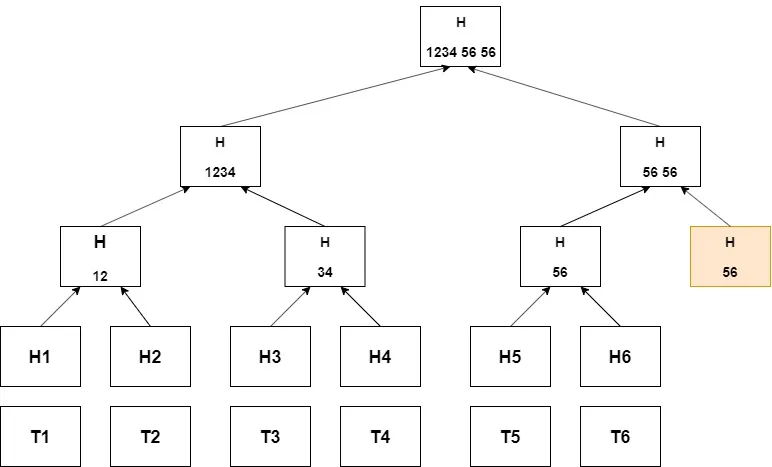
默克尔树是一种树形数据结构,所有叶子节点都用数据块的加密哈希值进行标记,而非叶子节点则是其子节点哈希值的组合哈希。这种结构可以高效检测任何层级的数据变更,只需比较哈希值即可。
其基本原理如下:
- 每段数据(如文件)都有唯一的哈希值;
- 相邻两个哈希值组合生成新的哈希值;
- 重复此过程,最终形成一个根哈希(root hash)作为整体数据的指纹。
如果数据中任何一部分发生更改,相关哈希值也会随之改变,最终导致根哈希的变动。这种机制为数据完整性验证和高效同步提供了强有力的支持。
Cursor 如何使用默克尔树进行代码索引
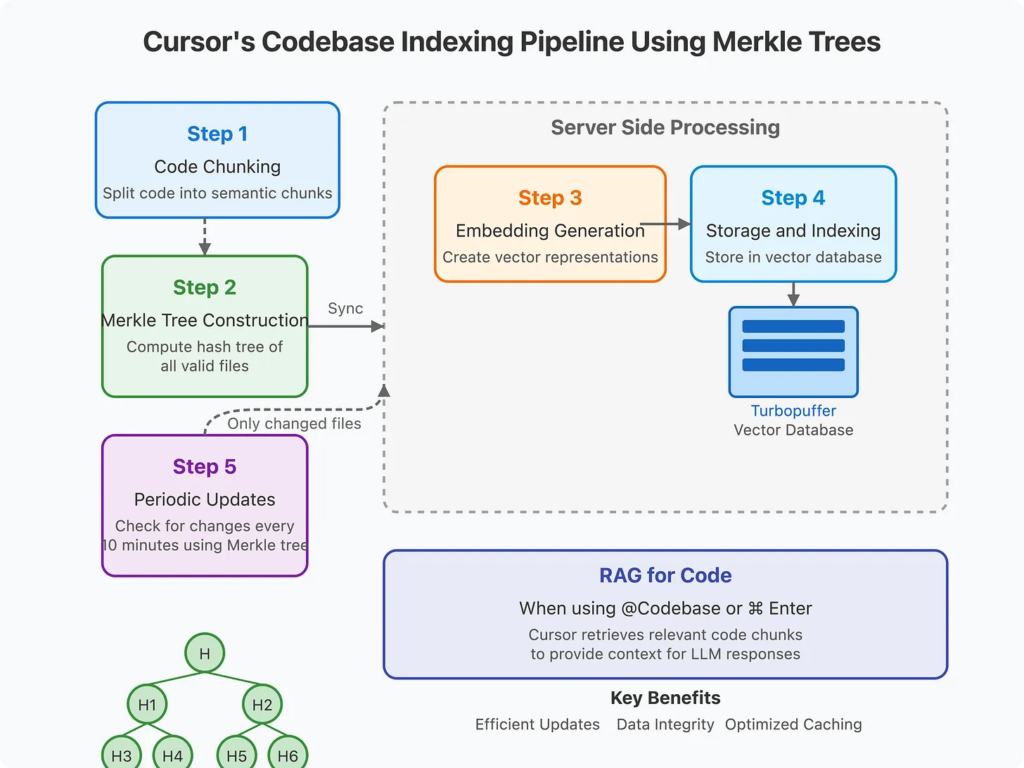
根据 Cursor 创始人及其安全文档的内容,代码索引过程如下:
第一步:代码分块与处理
Cursor 首先在本地对代码进行分块,将文件切分为语义上有意义的片段,以便后续处理。
第二步:构建默克尔树并同步
在开启代码库索引功能后,Cursor 会扫描编辑器中打开的文件夹,并计算所有有效文件的哈希,构建默克尔树。随后该树会被同步到 Cursor 的服务器。
第三步:生成嵌入向量
完成分块后,片段被发送到服务器,由 OpenAI 的嵌入 API 或其他定制模型生成向量表示,用以捕捉代码语义。
第四步:存储与索引
嵌入向量与元数据(如起止行号、文件路径)一起被存储于远程向量数据库 Turbopuffer 中。为保护隐私,每个向量仅附带经过混淆处理的相对文件路径。创始人表示,代码内容并不被数据库持久保存,只在请求生命周期内存在。
第五步:定时增量更新
系统每 10 分钟使用默克尔树检查哈希是否有变动,只上传已变更文件。这种机制大大减少了带宽使用,是默克尔树结构在索引系统中的核心价值之一。
代码分块策略
代码分块策略的优劣直接影响嵌入质量。常规的字符、词或行级切分往往无法识别语义边界,导致效果不佳。
更优的方式包括:
- 使用固定 token 数量进行分割,尽管可能打断函数或类;
- 利用递归式文本分割器,根据函数或类定义等高层结构进行切分;
- 基于抽象语法树(AST)进行分割,使用如 tree-sitter 等工具遍历 AST 树结构,根据 token 限制合并兄弟节点形成语义完整的片段。
嵌入在推理阶段的用途
生成嵌入后,系统如何实际使用这些信息?
语义搜索与上下文检索
用户在使用 Cursor 的智能功能时(如 @Codebase 或 ⌘ Enter 提问)会触发如下流程:
- 查询嵌入:系统对用户问题或当前代码上下文生成嵌入;
- 向量搜索:将查询嵌入发送至 Turbopuffer,执行相似向量检索;
- 本地文件访问:客户端收到与查询语义相近的代码片段位置(包括混淆文件路径与行号);
- 上下文组装:客户端从本地文件读取相关片段,连同用户问题发送至服务器,由 LLM 处理;
- 结果反馈:模型根据上下文提供精准回答或代码补全建议。
这种机制带来了多种能力:
- 上下文感知的代码生成;
- 基于代码库的问答功能;
- 项目特定风格的智能补全;
- 智能化的代码重构建议。
Cursor 采用默克尔树的原因
多个关键功能依赖于默克尔树:
- 高效的增量更新
能够快速识别自上次同步以来变更的文件,仅需上传差异部分,显著降低资源消耗。 - 数据完整性验证
分层哈希结构便于检测传输过程中的数据损坏或不一致问题。 - 优化缓存机制
嵌入结果以哈希为键缓存,相同代码库二次索引速度更快,利于协作团队共享。 - 保护隐私的索引方式
文件路径采用分段加密处理,避免暴露敏感信息,仅泄露部分目录结构。 - Git 历史集成
在 Git 项目中启用索引功能时,Cursor 同步保存提交哈希、父提交信息与混淆路径。团队成员共享 Git 数据结构时,混淆密钥通过近期提交内容的哈希导出。
嵌入模型与技术考量
嵌入模型的选择直接影响语义理解质量。尽管部分系统使用开源模型(如 all-MiniLM-L6-v2),Cursor 更可能采用 OpenAI 嵌入模型或为代码定制的模型,如 unixcoder-base(微软)或 voyage-code-2(Voyage AI)。
由于嵌入模型有 token 限制(如 OpenAI 的 text-embedding-3-small 限制为 8192 token),因此需要高效的代码分块策略确保保留语义信息的同时不超限。
同步过程中的握手机制
在同步时,Cursor 实现了“握手流程”。日志显示,系统在初始化索引时创建 “merkle client”,并向服务器发送本地计算出的根哈希,进行“启动握手”(startup handshake)。服务器据此判断需同步的文件范围,详见 GitHub 上的 Issue #2209 与 #981。
技术实现中的挑战
尽管默克尔树结构带来众多优势,其实现也并非没有难点。
- 高负载问题:Cursor 的索引功能在高负载时频繁失败,导致文件需多次上传才能完成索引,用户可能注意到向 “repo42.cursor.sh” 发出的网络请求异常频繁。
- 嵌入安全隐患:研究显示,在某些情况下嵌入向量可被逆向还原。尽管现有攻击多依赖嵌入模型的访问权限并通常作用于短文本,仍存在风险:若攻击者访问了 Cursor 的向量数据库,或有可能从嵌入中提取代码库的敏感信息。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









