







书接上回,小堡鸽一身劲装正欲踏出厅门,不想一阵旋风似的人影直直冲撞过来。
堡鸽哪里见过这番光景,强作镇静定眼一瞧:
这不是哈希表吗?
哈希表堪堪停住脚步,几欲扑倒在地上,扶膝大口喘着粗气:“姓堡的,你又要走?”
小堡鸽愣了两秒,像才反应过来似的直起身子,拍拍哈希表的肩膀:“我出去一会就回…”
不想哈希表忽然转过身来,撒泼打诨似的抡起拳头砸在小堡鸽胸口上,砰砰的响声听得一旁小汉直咧嘴。
“好你个没心肝的,随想录没刷完你也不急!!今天都什么日子了!!我看你就是被幻兽帕鲁那个荡妇迷了心神,才连算法题都不放在心上!!”
哈希表说到这句突然哽住,倒吸了一口凉气,眼圈也倏尔红了,指尖几乎戳在小堡鸽鼻子上。
“我明…我明白了!!我说怎么力扣小绿点没了你也不在意,一早就打定了主意要去找那个妖艳贱货来替了算法题的位子!!”
“哈…希表,你这是哪里的话?我堡鸽岂…”
见堡鸽吞吞吐吐一句完整的话凑不出,哈希表到底气不过,把键盘摔在堡鸽面前。
“你若是这周写不完哈希表和字符串,莫要再踏进此处一步!”
由于小堡鸽的怠惰,本周任务繁重,姑且复习一些以前写过的,巩固下基础。本文依旧是错题集+对部分题目的个人理解。主打一个记录美好生活。
一、哈希表
1.两个数组的交集
先来一题简单的试试水(喜)
结果看到原代码就绷不住了,请看VCR。(摊手)
int* intersection(int* nums1, int nums1Size, int* nums2, int nums2Size, int* returnSize) {
int hash[1001] = {0};
for(int i = 0;i <= nums1Size-1;i++){
if(hash[nums1[i]] == 0){
hash[nums1[i]]++;
}
}
for(int i = 0;i <= nums2Size-1;i++){
if(hash[nums2[i]] == 1){
hash[nums2[i]]++;
}
}
int* result=(int*)malloc(sizeof(int) * 1000);
int count = 0;
for(int i = 0;i <= 1000;i++){
if(hash[i] >= 2){
result[count++] = i;
}
}
*returnSize = count;
return result;
}
非常简单的思路,把两个数组都映射进哈希表里面,且在第一次映射时需要注意一个数字仅仅出现一次,而第二次映射时则是寻找重复的数字,而后在对应下标处执行加一操作。最后列出重叠的数字,放入result数组即可。
不过由于题目中特意提到不考虑输出结果顺序,那就有一些操作变得没有必要了,第二、三个for循环可以合并至一起,即发现重复元素便直接放入result数组。
修改后的代码如下:
for(i = 0; i < nums2Size; i ++) {
if(hash[nums2[i]] > 0) {
result[count++] = nums2[i];
count++;
hash[nums2[i]] = 0;
}
}
2.快乐数

这道题用双指针可以比较迅速的解决,让小汉想起来弗洛伊德判环,如若存在循环快慢双指针必然可以相遇,而如果没有环,则快指针可以达到1。
遵循如上规律可以写出:
int Caculate(int x){
int num = 0;
while(x != 0){
num += (x % 10) * (x % 10);
x /= 10;
}
return num;
}
bool isHappy(int n) {
int fast = n;
int slow = n;
while(fast != 1){
fast = Caculate(Caculate(fast));
slow = Caculate(slow);
if (fast == 1 || slow == 1) {
return true;
}
if(fast == slow){
return false;
}
}
return true;
}
而这道题被放在哈希表章节,自然也可以用哈希表解决:
设定一个表,每次计算后在表中寻找一下是否有相同的数即可。
int Caculate(int x){
int num = 0;
while(x != 0){
num += (x % 10) * (x % 10);
x /= 10;
}
return num;
}
bool isHappy(int n) {
unsigned char visited[163] = { 0 };
int sum = Caculate(Caculate(n));
int nextNum = sum;
while (nextNum != 1) {
sum = Caculate(nextNum);
if (visited[sum]) return false;
visited[sum] = 1;
nextNum = sum;
};
return true;
}
3.四数相加
我们需要得到一组(四个)数,相加等于0,遍历显然不行,时间复杂度过高(n^4)。我们需要用哈希表来降低时间复杂度。
可以把四数之和拆解成两数之和,暂且将四个数组命名为ABCD,只需将a + b存于一个数组中,再将c+d存在另一个数组中,同时比对c+d之中是否有数字等于0-a-b即可,如此一来,时间复杂度就压缩到了n2+n2。
但问题也随之到来,以往我们都是用数组充当哈希表,现在nums数组里面的数字实在太大了,数组映射不进去,即使真的开了一个极大的数组,也过于浪费空间了。
这次我们需要自建哈希表。
代码部分参考自:
typedef struct hashnode{
int key;
int value;
struct hashnode* next;
}HN;
int fourSumCount(int* nums1, int nums1Size, int* nums2, int nums2Size, int* nums3, int nums3Size, int* nums4, int nums4Size){
//先合并前两个
HN *sthead = (HN*)malloc(sizeof(HN));
sthead->key = 0;
sthead->value = 0;
sthead->next = NULL;
for(int i = 0;i < nums1Size;i++){
for(int j = 0;j < nums2Size;j++){
int sum = nums1[i] + nums2[j];
int flag = 0;
HN* head = sthead;
while(head->next != NULL){
head = head->next;
if(head->key == sum){
head->value += 1;
flag = 1;
break;
}
}
if(flag == 1) continue;
HN* new = (HN*)malloc(sizeof(HN));
new->key = sum;
new->value = 1;
new->next = NULL;
head->next = new;
}
}
int ans = 0;
for(int i = 0;i < nums3Size;i++){
for(int j = 0;j < nums4Size;j++){
int sum = nums3[i] + nums4[j];
HN* head1 = sthead;
while(head1->next){
head1 = head1->next;
if(head1->key == 0-sum){
ans += head1->value;
break;
}
}
}
}
return ans;
}
来跟我念,哈(链)希(表)表,建立哈希表的方法与建立链表的方法一致。链表的数据域仅仅需要两个值,一个值用于存放sum,另一个用于存放value,即sum值出现的次数。
后日堡吐槽:那为什么不用二维数组。
而后照着上述思路写下去即可。为了方便插入新的结点,这里采用了先建立一个空节点,再往后插入新节点的形式。
二、字符串
代码随想录的字符串章节里面,我将反转字符串(1、2),替换数字,翻转字符串里的单词分为一组,这一组主要集中于字符串数组的基本操作,考察对字符串特性的熟悉程度。
而实现strStr,重复的子字符串则分为第二组,这一组主要是考察算法,介绍了字符串匹配的经典算法——KMP。
1.反转字符串中的单词

先放上我一开始写的方法:
char* reverseWords(char* s) {
char hash[10001][100] = { 0 };
int i = 0;int j = 0;
int ans = 0;
while (s[ans] != '\0') {
while (s[ans] == ' ') {
ans++;
}
j = 0;
while (s[ans] != ' ' && s[ans] != '\0') {
hash[i][j] = s[ans];
ans++;
j++;
}
while (s[ans] == ' ') {
ans++;
}
hash[i][j] = '\0';
if (s[ans] == '\0') {
break;
}
i++;
}
char* new = (char*)malloc(sizeof(char) * (strlen(s) + 1));
char* p = new;
while (i != -1) {
int count = 0;
while (hash[i][count] != '\0') {
*new = hash[i][count];
count++;
new++;
}
*new = ' ';
new++;
i--;
}
new--;
*new = '\0';
return p;
}
大概方法就是先把每一个单词找出来,存进哈希表,而后再将其反方向输出,构成一个新的串。
这种方法现在看来有些过于繁琐,这里展示一种新的解法。
先大转,再小转(你是…线性代数!)
具体思路是先删除字符串中多余的空格,再将整个字符串反转一次,而后把每个单词翻转过来。
//先写一个翻转的函数
char *reverse(char *s, int start, int end){
for(int i = start, j = end; i < j; i++, j--){
char *tmp = s[i];
s[i] = s[j];
s[j] = tmp;
}
return s;
}
//再写一个去除空格的函数
char *removeSpace(char *s){
int slow = 0, fast = 0; //定义快慢指针
//去除字符串前面的空格
while(strlen(s) > 0 && fast < strlen(s) && s[fast] == ' ') fast++;
//去除字符串中间冗余空格
for(; fast < strlen(s); fast++){
if(fast - 1 > 0 && s[fast - 1] == s[fast] && s[fast] == ' ')
continue;
else
s[slow++] = s[fast];
}
//去除字符串末尾空格
if(slow - 1 > 0 && s[slow - 1] == ' ')
s[slow - 1] = '\0';
else
s[slow] = '\0';
return s;
}
char * reverseWords(char * s){
s = removeSpace(s);//将多余空格去除
s = reverse(s, 0, strlen(s) - 1);
int i = 0, j = 0;
while(j < strlen(s)){
while(s[j] != ' ' && j < strlen(s)) j++;//确定单词长度(j最终会停留在空格上)
reverse(s,i,j-1);//翻转单个单词
j += 1;
i = j;
}
return s;
}
2.找出字符串中第一个匹配项的下标
借本题可以引出KMP算法。由于笔记的特质,本文不会详细地解释KMP算法,可能在之后会写一篇博客详细介绍,这里仅仅放上KMP的用法,next数组的求解方法等与解题直接相关的部分。
//个人习惯,next数组使用右移后的版本
int* GetNext(char* s) {
int* next = (int*)malloc(sizeof(int) * strlen(s));
int j = -1;
int i = 0;
next[i] = j;
while (i < strlen(s) - 1) {
if (j == -1 || s[i] == s[j]) {
i++;
j++;
next[i] = j;
}
else {
j = next[j];
}
}
return next;
}
求解next数组的三个步骤分别为:
1.初始化next数组
2.处理前后缀相同和不相同的情况
3.更新next数组
定义i ,j 分别指向后缀末尾位置,前缀末尾,若相等则加加,不等则向前回退。
//再放上正常的求解next数组的方法
int* GetNext(char* s) {
int* next = (int*)malloc(sizeof(int) * strlen(s));
int j = 0;
int i = 1;
next[0] = 0;
for(i = 1;i < strlen(s);i++){
while(j && s[j] != s[i]) j = next[j - 1];
if(s[j] == s[i]) j++;
next[i] = j;
}
return next;
}
int strStr(char* haystack, char* needle) {
int *next = GetNext(needle);
int j = 0;
int i = 0;
while(i <= strlen(haystack) && j <= strlen(needle)){
if(haystack[i] == needle[j]){
i++;
j++;
}else{
j = next[j];
if(j == -1){
i++;
j++;
}
}
if(j == strlen(needle)){//当j等于字符串长度时,表示找到了,返回值i - j表示字符串首字母的下标位置
return i - j;
}
}
return -1;
}
3.重复的子字符串
本题同样可以使用类似KMP的思路解决。
求出next数组,观察最后一个字母的next值是否为0,若不为0,且数值对于总长度取模等于0,则可以判断是由一个子串重复多次构成。
解释一下缘由:
next数组表示到该下标为止的最长公共前后缀长度,设最后一位next值为x,总长度为n,则n-x可以表示最后剩下的一块儿位置,由于前后缀的特性可以得知他们是构成整个字符串的子串。
什么!小堡鸽含糊不清的话你没听懂?
请看vcr:
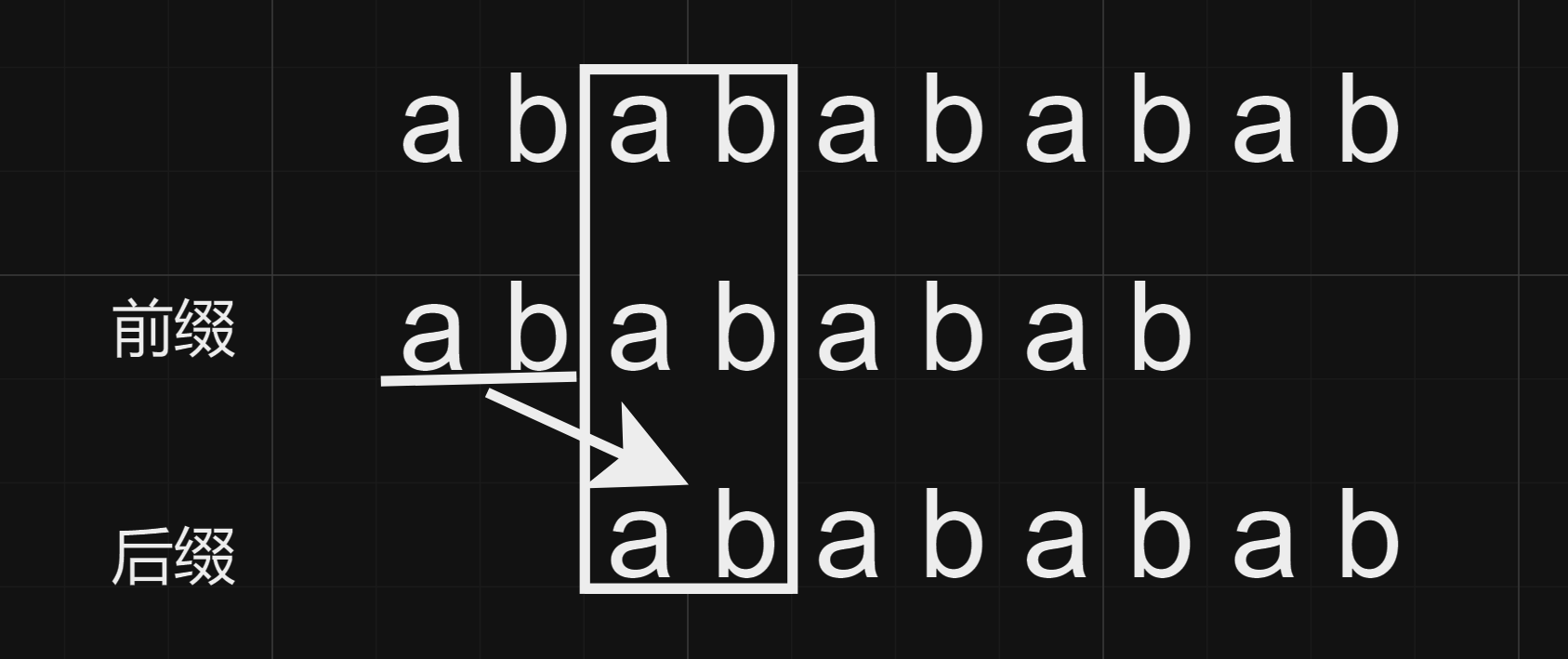
由于前后缀的特性,被白色方框框出来的区域必然相等,而由于公共的特性,白色箭头指向的两个ab也必然相等,由此向后一直推导,即可推导出ab构成了一整个字符串。
// 求next数组 最大前后缀
int* GetNext(char* s) {
int* next = (int*)malloc(sizeof(int) * strlen(s));
int j = 0;
int i = 1;
next[0] = 0;
for(i = 1;i < strlen(s);i++){
while(j && s[j] != s[i]) j = next[j - 1];
if(s[j] == s[i]) j++;
next[i] = j;
}
return next;
}
bool repeatedSubstringPattern(char * s){
size_t n = strlen(s);
int* next = GetNext(s);
int x = next[n-1];
return x != 0 && n % (n - x) == 0;
}
三、结语
这周的哈希还尚可理解,字符串这块属实是搞的有一点点头昏脑涨,不过很惊奇地解决了之前一直没理解的烤馍片算法(之前学的是有多浅啊喂)。传统艺能放上:
君子之学也,入乎耳,著乎心,布乎四体,形乎动静。端而言,蝡而动,一可以为法则。小人之学也,入乎耳,出乎口;口耳之间,则四寸耳,曷足以美七尺之躯哉!古之学者为己,今之学者为人。君子之学也,以美其身;小人之学也,以为禽犊。故不问而告谓之傲,问一而告二谓之囋。傲、非也,囋、非也;君子如向矣。
希望大家都可以好好学习,天天向上。















 5873
5873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









