







字符串
344. 反转字符串
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。
不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。
示例 1:
输入:s = ["h","e","l","l","o"]
输出:["o","l","l","e","h"]示例 2:
输入:s = ["H","a","n","n","a","h"]
输出:["h","a","n","n","a","H"]提示:
1 <= s.length <= 105s[i]都是 ASCII 码表中的可打印字符
算法思路:
采用双指针法,再使用一个临时变量实现字符串的首尾交换。
实现代码:
class Solution:
def reverseString(self, s: List[str]) -> None:
"""
Do not return anything, modify s in-place instead.
"""
left, right = 0, len(s)-1
temp = 0
while(left <= right):
temp = s[left]
s[left] = s[right]
s[right] = temp
left += 1
right -= 1541. 反转字符串 II
给定一个字符串 s 和一个整数 k,从字符串开头算起,每计数至 2k 个字符,就反转这 2k 字符中的前 k 个字符。
- 如果剩余字符少于
k个,则将剩余字符全部反转。 - 如果剩余字符小于
2k但大于或等于k个,则反转前k个字符,其余字符保持原样。
示例 1:
输入:s = "abcdefg", k = 2
输出:"bacdfeg"示例 2:
输入:s = "abcd", k = 2
输出:"bacd"提示:
1 <= s.length <= 104s仅由小写英文组成1 <= k <= 104
算法思路:
基本思想就是实现一个能够让字符串部分翻转的函数:
def reverse(x:str, start:int, end:int):#指定顺序翻转字符
x = list(x)#先转为list类型
left, right = start, end - 1
temp = 0
while (left <= right):
temp = x[left]
x[left] = x[right]
x[right] = temp
left += 1
right -= 1
x = ''.join(x)#再将结果转为字符串类型
return x重点就是如何实现从字符串开头算起,每计数至 2k 个字符,就反转这 2k 字符中的前 k 个字符,再前面翻转函数的基础上,实现如下代码:
for i in range(0, len(s), 2*k):
res = reverse(s, i, min(len(s), i+k))
s = res如果剩余字符少于 k 个,则将剩余字符全部反转 :min(len(s), i+k)
实现代码:
class Solution:
def reverseStr(self, s: str, k: int) -> str:
#翻转部分字符串
def reverse(x:str, start:int, end:int):
x = list(x)
left, right = start, end - 1
temp = 0
while (left <= right):
temp = x[left]
x[left] = x[right]
x[right] = temp
left += 1
right -= 1
x = ''.join(x)
return x
res = ''
#从字符串开头算起,每计数至 2k 个字符,就反转这 2k 字符中的前 k 个字符
for i in range(0, len(s), 2*k):
res = reverse(s, i, min(len(s), i+k))
s = res
return res
剑指 Offer 05. 替换空格
请实现一个函数,把字符串 s 中的每个空格替换成"%20"。
示例 1:
输入:s = "We are happy."
输出:"We%20are%20happy."实现代码:
class Solution:
def replaceSpace(self, s: str) -> str:
while (' ' in s):
s = s.replace(' ', '%20')
return s151. 反转字符串中的单词
给你一个字符串 s ,请你反转字符串中 单词 的顺序。
单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。
返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。
注意:输入字符串 s中可能会存在前导空格、尾随空格或者单词间的多个空格。返回的结果字符串中,单词间应当仅用单个空格分隔,且不包含任何额外的空格。

提示:
1 <= s.length <= 104s包含英文大小写字母、数字和空格' 's中 至少存在一个 单词
算法思想:
解法一:
可以用Python中的split()函数将单词分解成list类型,然后再将list类型翻转,最后转化为字符串类型
实现代码:
class Solution:
def reverseWords(self, s: str) -> str:
s = s.split()
s = s[::-1]s
s = ' '.join(s)
return s解法二:
会借助到python 切片和列表元素拼接成字符串的方法
思路:定义i, j两个指针从字符串s的0下标开始向后遍历:
- 若i遇到空格则i,j均加1;
- 若j遇到空格此时匹配单词结尾处,通过s[i:j]获取单词;
- 若j遍历到右边界,则直接获取剩余全部字符。
实现代码:
class Solution:
def reverseWords(self, s: str) -> str:
res = []
start = end = 0
while(end < len(s)):
if(s[start] == ' '):#找到每个单词的首字符
start += 1
end += 1
elif(s[end] == ' '):#将每个单词加入res
res.append(s[start:end])
end += 1
start = end
elif(end == len(s) - 1):#如果是最后一个单词,可以直接加入res
res.append(s[start:])
end += 1
else:
end += 1
res = ' '.join(res[::-1])#将每个单词转换为字符串并用空格隔开
return res剑指 Offer 58 - II. 左旋转字符串
字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串"abcdefg"和数字2,该函数将返回左旋转两位得到的结果"cdefgab"。
示例 1:
输入: s = "abcdefg", k = 2
输出: "cdefgab"示例 2:
输入: s = "lrloseumgh", k = 6
输出: "umghlrlose"限制:
1 <= k < s.length <= 10000
算法思想:
采用字符串的切片的方式,将字符切片s[n:]和s[:n]交换一下位置即可。
实现代码:
class Solution:
def reverseLeftWords(self, s: str, n: int) -> str:
res = s[n:]
res += s[:n]
return res28. 找出字符串中第一个匹配项的下标 - KMP算法
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。
示例 1:
输入:haystack = "sadbutsad", needle = "sad"
输出:0
解释:"sad" 在下标 0 和 6 处匹配。
第一个匹配项的下标是 0 ,所以返回 0 。示例 2:
输入:haystack = "leetcode", needle = "leeto"
输出:-1
解释:"leeto" 没有在 "leetcode" 中出现,所以返回 -1 。提示:
1 <= haystack.length, needle.length <= 104haystack和needle仅由小写英文字符组成
算法思想:
解法一:
暴力破解法:依次遍历字符串s,s[i]表示s的一个字符,采用字符串切片s[i:i+len(needle)]与需要查找的字符串needle进行比较,要是相等就范围i,否则返回-1。
实现代码:
class Solution:
def strStr(self, haystack: str, needle: str) -> int:
for i in range(len(haystack)):
if(needle == haystack[i:i+len(needle)]):
return i
return -1解法二:KMP算法(还未写)
实现代码:
KMP算法类似题
类似题1 796. 旋转字符串
给定两个字符串, s 和 goal。如果在若干次旋转操作之后,s 能变成 goal ,那么返回 true 。
s 的 旋转操作 就是将 s 最左边的字符移动到最右边。
- 例如, 若
s = 'abcde',在旋转一次之后结果就是'bcdea'。
示例 1:
输入: s = "abcde", goal = "cdeab"
输出: true示例 2:
输入: s = "abcde", goal = "abced"
输出: false提示:
1 <= s.length, goal.length <= 100s和goal由小写英文字母组成
算法思想:
(1)技巧法
只需比较一下两个字符串的长度,然后判断A + A中是否存在B就ok,因为A + A中已经包含了所有可能的移动情况。
下面是图形解释:
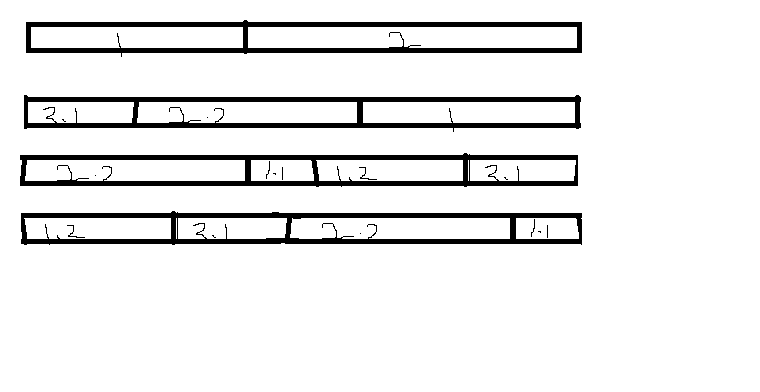
我们把s字符串分为1,2进行旋转,然后继续把2分为2.1,2.2进行旋转,然后把1变为1.1,1.2进行旋转。 我们发现收尾的字符串分段是1.1和1.2。也就是不管s旋转多少次,他的收尾相连总会还原成原字符串的某个更大分段。 因此该算法受这个规律启迪,我们把goal的首尾不断相连(即把goal的首字符不断放到goal末尾),如果过程中发现goal == s那么说明goal是s的旋转字符串。 如果进行了n次收尾相连后,任然无法还原到s,那么说明goal不是s的旋转字符串,因为再次旋转将重复上个旋转周期一样的事情。
实现代码:
class Solution:
def rotateString(self, s: str, goal: str) -> bool:
#只需比较一下两个字符串的长度,然后判断A + A中是否存在B就ok,因为A + A中已经包含了所有可能的移动情况
if(len(s) != len(goal)):
return False
else:
s += s
if(goal in s):
return True
else:
return False(2)KMP算法
实现代码:
类似题目2 214. 最短回文串
给定一个字符串 s,你可以通过在字符串前面添加字符将其转换为回文串。找到并返回可以用这种方式转换的最短回文串。
示例 1:
输入:s = "aacecaaa"
输出:"aaacecaaa"示例 2:
输入:s = "abcd"
输出:"dcbabcd"提示:
0 <= s.length <= 5 * 104s仅由小写英文字母组成
算法思想:
实现代码:
类似题目3 1044. 最长重复子串
给你一个字符串 s ,考虑其所有 重复子串 :即 s 的(连续)子串,在 s 中出现 2 次或更多次。这些出现之间可能存在重叠。
返回 任意一个 可能具有最长长度的重复子串。如果 s 不含重复子串,那么答案为 "" 。
示例 1:
输入:s = "banana"
输出:"ana"示例 2:
输入:s = "abcd"
输出:""提示:
2 <= s.length <= 3 * 104s由小写英文字母组成
算法思想:
实现代码:
类似题目4 1316. 不同的循环子字符串
给你一个字符串 text ,请你返回满足下述条件的 不同 非空子字符串的数目:
- 可以写成某个字符串与其自身相连接的形式(即,可以写为
a + a,其中a是某个字符串)。
例如,abcabc 就是 abc 和它自身连接形成的。
示例 1:
输入:text = "abcabcabc"
输出:3
解释:3 个子字符串分别为 "abcabc","bcabca" 和 "cabcab" 。示例 2:
输入:text = "leetcodeleetcode"
输出:2
解释:2 个子字符串为 "ee" 和 "leetcodeleetcode" 。提示:
1 <= text.length <= 2000text只包含小写英文字母。
算法思想:
实现代码:
类似题目5:1392. 最长快乐前缀
「快乐前缀」 是在原字符串中既是 非空 前缀也是后缀(不包括原字符串自身)的字符串。
给你一个字符串 s,请你返回它的 最长快乐前缀。如果不存在满足题意的前缀,则返回一个空字符串 "" 。
示例 1:
输入:s = "level"
输出:"l"
解释:不包括 s 自己,一共有 4 个前缀("l", "le", "lev", "leve")和 4 个后缀("l", "el", "vel", "evel")。最长的既是前缀也是后缀的字符串是 "l" 。示例 2:
输入:s = "ababab"
输出:"abab"
解释:"abab" 是最长的既是前缀也是后缀的字符串。题目允许前后缀在原字符串中重叠。提示:
1 <= s.length <= 105s只含有小写英文字母
算法思路:
(1)暴力解法:
直接切片,finalRes做循环内局部变量,遇到更大快乐前缀就覆盖.
实现代码:
class Solution:
def longestPrefix(self, s: str) -> str:
res = ''
for i in range(len(s)):
if(s[:i] == s[len(s)-i:]):#遇到更大快乐前缀就覆盖
res = s[:i]
return res(2)KMP算法
实现代码:
类似题目6 2223. 构造字符串的总得分和
你需要从空字符串开始 构造 一个长度为 n 的字符串 s ,构造的过程为每次给当前字符串 前面 添加 一个 字符。构造过程中得到的所有字符串编号为 1 到 n ,其中长度为 i 的字符串编号为 si 。
- 比方说,
s = "abaca",s1 == "a",s2 == "ca",s3 == "aca"依次类推。
si 的 得分 为 si 和 sn 的 最长公共前缀 的长度(注意 s == sn )。
给你最终的字符串 s ,请你返回每一个 si 的 得分之和 。
示例 1:
输入:s = "babab"
输出:9
解释:
s1 == "b" ,最长公共前缀是 "b" ,得分为 1 。
s2 == "ab" ,没有公共前缀,得分为 0 。
s3 == "bab" ,最长公共前缀为 "bab" ,得分为 3 。
s4 == "abab" ,没有公共前缀,得分为 0 。
s5 == "babab" ,最长公共前缀为 "babab" ,得分为 5 。
得分和为 1 + 0 + 3 + 0 + 5 = 9 ,所以我们返回 9 。示例 2 :
输入:s = "azbazbzaz"
输出:14
解释:
s2 == "az" ,最长公共前缀为 "az" ,得分为 2 。
s6 == "azbzaz" ,最长公共前缀为 "azb" ,得分为 3 。
s9 == "azbazbzaz" ,最长公共前缀为 "azbazbzaz" ,得分为 9 。
其他 si 得分均为 0 。
得分和为 2 + 3 + 9 = 14 ,所以我们返回 14 。提示:
1 <= s.length <= 105s只包含小写英文字母。
算法思想:
实现代码:
459. 重复的子字符串
给定一个非空的字符串 s ,检查是否可以通过由它的一个子串重复多次构成。
示例 1:
输入: s = "abab"
输出: true
解释: 可由子串 "ab" 重复两次构成。示例 2:
输入: s = "aba"
输出: false示例 3:
输入: s = "abcabcabcabc"
输出: true
解释: 可由子串 "abc" 重复四次构成。 (或子串 "abcabc" 重复两次构成。)提示:
1 <= s.length <= 104s由小写英文字母组成
算法思想:
将头部的字符串取出来,然后重复相加这个头部字符串,直至达到和s等长,再比较是否和s相等。
实现代码:
class Solution:
def repeatedSubstringPattern(self, s: str) -> bool:
temp = ''
for i in range(len(s)//2):
temp += s[i]
res = ''
count = len(s)//len(temp)#统计要重复子串的次数
for j in range(count):
res += temp#将子串重复达到s的长度
if(res == s):
return True
return False49. 字母异位词分组
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的字母得到的一个新单词,所有源单词中的字母通常恰好只用一次。
示例 1:
输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
输出: [["bat"],["nat","tan"],["ate","eat","tea"]]示例 2:
输入: strs = [""]
输出: [[""]]示例 3:
输入: strs = ["a"]
输出: [["a"]]提示:
1 <= strs.length <= 1040 <= strs[i].length <= 100strs[i]仅包含小写字母
算法思想:
(1)思路一:暴力破解法,但是超时
字母异位词指的是字母相同且字母的个数也相同但是字母的位置不同的字符串称为字母异位词。
使用两层for循环,将i和j指向的两个字符串排序再进行比较,固定i不动,移动j, 如果两者相等,则为异位词,将其添加入临时列表temp,最后再判断temp是否为结果列表res里某个元素的子集,若果为子集,则不能添加入res,反之则加入res。
实现代码:
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
if(len(strs)==0):
return strs
res = []
for i in range(len(strs)):
temp = []
temp.append(strs[i])
for j in range(i + 1 , len(strs)):
if(sorted(strs[i]) == sorted(strs[j])):
temp.append(strs[j])
if(len(temp) != 0):
tag = False#用来标记temp是否是res里某个元素的子集
for t in range(len(res)):
if(set(temp) <= set(res[t])):#判断temp是否是res里某个元素的子集
tag = True
break
if(tag == False):#子集是不需要重复添加进结果list里的
res.append(temp)
return res(2)思路二:
主要思路还是运用python里的字典序唯一的键key可以对应多个值,例如一个字符串的key值可以对应一个value值为list对象,eg:dic = {“abc”:[1,2,3]}。所以我们可以将strs的每个单词先排序,因为排序后异位词相同且唯一的,所以可以设它为字典序的key(将排序后的不同的单词设为key值),而那些异位词可以设为字典序的value值,若果遍历到的单词且排序后和key值相同,则把它添加到key值所对应的value值里,不然就新建一个list对象来存此单词,最后返回输出字典序的value值即可。
实现代码:
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
dic = {}#字典序里一个字符串(这是key值)可以对应一个list对象(这是value值),这list对象里可以包含一系列的字符串
for s in strs:
temp = ''.join(sorted(s))
if temp in dic.keys():#因为排序后异位词相同且唯一的,所以可以设它为字典序的key,而那些异位词可以设为字典序的value值
dic[temp].append(s)
else:
dic[temp] = [s]#temp为新的key值, dic[temp]表示新的key所对应的list对象
return list(dic.values())
















 411
411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











