






【Python】浅析Python内存管理与GC机制
从C语言引入:内存管理的挑战
C语言是一个强大的编程语言,它允许开发者直接控制内存。这种控制是通过以下方式实现的:
- 内存分配:使用
malloc、calloc或realloc等函数分配内存。 - 内存释放:使用
free函数释放内存。
例如,在创建链表时:
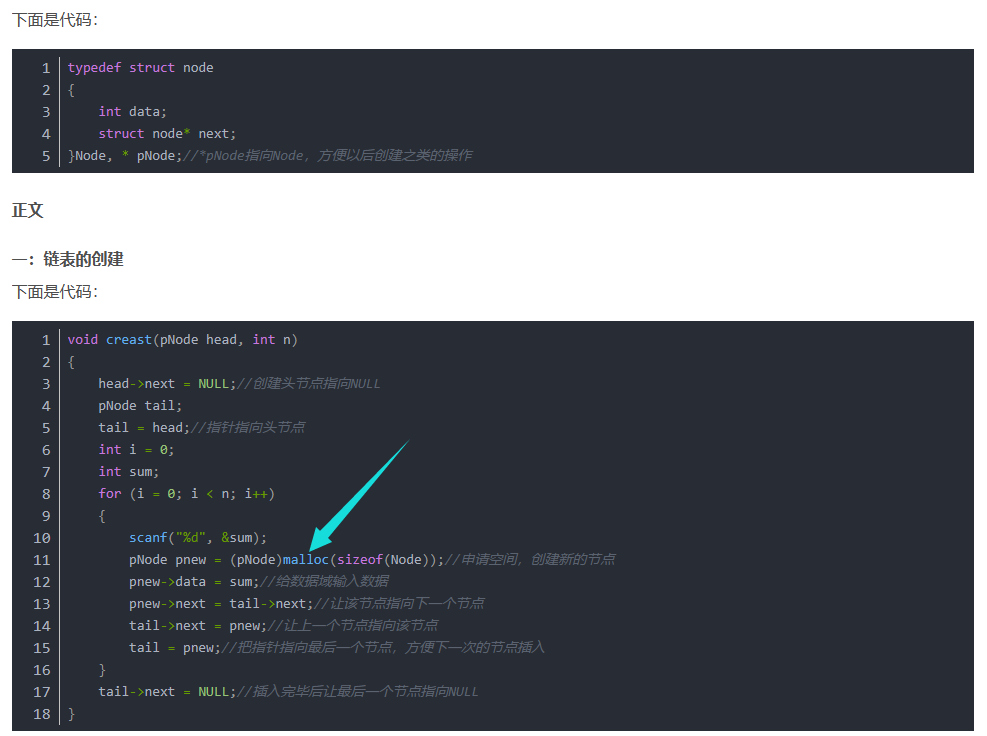
我们使用malloc,为结点结构体的指针分配内存。
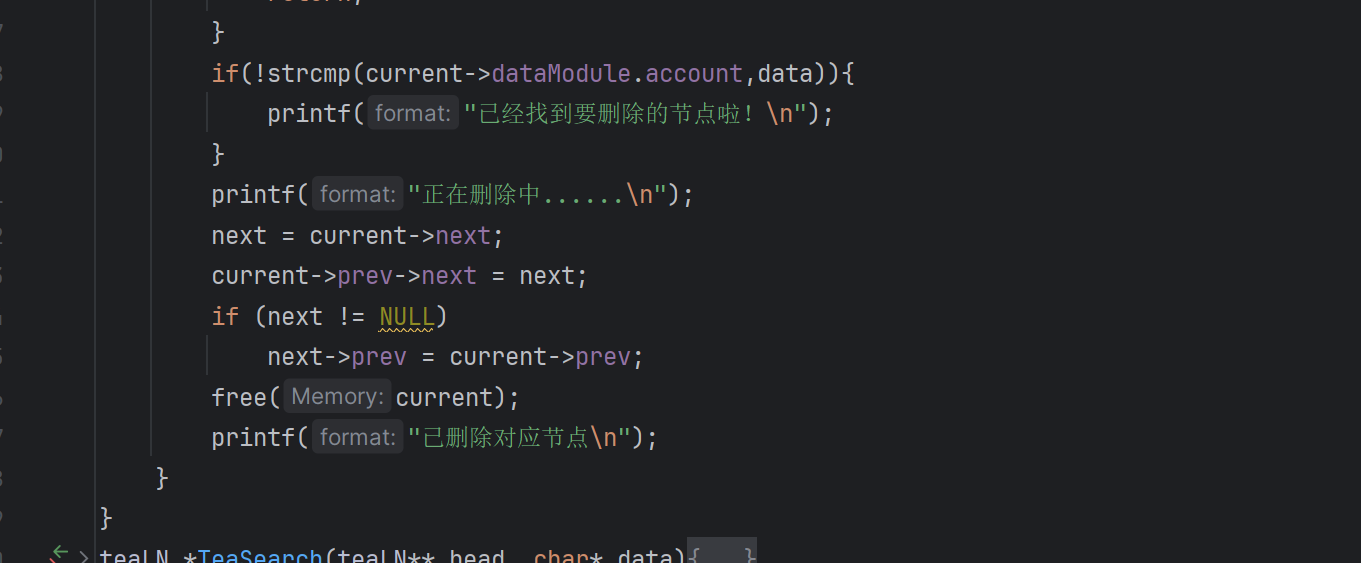
而在删除节点时,我们采用free函数来进行内存的释放。
尽管这种直接控制带来了灵活性,但也带来了显著的缺点和风险:
- 内存泄漏:如果开发者忘记释放已经分配的内存,会导致内存泄漏,长时间运行的程序可能会耗尽可用内存。
- 悬挂指针:如果释放了内存但仍然继续使用这些内存的指针,会导致悬挂指针,从而导致程序崩溃或不可预测的行为。
- 碎片化:频繁的内存分配和释放可能导致内存碎片化,降低程序性能。
第一点与第三点实际上有些类似:程序员手动创建与释放内存,很容易忘记释放某些不常用内存,且部分内容使用时间较长,不方便规划内存释放时机。
第二点:若释放完内存,指针会变成空指针,若此时再对其进行使用,可能会导致空指针异常。
Python:GC(垃圾回收器)的便利
Python 作为一种高级编程语言,提供了自动内存管理和垃圾回收机制,极大地简化了内存管理。开发者不需要手动管理内存的分配和释放,而是依赖于Python内置的垃圾回收器(Garbage Collector,GC)来完成这些任务。
Python的内存管理主要由以下几个部分组成:
- 引用计数器(Reference Counting)
- 垃圾回收器(Garbage Collector)
- 对象池(Object Pooling)
1. 引用计数器
1·1 环状双向链表 refchain
在Python程序中创建的任何对象,都会放在refchain链表中。
name = "Python课程展示"
time = 2.5
studyProgress = ["还没开始预习","马上开始预习"]
当创建一个对象时,内存会存储一些关于这个对象的数据
【上一个对象,下一个对象,类型,引用个数】
name = "Python课程展示"
new = name
在C语言源码中,如何体现每个对象中都有的相同的值:PyObject结构体(4个值)
有多个元素组成的对象:PyObject结构体(4个值) + ob_size。

1.2 类型封装结构体
以Float类型为例
data = 3.14
内部会创建:
_ob_next = //refchain中的上一个对象
_ob_prev = //refchain中的下一个对象
ob_refcnt = 1
ob_type = float
ob_fval = 3.14

1.3 引用计数器
v1 = 3.14
v2 = 999
v3 = (1,2,3)
当Python程序运行时,会根据数据类型的不同找到其对应的结构体,根据结构体中的字段来进行创建相关的数据,然后将对象添加到refchain双向链表之中。
在C语言源码中有两个关键的结构体:PyObject、PyVarObject
引用计数器是Python内存管理的核心机制之一。每个对象都有一个引用计数器,用于记录引用该对象的数量。当一个对象被创建时,其引用计数为1,当有新的引用指向该对象时,计数加1,当引用被删除时,计数减1。如果引用计数变为0,该对象将被回收。
- 引用
a = 9999
b = a
- 删除引用
a = 9999
b = a
del b
# b变量删除
# b对应对象的引用计数器 -1
del a
# a变量删除
# a对应对象的引用计数器 -1
此时,引用计数器归零,意味着没有人再使用这个对象,这个对象就被判定为垃圾,触发垃圾回收机制。
将对象从refchain链表移除
将对象销毁,内存归还。
(缓冲机制)
1.4 循环引用问题(交叉感染)
例如,创建两个列表。
v1 = [11,22,33] # refchain中创建一 个列表对象, 由于v1=对象, 所以列表引对象用计数器为1.
v2 = [44,55,66] # refchain中再创建一个列表对象,因v2=对象,所以列表对象引用计数器为1.
v1.append(v2) # 把v2追加到v1中,则v2对应的[44, 55 , 66]对象的引用计数器加1,最终为2.
v2.append(v1) # 把v1追加到v1中,则v1对应的[11,22,33]对象的引用计数器加1,最终为2.
del v1 # 引用计数器 -1
del v2 # 引用计数器 -1
2. 标记清除
目的:为了解决引用计数器循环引用的不足。
实现:在Python的底层,再维护一个链表。链表中专门放可能存在循环引用的对象。(list/tuple/dict/set)
在Python内部的某种情况下触发,会去扫描可能存在循环引用的链表中的每个元素,检查是否有循环引用,如果有则让双方的引用计数器 -1 ;如果是0则垃圾回收。
标记清除机制的优缺点
优点
- 处理循环引用:标记清除机制可以有效处理对象之间的循环引用问题。
- 准确性:能够准确回收所有不可达对象,避免内存泄漏。
缺点
- 性能开销:标记和清除过程需要遍历所有对象,可能会带来性能开销,尤其是在对象数量庞大的情况下。
- 暂停时间:标记和清除过程会暂停程序的执行,可能导致程序的响应时间变长。
问题:
- 什么时候扫描?
- 可能存在循环引用的链表扫描代价较大,每次扫描耗时比较久。
3. 分代回收
Python 的垃圾回收器 将可能存在循环引用的对象 维护成三个链表:
- 年轻代(Generation 0):新创建的对象。
- 中生代(Generation 1):从年轻代晋升的对象。
- 老年代(Generation 2):从中生代晋升的对象。
分代的基本原则
- 大多数对象很快会变成垃圾:新创建的对象往往在很短的时间内就不再使用,因此年轻代的回收频率最高。
- 对象存活时间越长,被回收的可能性越小:因此,中生代和老年代的回收频率较低。
分代垃圾回收的工作原理
1. 年轻代(Generation 0)
- 创建对象:所有新创建的对象都首先分配到年轻代。
- 垃圾回收:年轻代的垃圾回收频率最高,因为新创建的对象大多数很快就会变成垃圾。每次年轻代的垃圾回收称为一次小型垃圾回收(Minor GC)。
- 晋升机制:存活时间较长的对象(未在年轻代被回收的对象)会晋升到中生代。
2. 中生代(Generation 1)
- 存活对象:在年轻代存活并晋升到中生代的对象。
- 垃圾回收:中生代的垃圾回收频率较低。每次中生代的垃圾回收不仅回收中生代,还会同时回收年轻代。
- 晋升机制:在中生代存活较长时间的对象会晋升到老年代。
3. 老年代(Generation 2)
- 长期存活对象:在中生代存活并晋升到老年代的对象。
- 垃圾回收:老年代的垃圾回收频率最低,因为这些对象存活时间最长,被回收的可能性较小。每次老年代的垃圾回收会回收整个堆,包括年轻代和中生代。
分代垃圾回收的触发条件
- 阈值触发:每个代都有一个垃圾回收阈值,当该代分配的对象数量超过阈值时,触发一次垃圾回收。
- 手动触发:可以通过调用
gc.collect()手动触发垃圾回收。
分代垃圾回收的实现细节
对象管理
Python 的垃圾回收器使用链表和指针来管理各代中的对象。每个代都有一个链表,链表中的节点代表堆中的对象。垃圾回收器通过遍历这些链表来进行垃圾回收。
晋升机制
- 晋升条件:当对象在某一代经过一定次数的垃圾回收后仍然存活,则晋升到下一代。这个次数由一个计数器控制。
- 晋升过程:垃圾回收器会将满足晋升条件的对象从当前代的链表移到下一代的链表。
分代回收算法
- 小型垃圾回收(Minor GC):只回收年轻代,通过标记-清除算法,标记可达对象并回收不可达对象。
- 中型垃圾回收(Mid GC):回收中生代和年轻代。
- 完全垃圾回收(Full GC):回收整个堆,包括所有代。
分代回收机制的优缺点
优点
- 高效:通过频繁回收年轻代,减少长期存活对象的回收次数,优化了垃圾回收性能。
- 减少停顿:分代回收机制通过分阶段回收,避免了单次回收时间过长的问题,减少了程序停顿时间。
缺点
- 复杂性:实现和调优分代垃圾回收机制需要更多的复杂性。
- 内存开销:需要维护多个链表和晋升逻辑,增加了一定的内存开销。
4. 缓存机制
4.1 池
Python 对小整数(通常在 -5 到 256 范围内)进行缓存,以提高整数对象的重用效率。小整数对象在 Python 解释器启动时创建,并在整个程序运行期间保存在内存中。当需要这些范围内的小整数时,直接从缓存中获取对象,而不是重新创建。这种缓存机制减少了频繁创建和销毁小整数对象的开销。
# 启动解释器时,python内部会帮我们创建:-5 / -4 ... 257
v1 = 7 # 内部不会开辟内存,直接去池中获取
v2 = 9 # 内存不会开辟内存,直接去池中获取
v3 = 9
在 Python 源代码中,小整数缓存机制实现如下:
/* 初始化小整数数组 */
for (i = 0; i < 257; i++) {
small_ints[i] = PyLong_FromLong((long)i - 5);
}
/* 获取小整数对象 */
PyObject* get_small_int(int value) {
if (value >= -5 && value <= 256) {
return small_ints[value + 5];
} else {
return PyLong_FromLong((long)value);
}
}
通过这种方式,Python 确保在需要小整数时,直接从缓存数组 small_ints 中获取对象,避免了重复创建。
4.2 字符串驻留机制
Python 对某些字符串进行驻留(interning),即在内存中保存并重用相同的字符串对象。这种机制适用于短字符串和常用标识符,例如变量名、函数名等。驻留字符串的优点在于节省内存和提高字符串比较操作的效率。
字符串驻留的实现
在 Python 中,可以手动将字符串驻留,通过调用 sys.intern() 函数:
import sys
a = sys.intern("hello")
b = sys.intern("hello")
# a 和 b 是同一个对象
print(a is b) # 输出: True
对于自动驻留,Python 对某些字符串常量自动应用驻留机制,例如:
a = "hello"
b = "hello"
# a 和 b 是同一个对象
print(a is b) # 输出: True
结语
依笔者之见,学习任何一门语言,仅仅了解其浅层的语法,理解的深度和对这门语言的熟悉程度会大打折扣,若是开发中需求一些较为底层的内容,便会捉襟见肘。故而在课程之余,不妨简单了解一下Python的GC机制,既是对当前学习内容的总结,也是对底层机制的进一步了解与深入。
参考资料与文献材料:
python/cpython: The Python programming language (github.com)
python垃圾回收 (GC) 机制_python gc-CSDN博客
【python】python的垃圾回收机制(详细讲解)-CSDN博客
特别鸣谢:
xiaoduyyy-CSDN博客 提供的C语言链表源码















 404
404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









