









Python中的垃圾回收是以引用计数为主,标记-清除和分代收集为辅。引用计数最大缺陷就是循环引用的问题,所以Python采用了辅助方法。本篇文章并不详细探讨Python的垃圾回收机制的内部实现,而是以gc模块为切入点学习Python的垃圾回收机制,如果想深入可以读读<<Python源码剖析>>。
看如下代码:
import gc
import sys
gc.set_debug(gc.DEBUG_STATS|gc.DEBUG_LEAK)
a=[]
b=[]
a.append(b)
print 'a refcount:',sys.getrefcount(a) # 2
print 'b refcount:',sys.getrefcount(b) # 3
del a
del b
print gc.collect() # 0输出结果:
a refcount: 2
b refcount: 3
gc: collecting generation 2...
gc: objects in each generation: 0 0 5131
gc: done, 0.0020s elapsed.
0
gc: collecting generation 2...
gc: objects in each generation: 0 0 5125
gc: done, 0.0010s elapsed.可以发现垃圾回收不起作用,所以垃圾收集只对循环引用起作用。
你可能好奇,为什么a的引用数是2呢?这时候你需要去看看sys.getrefcount(object)的函数说明了?
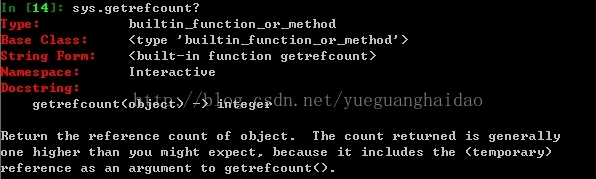
哦,该函数Docstring中说返回值通常比我们期望的要多1,因为传给该函数的参数临时变量又增加了一次引用。原来是这样,但让人很奇怪的是,为啥不调整一下呢???
gc.collect()返回此次垃圾回收的unreachable(不可达)对象个数。那什么是unreachable对象呢?请看下面一段代码:
a=[]
b=[]
a.append(b)
b.append(a)
del a
del b
print gc.collect()
输出结果:
gc: collecting generation 2...
gc: objects in each generation: 4 0 5127
gc: collectable <list 02648918>
gc: collectable <list 026488A0>
gc: done, 2 unreachable, 0 uncollectable, 0.0030s elapsed.
2上面收集的两个都是unreachable对象,那unreachable对象时什么呢?在说明unreachable对象就需要了解Python的标记-清除垃圾回收机制了,简单来说,过程如下:
** 寻找root object集合,root object多指全局引用和函数栈上的引用,如上面代码所示,a就是root object
** 从root object出发,通过其每一个引用到达的所有对象都标记为reachable(垃圾检测)
** 将所有非reachable的对象删除(垃圾回收)
这里还需要提到垃圾回收中的->>可收集对象链表,Python将所有可能产生循环引用的对象用链表连接起来,所谓的可产生循环引用的对象也就是list,dict,class等的容器类,int,string不是,每次实例化该种对象时都将加入这个链表,我们将该链表称为可收集对象链表(ps该链表是双向的)。
如,a=[],b=[],c={},将会产生:head <----> a <----> b <----> c 双向链表。
我们可以假想上述代码的垃圾回收过程:当调用gc.collect()时,将从root object开始垃圾回收,由于del a ,del b后,a,b都将成为unreachable对象,且循环引用将被拆除,此时a,b引用数都是0,a,b将被回收,所以collect将返回2。
看下面一段代码,将加深对上述的理解:
a=[]
b=[]
a.append(b)
b.append(a)
del b
print gc.collect()gc: collecting generation 2...
gc: objects in each generation: 354 4771 0
gc: done, 0.0010s elapsed.
0
gc: collecting generation 2...
gc: objects in each generation: 0 0 5119
gc: done, 0.0020s elapsed.
Python有了垃圾回收机制是否意味着不会造成内存泄漏呢,非也,请看如下代码:
class A:
def __del__(self):
pass
class B:
def __del__(self):
pass
a=A()
b=B()
print hex(id(a))
print hex(id(a.__dict__))
a.b=b
b.a=a
del a
del b
print gc.collect()
print gc.garbage
0x25cff30
0x25d0b70
gc: collecting generation 2...
gc: objects in each generation: 364 4771 0
gc: uncollectable <A instance at 025CFF30>
gc: uncollectable <B instance at 025CFF58>
gc: uncollectable <dict 025D0B70>
gc: uncollectable <dict 025D0810>
gc: done, 4 unreachable, 4 uncollectable, 0.0020s elapsed.
4
[<__main__.A instance at 0x025CFF30>, <__main__.B instance at 0x025CFF58>, {'b': <__main__.B instance at 0x025CFF58>}, {'a': <__main__.A instance at 0x025CFF30>}]
gc: collecting generation 2...
gc: objects in each generation: 2 0 5127
gc: done, 0.0010s elapsed.
为什么会这样呢?因为del b时,会调用b的__del__方法,该方法中很可能使用了b.a,但如果在之前的del a时将a给回收掉,此时将造成异常。所以Python没办法,造成了uncollectable,也就产生了内存泄漏。所以__del__方法要慎用,如果用的话一定要保证没有循环引用。
上面我们也打印出了a的地址,print hex(id(a)),也验证了回收的的确是a。
上面出现了gc.garbage,gc.garbage返回是unreachable对象,且不能被回收的的对象。仔细看看输出结果,为什么貌似有重复???这个困扰了我很久,直到打开gc模块的文档才懂了。由于我们之前gc.set_debug(gc.DEBUG_STATS|gc.DEBUG_LEAK),而gc.DEBUG_LEAK=gc.set_debug(gc.DEBUG_STATS|gc.DEBUG_COLLECTABLE | gc.DEBUG_UNCOLLECTABLE | gc.DEBUG_INSTANCES | gc.DEBUG_OBJECTS|gc.DEBUG_SAVEALL),文档中指出如果设置了gc.DEBUG_SAVEALL,那么所有的unreachable对象都将加入gc.garbage返回的列表,而不止不能被回收的对象。
我们看看Python的分代收集机制。
Python中总共有三个“代”,所谓的三"代”就是三个链表,也就是我们上面所提到的可收集对象链表。当各个代中的对象数量达到一定数量时将触发Python的垃圾回收,各个代的数量如下。

分代收集的思想就是活的越久的对象,就越不是垃圾,回收的频率就应该越低。所以当Python发现进过几次垃圾回收该对象都是reachable,就将该对象移到二代中,以此类推。那么Python中又是如何检查各个代是否达到阀值的呢?Python中每次会从三代开始检查,如果三代中的对象大于阀值将同时回收3,2,1代的对象。如果二代的满足,将回收2,1代中的对象,设计的是如此的美。

















 649
649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









