







 本文概述了机器学习的基本概念,包括数据集、样本、特征向量、学习过程(训练和测试)、泛化能力、归纳学习的分类(广义和狭义)、假设空间以及归纳偏好的确立。文章还介绍了有监督学习(分类和回归)和无监督学习(聚类)的任务,并强调了机器学习中的基本假设——独立同分布。
本文概述了机器学习的基本概念,包括数据集、样本、特征向量、学习过程(训练和测试)、泛化能力、归纳学习的分类(广义和狭义)、假设空间以及归纳偏好的确立。文章还介绍了有监督学习(分类和回归)和无监督学习(聚类)的任务,并强调了机器学习中的基本假设——独立同分布。
文章目录
1 基本概念
1.1 数据集
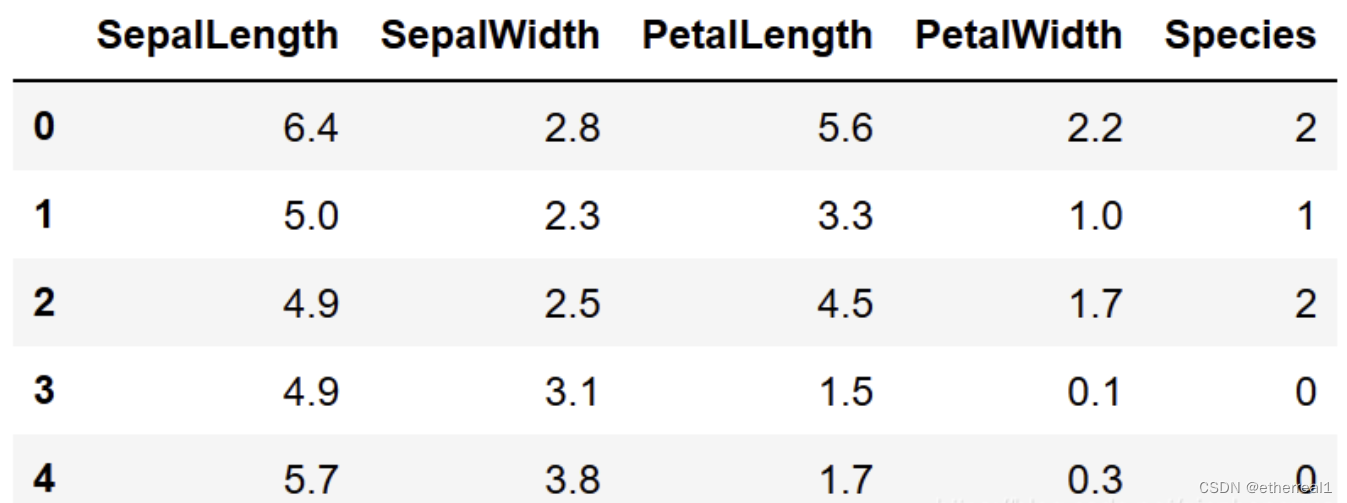
如图所示,为鸢尾花数据集的一部分,整个这样的表格就叫做数据集
1.2 样本
如上图,数据集中的每一行就是一个样本,表示一个鸢尾花实体。如第0行,表示0号鸢尾花实体
1.3 属性/特征
如上图,数据集中的每一列就是一个属性/特征,表示鸢尾花在某一方面的属性,其取值为属性值。如0号鸢尾花实体的SepalLength属性值为6.4
1.4 属性空间/样本空间/输入空间
属性张成的空间,可以将上述五个特征:“SepalLength”, “SepalWidth”, “PetalLength”, “PetalWidth”, "Species"作为五个坐标轴,则它们张成一个用于描述鸢尾花的五维空间,每个鸢尾花都能在这个空间中找到自己的坐标位置,如:0号鸢尾花的坐标位置为(6.4, 2.8, 5.6, 2.2, 2)
1.5 特征向量
属性空间的每一个点都对应一个坐标向量,这个坐标向量就被称为特征向量,如:0号鸢尾花实体对应的特征向量就是(6.4, 2.8, 5.6, 2.2, 2)
1.6 维数
有多少个属性,维数就是多少。如:上述鸢尾花数据集一共有5个属性(“SepalWidth”, “SepalWidth”, “PetalLength”, “PetalWidth”, “Species”)
1.7 学习/训练
从数据中学得模型的过程,数据称为训练数据/训练集,其中每个样本称为一个训练样本。学习得到的模型对应了关于数据的某种潜在的规律,这个得到的模型也称为假设,“某种潜在的规律”称为真相,模型也称为学习器
1.8 标记
对于上述鸢尾花数据集,我们发现"Species"属性只有三种不同的取值,若我们需要判断某个鸢尾花实体属于哪一类,则应该将"Species"属性作为标记,这样,鸢尾花数据集就拥有了标记信息,但这时候,鸢尾花数据集的特征就只剩下"SepalWidth", “SepalWidth”, “PetalLength”, "PetalWidth"这四个了,拥有了标记信息的样本被称为样例,所有的标记的集合称为标记空间/输出空间
1.9 测试
学的模型后,将其用于测试的过程。用于测试的样本称为测试样本
1.10 泛化能力
机器学习目标:使模型很好的适用于“新样本”。这种能力称为泛化能力
1.11 归纳学习
归纳:从特殊到一般的“泛化”的过程;演绎:从一般到特殊的“特化”过程
“从样例中学习”也称为归纳学习
1.11.1 归纳学习分类
1.11.1.1 广义的归纳学习
相当于从样例中学习
1.11.1.2 狭义的归纳学习
要求从训练数据中学得“概念”,因此也称概念学习/概念形成,其中最基本的是布尔概念学习
1.12 假设空间
将学习过程看作在所有假设中进行搜索的过程,目标是找到与训练集匹配的假设。
假设空间大小的计算:每个属性的取值种类数相乘后+1(“+1”操作是考虑到也许根本就不存在“正例”,无论什么假设都不成立)
版本空间:多个与训练集匹配的假设的集合
1.13 归纳偏好
机器学习算法在学习过程中对某种类型假设的偏好
1.13.1 引导算法确立正确偏好
奥卡姆剃刀原则:若有多个假设匹配训练集,选择最简单的那个
这是一种方法!但不是唯一的方法!
一个结论:对于一个学习算法A,若它在某些问题上比算法B好,则必然存在另一些问题,B比A好(任何算法均成立)–NFL(没有免费午餐定理)
NFL定理告诉我们:不能脱离问题空谈算法的好坏,需要针对特定的问题讨论

2 机器学习任务分类
2.1 有监督学习–预测
2.1.1 分类
预测值离散
2.1.1.1 二分类
标记中只有两个类别,一般称为正类和负类
2.1.1.2 多分类
标记中有多个类别,如上述鸢尾花数据集,其"Species"属性就具有3种不同的取值–0/1/2
2.2.2 回归
预测值连续
2.2 无监督学习–聚类
将训练集中的数据分成若干组,每一组称为簇
3 机器学习的一个基本假设
假设样本空间中全体样本服从一个未知分布D,我们获得的每个样本都是在这个分布上独立采样获得,即所有样本“独立同分布”















 4071
4071











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









