






如图,想要获取三日排行榜的股票数据
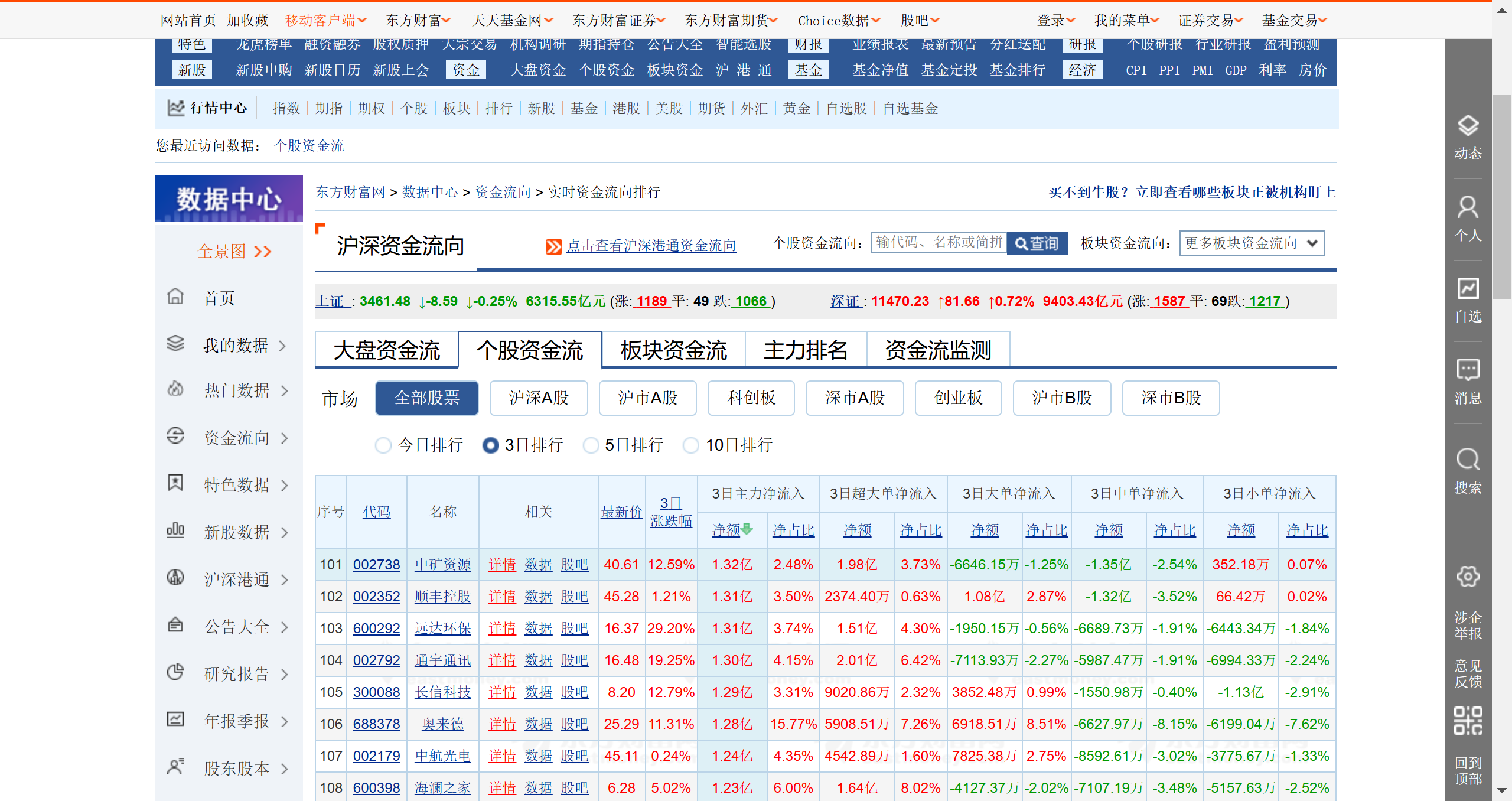
任意浏览网站,发现是不用登录的
打开开发者工具,数据很好找
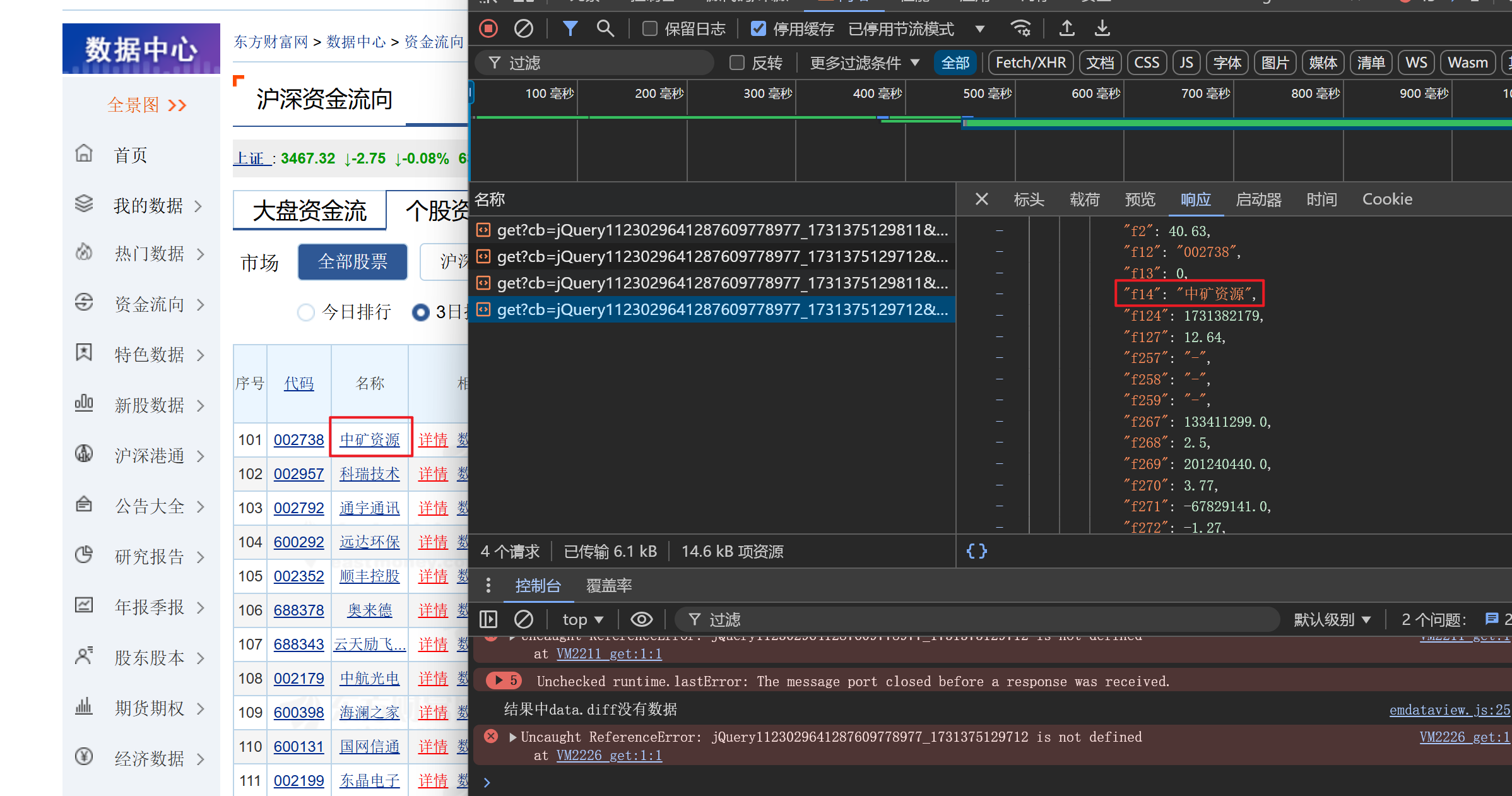
先直接请求一次
import requests
import re
import json
def get_one_data(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36'
}
response = requests.get(url, headers=headers)
print("Status Code:", response.status_code) # 检查状态码
if response.status_code == 200:
data_str = response.text
print("Raw Data:", data_str[:500]) # 只打印前500个字符进行检查
# 移除可能的回调函数,提取 JSON 数据部分
json_data_match = re.search(r'\((.*)\)', data_str)
if json_data_match:
json_data = json_data_match.group(1) # 提取 JSON 数据部分
try:
data_dict = json.loads(json_data) # 解析 JSON
print("Parsed JSON:", data_dict) # 打印解析后的 JSON 数据,便于调试
# 继续提取需要的字段
pattern = re.compile(
r'"f12":"(.*?)".*?"f14":"(.*?)".*?"f2":(.*?),.*?"f172":(.*?),.*?"f267":(.*?),'
r'.*?"f268":(.*?),.*?"f269":(.*?),.*?"f270":(.*?),.*?"f271":(.*?),'
r'.*?"f272":(.*?),.*?"f273":(.*?),.*?"f274":(.*?),.*?"f275":(.*?),.*?"f276":(.*?)'
)
# 用于存储提取的数据
data = []
for match in pattern.finditer(json_data):
data.append({
"f12": match.group(1),
"f14": match.group(2),
"f2": float(match.group(3)),
"f172": float(match.group(4)),
"f267": float(match.group(5)),
"f268": float(match.group(6)),
"f269": float(match.group(7)),
"f270": float(match.group(8)),
"f271": float(match.group(9)),
"f272": float(match.group(10)),
"f273": float(match.group(11)),
"f274": float(match.group(12)),
"f275": float(match.group(13)),
"f276": float(match.group(14)),
})
return data
except json.JSONDecodeError:
print("Error decoding JSON.")
return None
return None
if __name__ == '__main__':
url = 'https://push2.eastmoney.com/api/qt/clist/get?cb=jQuery1123029641287609778977_1731375129708&fid=f267&po=1&pz=50&pn=1&np=1&fltt=2&invt=2&ut=b2884a393a59ad64002292a3e90d46a5&fs=m%3A0%2Bt%3A6%2Bf%3A!2%2Cm%3A0%2Bt%3A13%2Bf%3A!2%2Cm%3A0%2Bt%3A80%2Bf%3A!2%2Cm%3A1%2Bt%3A2%2Bf%3A!2%2Cm%3A1%2Bt%3A23%2Bf%3A!2%2Cm%3A0%2Bt%3A7%2Bf%3A!2%2Cm%3A1%2Bt%3A3%2Bf%3A!2&fields=f12%2Cf14%2Cf2%2Cf127%2Cf267%2Cf268%2Cf269%2Cf270%2Cf271%2Cf272%2Cf273%2Cf274%2Cf275%2Cf276%2Cf257%2Cf258%2Cf124%2Cf1%2Cf13'
result = get_one_data(url)
if result:
for entry in result:
print(entry)
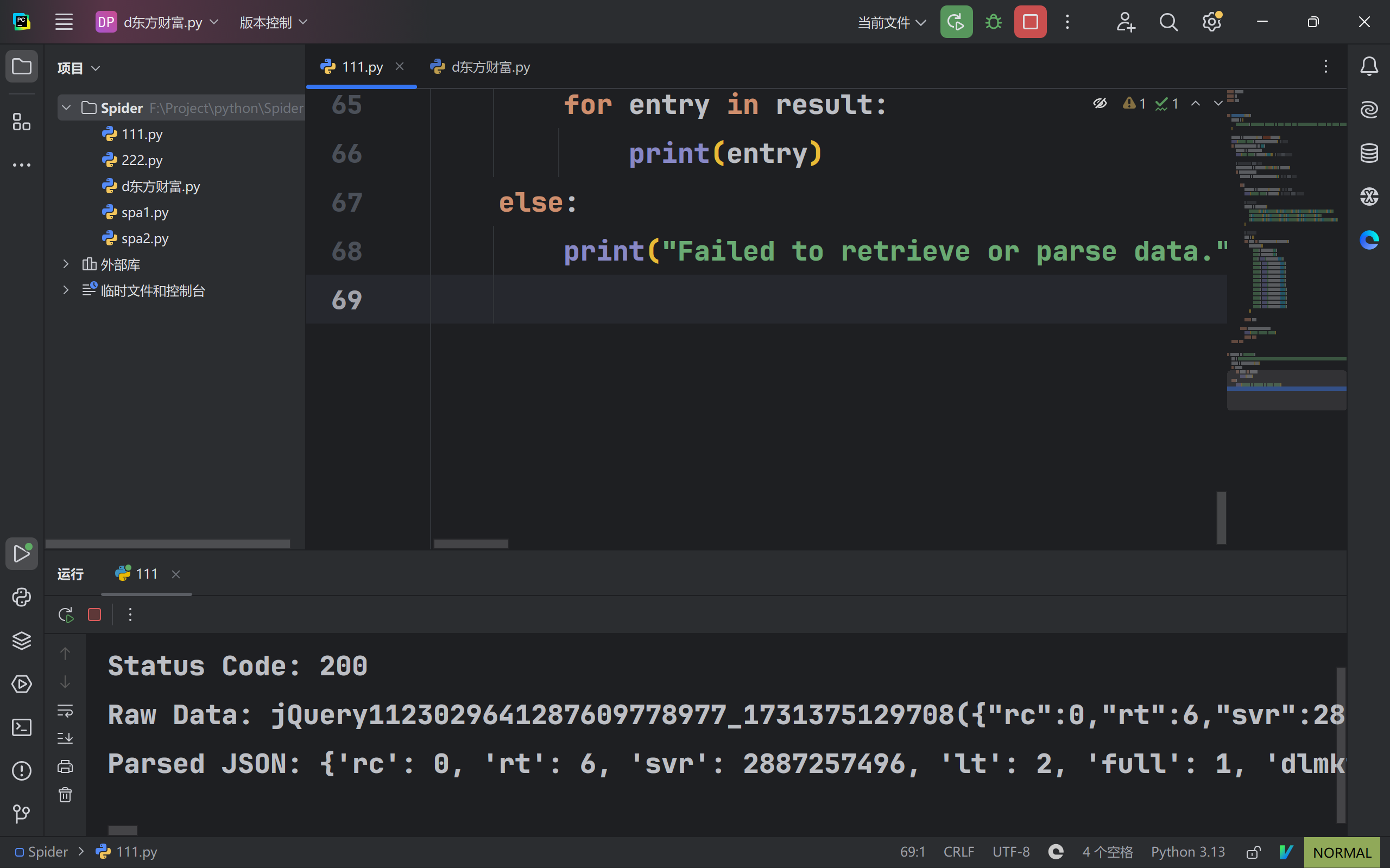
else:
print("Failed to retrieve or parse data.")
在通过比对数值确定对应信息
f12(代码)、f14(名称)、f2(最新价)、f172(三日涨跌幅)、f267(按日主力净流入净额)、f268(三日主力净流入净占比)、f269(三日超大单净流入净额)、f270(三日超大单净流入净占比)、f271(三日大单净流入净额)、f272(三日大单净流入净占比)、f273(三日中单净流入净额)、f274(三日中单净流入净占比)、f275(三日小单净流入净额)、f276(三日小单净流入净占比)
正则解析返回的源码数据,并创建一个字典储存
json_data_match = re.search(r'\((.*)\)', response.text)
( 匹配左括号 (,由于括号是特殊字符,因此需要使用反斜杠 \ 转义
(.) 匹配任意字符(.)并捕获到一个组中,这里是为了提取括号中的内容
) 匹配右括号 )
if response.status_code == 200:
json_data_match = re.search(r'\((.*)\)', response.text)
if json_data_match:
json_data = json_data_match.group(1)
try:
data_dict = json.loads(json_data)
if 'data' in data_dict and 'diff' in data_dict['data']:
extracted_data = data_dict['data']['diff']
data_list = []
for entry in extracted_data:
# 处理各个字段可能为 '-' 的情况
latest_price = entry.get("f2", "-")
latest_price = 0.0 if latest_price == "-" else float(latest_price)
data_list.append({
"代码": entry.get("f12"),
"名称": entry.get("f14"),
"最新价": latest_price,
"三日涨跌幅": float(entry.get("f172", 0)),
"按日主力净流入净额": float(entry.get("f267", 0)),
"三日主力净流入净占比": float(entry.get("f268", 0)),
"三日超大单净流入净额": float(entry.get("f269", 0)),
"三日超大单净流入净占比": float(entry.get("f270", 0)),
"三日大单净流入净额": float(entry.get("f271", 0)),
"三日大单净流入净占比": float(entry.get("f272", 0)),
"三日中单净流入净额": float(entry.get("f273", 0)),
"三日中单净流入净占比": float(entry.get("f274", 0)),
"三日小单净流入净额": float(entry.get("f275", 0)),
"三日小单净流入净占比": float(entry.get("f276", 0))
})
return data_list
except json.JSONDecodeError:
print("Error decoding JSON.")
return None
测试单页爬取效果
import requests
import re
import json
def get_one_data(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
json_data_match = re.search(r'\((.*)\)', response.text)
if json_data_match:
json_data = json_data_match.group(1)
try:
data_dict = json.loads(json_data)
if 'data' in data_dict and 'diff' in data_dict['data']:
extracted_data = data_dict['data']['diff']
data_list = []
for entry in extracted_data:
data_list.append({
"代码": entry.get("f12"),
"名称": entry.get("f14"),
"最新价": float(entry.get("f2", 0)),
"三日涨跌幅": float(entry.get("f172", 0)),
"按日主力净流入净额": float(entry.get("f267", 0)),
"三日主力净流入净占比": float(entry.get("f268", 0)),
"三日超大单净流入净额": float(entry.get("f269", 0)),
"三日超大单净流入净占比": float(entry.get("f270", 0)),
"三日大单净流入净额": float(entry.get("f271", 0)),
"三日大单净流入净占比": float(entry.get("f272", 0)),
"三日中单净流入净额": float(entry.get("f273", 0)),
"三日中单净流入净占比": float(entry.get("f274", 0)),
"三日小单净流入净额": float(entry.get("f275", 0)),
"三日小单净流入净占比": float(entry.get("f276", 0))
})
return data_list
except json.JSONDecodeError:
print("Error decoding JSON.")
return None
if __name__ == '__main__':
url = 'https://push2.eastmoney.com/api/qt/clist/get?cb=jQuery1123029641287609778977_1731375129708&fid=f267&po=1&pz=50&pn=1&np=1&fltt=2&invt=2&ut=b2884a393a59ad64002292a3e90d46a5&fs=m%3A0%2Bt%3A6%2Bf%3A!2%2Cm%3A0%2Bt%3A13%2Bf%3A!2%2Cm%3A0%2Bt%3A80%2Bf%3A!2%2Cm%3A1%2Bt%3A2%2Bf%3A!2%2Cm%3A1%2Bt%3A23%2Bf%3A!2%2Cm%3A0%2Bt%3A7%2Bf%3A!2%2Cm%3A1%2Bt%3A3%2Bf%3A!2&fields=f12%2Cf14%2Cf2%2Cf127%2Cf267%2Cf268%2Cf269%2Cf270%2Cf271%2Cf272%2Cf273%2Cf274%2Cf275%2Cf276%2Cf257%2Cf258%2Cf124%2Cf1%2Cf13'
result = get_one_data(url)
if result:
print(result)
else:
print("Failed to retrieve or parse data.")
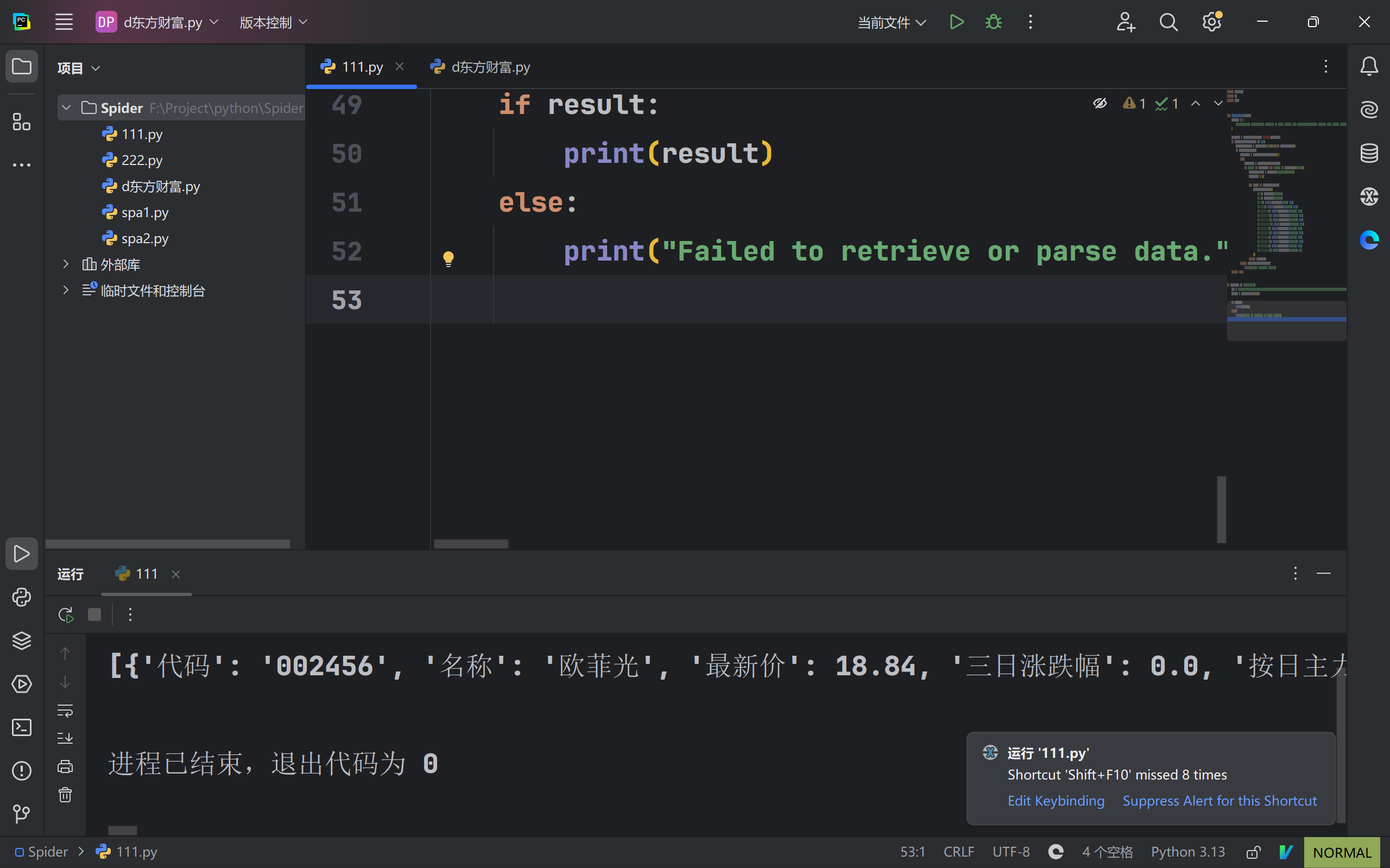
符合预期,继续下一步
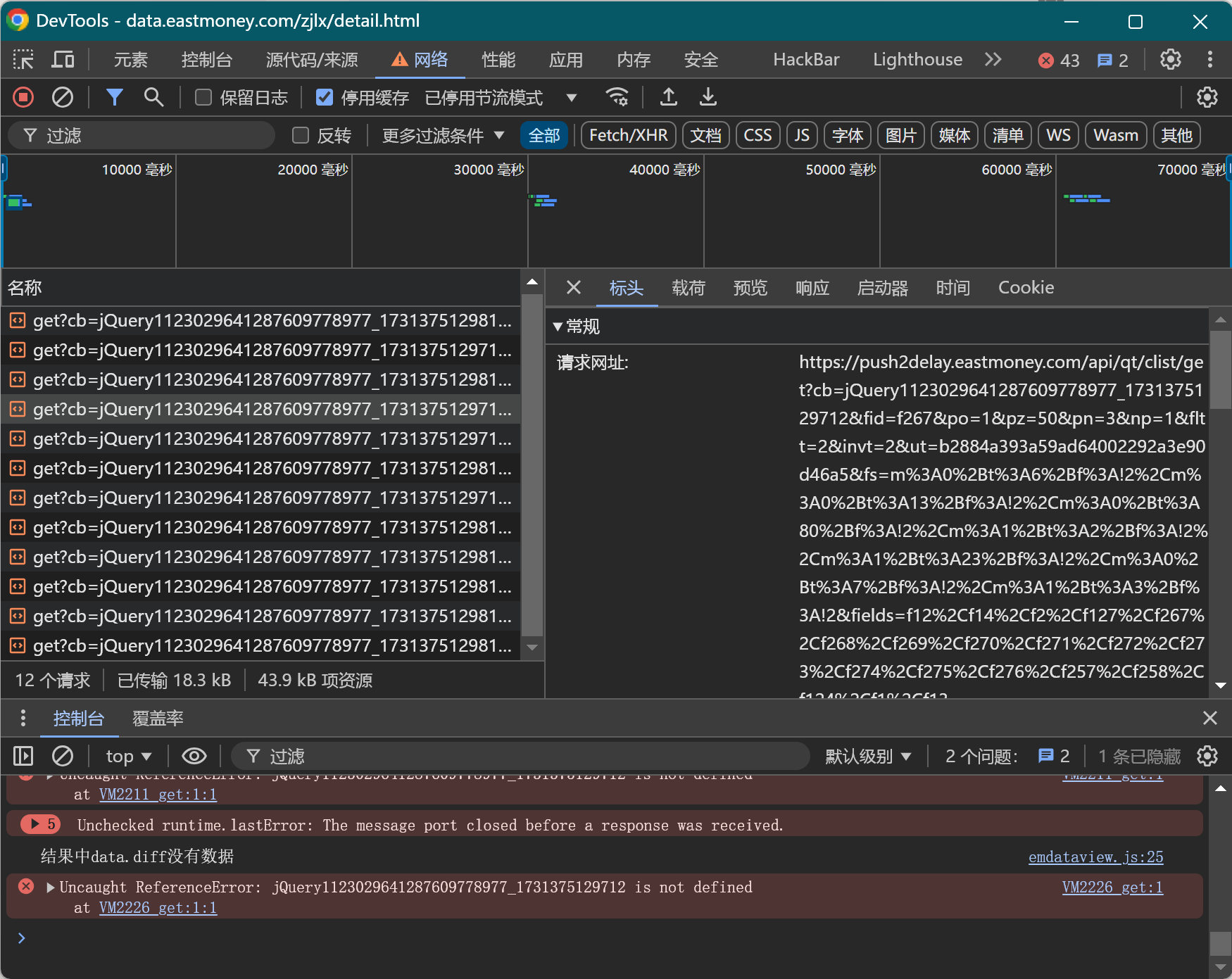
通过翻页观察URL的变化直接找到了偏移值
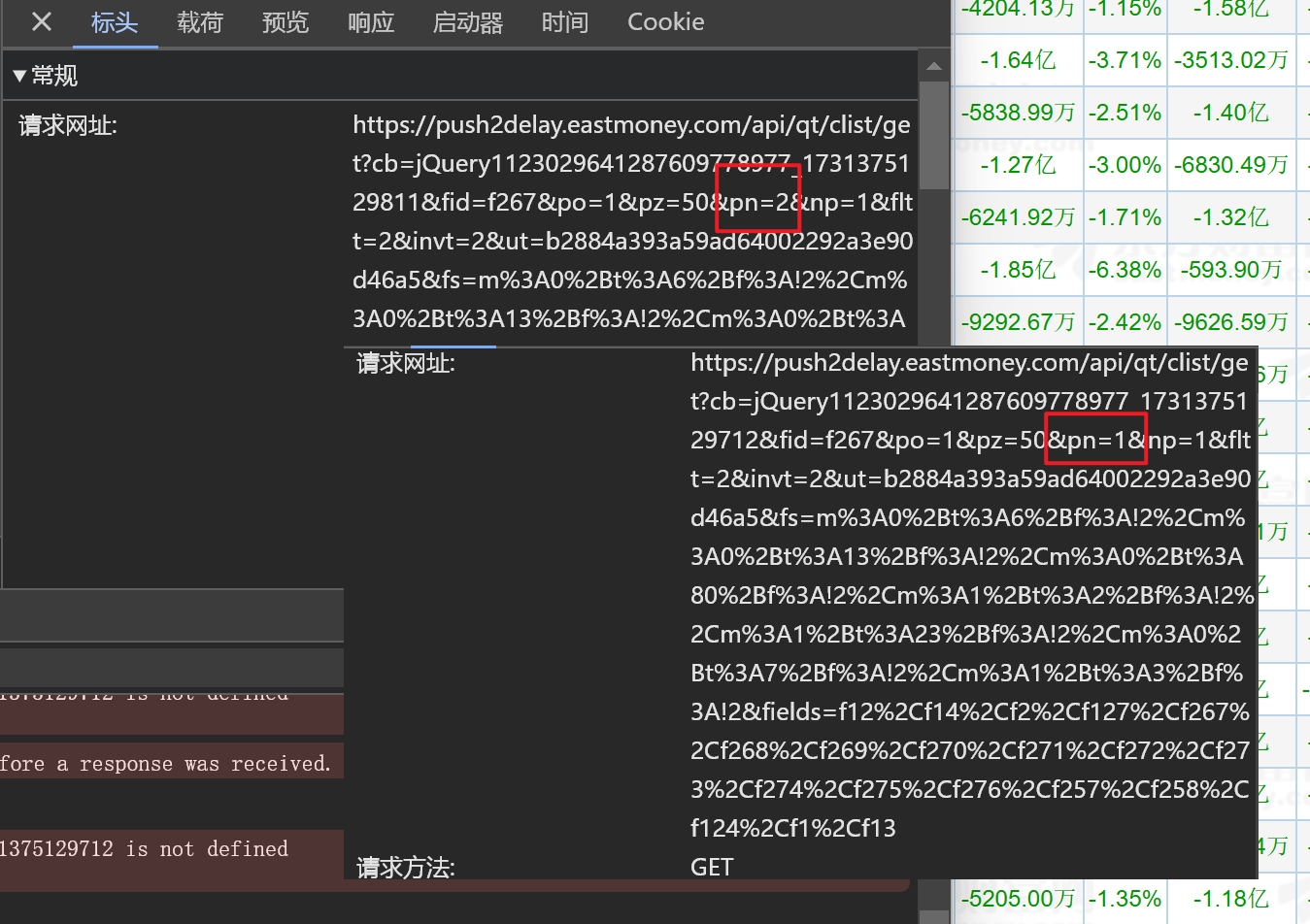
pn就是页数的值
def fetch_and_save_one_page(base_url, page, filename='C:/Users/18127/Desktop/股票.xlsx'):
# 替换页码参数 pn
page_url = base_url.replace("pn=1", f"pn={page}")
print(f"Fetching page {page}...")
result = get_one_data(page_url)
if result:
# 保存数据到 Excel 文件
save_to_excel(result, filename)
else:
print(f"Failed to retrieve data for page {page}.")
注意,在脚本中,url 变量并没有被直接修改,而是通过 page_url = base_url.replace("pn=1", f"pn={page}") 这一行动态地生成了新的 URL
除此方法外,可以直接使用字符串拼接
def get_page_url(base_url, page):
# 直接拼接页码
return f"{base_url}&pn={page}"
def fetch_and_save_one_page(base_url, page, filename='C:/Users/18127/Desktop/股票.xlsx'):
# 使用拼接方法获取页面 URL
page_url = get_page_url(base_url, page)
print(f"Fetching page {page}...")
result = get_one_data(page_url)
if result:
save_to_excel(result, filename)
else:
print(f"Failed to retrieve data for page {page}.")
或者使用 urllib.parse 和 urlencode 方法
from urllib.parse import urlparse, urlencode, parse_qs
def get_page_url(base_url, page):
# 解析原始 URL
url_parts = urlparse(base_url)
query_params = parse_qs(url_parts.query)
# 修改页码参数 pn
query_params['pn'] = [str(page)]
# 重新构建 URL
new_query = urlencode(query_params, doseq=True)
new_url = url_parts._replace(query=new_query).geturl()
return new_url
def fetch_and_save_one_page(base_url, page, filename='C:/Users/18127/Desktop/股票.xlsx'):
# 使用 urllib 来获取新的 URL
page_url = get_page_url(base_url, page)
print(f"Fetching page {page}...")
result = get_one_data(page_url)
if result:
save_to_excel(result, filename)
else:
print(f"Failed to retrieve data for page {page}.")
在最终执行时通过循环实现页数的增长,而且可以确保每抓取一页保存一次添加到excel文件中
for page in range(1, total_pages + 1):
fetch_and_save_one_page(url, page)
完善一些细节,如"最新价"的数值可能显示为"-",添加一些错误判断和文件检索等
先爬取10页测试
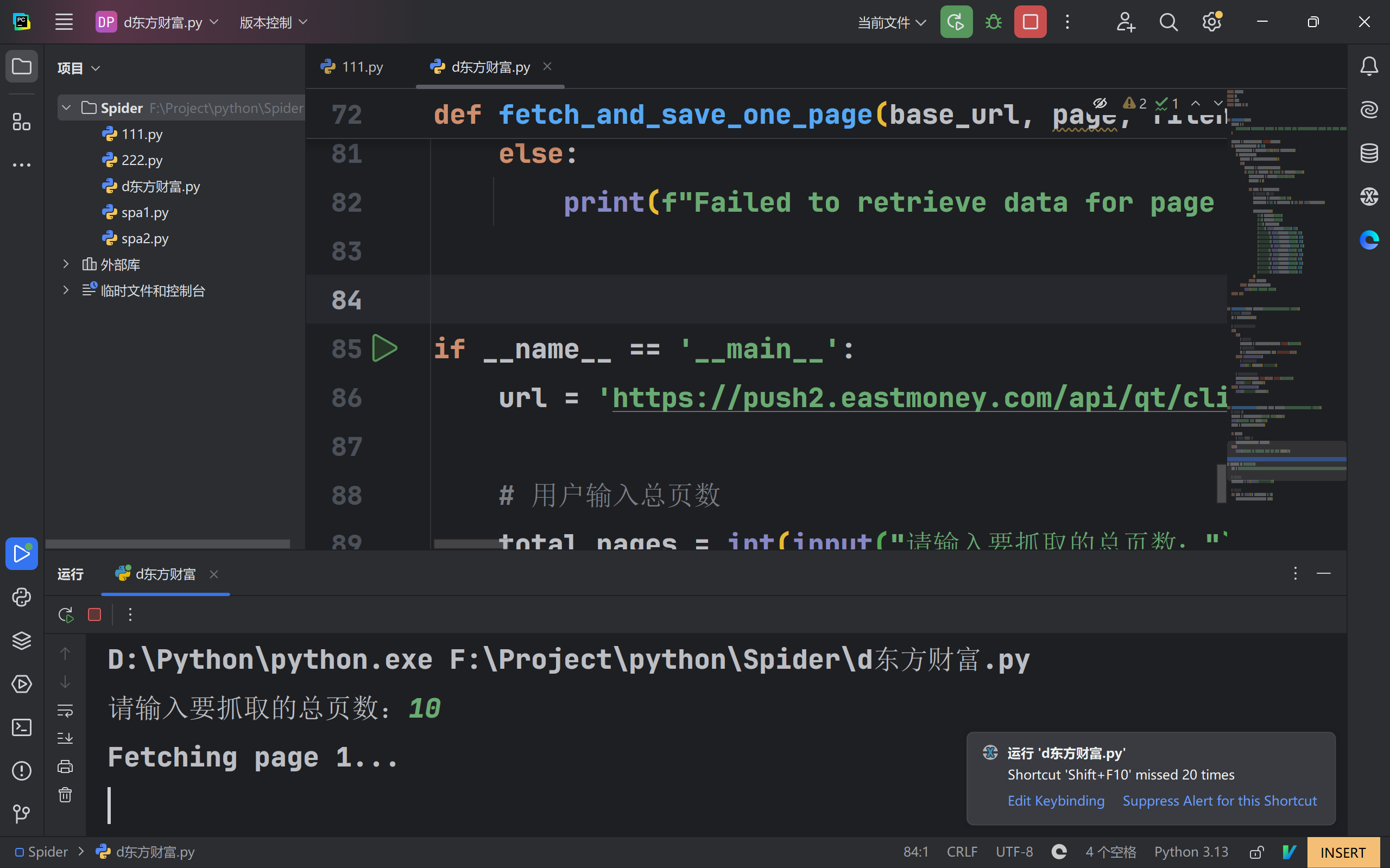
完整代码
import requests
import re
import json
import pandas as pd
def get_one_data(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
json_data_match = re.search(r'\((.*)\)', response.text)
if json_data_match:
json_data = json_data_match.group(1)
try:
data_dict = json.loads(json_data)
if 'data' in data_dict and 'diff' in data_dict['data']:
extracted_data = data_dict['data']['diff']
data_list = []
for entry in extracted_data:
# 处理各个字段可能为 '-' 的情况
latest_price = entry.get("f2", "-")
latest_price = 0.0 if latest_price == "-" else float(latest_price)
data_list.append({
"代码": entry.get("f12"),
"名称": entry.get("f14"),
"最新价": latest_price,
"三日涨跌幅": float(entry.get("f172", 0)),
"按日主力净流入净额": float(entry.get("f267", 0)),
"三日主力净流入净占比": float(entry.get("f268", 0)),
"三日超大单净流入净额": float(entry.get("f269", 0)),
"三日超大单净流入净占比": float(entry.get("f270", 0)),
"三日大单净流入净额": float(entry.get("f271", 0)),
"三日大单净流入净占比": float(entry.get("f272", 0)),
"三日中单净流入净额": float(entry.get("f273", 0)),
"三日中单净流入净占比": float(entry.get("f274", 0)),
"三日小单净流入净额": float(entry.get("f275", 0)),
"三日小单净流入净占比": float(entry.get("f276", 0))
})
return data_list
except json.JSONDecodeError:
print("Error decoding JSON.")
return None
def save_to_excel(data, filename='C:/Users/18127/Desktop/股票.xlsx'):
# 将数据转换为 DataFrame
df = pd.DataFrame(data)
# 如果文件存在,则读取现有数据并追加新数据
try:
try:
# 尝试读取现有文件
existing_df = pd.read_excel(filename, engine='openpyxl')
# 将新数据添加到现有数据
df = pd.concat([existing_df, df], ignore_index=True)
except FileNotFoundError:
# 如果文件不存在,跳过此步骤
print(f"文件 {filename} 不存在,创建新文件。")
# 保存(无论是创建新文件还是追加数据)
df.to_excel(filename, index=False, engine='openpyxl')
print(f"数据已保存到 {filename}")
except FileNotFoundError:
print(f"无法保存文件到路径:{filename}")
def fetch_and_save_one_page(base_url, page, filename='C:/Users/18127/Desktop/股票.xlsx'):
# 替换页码参数 pn
page_url = base_url.replace("pn=1", f"pn={page}")
print(f"Fetching page {page}...")
result = get_one_data(page_url)
if result:
# 保存数据到 Excel 文件
save_to_excel(result, filename)
else:
print(f"Failed to retrieve data for page {page}.")
if __name__ == '__main__':
url = 'https://push2.eastmoney.com/api/qt/clist/get?cb=jQuery1123029641287609778977_1731375129708&fid=f267&po=1&pz=50&pn=1&np=1&fltt=2&invt=2&ut=b2884a393a59ad64002292a3e90d46a5&fs=m%3A0%2Bt%3A6%2Bf%3A!2%2Cm%3A0%2Bt%3A13%2Bf%3A!2%2Cm%3A0%2Bt%3A80%2Bf%3A!2%2Cm%3A1%2Bt%3A2%2Bf%3A!2%2Cm%3A1%2Bt%3A23%2Bf%3A!2%2Cm%3A0%2Bt%3A7%2Bf%3A!2%2Cm%3A1%2Bt%3A3%2Bf%3A!2&fields=f12%2Cf14%2Cf2%2Cf127%2Cf267%2Cf268%2Cf269%2Cf270%2Cf271%2Cf272%2Cf273%2Cf274%2Cf275%2Cf276%2Cf257%2Cf258%2Cf124%2Cf1%2Cf13'
# 用户输入总页数
total_pages = int(input("请输入要抓取的总页数:"))
# 每页抓取并保存
for page in range(1, total_pages + 1):
fetch_and_save_one_page(url, page)

















 3504
3504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









