






数据分析及应用
一个数据挖掘算法砖家。分享Python大数据分析、数据挖掘算法等技术干货
目录
1.项目背景
2.数据集介绍
3.技术工具
4.导入数据
5.数据可视化
5.1分析性别比例
5.2年龄分布
5.3购物种类分析
5.4产品型号分析
5.5其他分析
6.总结
1.项目背景
随着现代电子商务的飞速发展,顾客购物数据量也在飞速增长。这些数据包含了丰富的信息,如消费者的购买习惯、喜好、趋势等。然而,如何有效地处理和利用这些数据,使其为商业决策提供有价值的洞见,成为了一个重要的问题。为此,通过数据可视化技术,将复杂的数据转化为直观、易理解的图形,可以帮助企业更好地理解市场和消费者行为,进一步优化商业决策。
顾客购物数据的可视化具有广泛的应用场景。例如,商家可以通过对顾客的购买历史进行分析,了解顾客的购买习惯和喜好,从而为他们推荐更符合其需求的产品或服务。此外,商家还可以通过数据可视化来识别销售趋势,预测未来的销售情况,从而制定更有效的销售策略。
本项目旨在通过数据可视化技术,对顾客购物数据进行深入挖掘和分析,为商家提供全面的市场分析和商业洞察。通过使用先进的数据可视化工具和技术,我们将从大量的顾客购物数据中提取有价值的信息,并通过直观的图形展示出来,帮助商家更好地理解市场和消费者行为,优化商业决策。
2.数据集介绍
该数据集来源于kaggle,原始数据集共有3900条,18个特征变量,各变量含义解释如下:
Customer ID- 每个客户的唯一标识符
Age- 顾客的年龄
Gender- 顾客的性别(男/女)
Item Purchased- 客户购买的商品
Category- 购买商品的类别
Purchase Amount (USD)- 以美元计的购买金额
Location- 购买地点
Size- 购买商品的尺寸
Color- 购买商品的颜色
Season- 购买的季节
Review Rating- 客户对所购买商品的评分
Subscription Status- 指示客户是否有订阅(是/否)
Shipping Type- 客户选择的运输类型
Discount Applied- 指示购买时是否应用折扣(是/否)
Promo Code Used- 指示购买时是否使用了促销代码(是/否)
Previous Purchases- 客户先前购买的次数
Payment Method- 客户最喜欢的付款方式
Frequency of Purchases- 客户购买的频率(例如每周、每两周、每月)
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.导入数据
首先导入本次实验用到的可视化第三方库,并加载数据集
-
import matplotlib.pyplot as plt -
data=pd.read_csv("shopping_trends_updated.csv")
接着查看一下数据集的基本信息
-
print(f'data shape : {data.shape}') -
sum=pd.DataFrame(data.dtypes,columns=['data type']) -
sum["Missing"]=data.isnull().sum() -
sum["%Missing"]=(data.isnull().sum()/len(data))*100 -
sum['#unique']=data.nunique().values -
desc=pd.DataFrame(data.describe(include="all").transpose()) -
sum['min']=desc['min'].values -
sum['max']=desc['max'].values -
sum['first value']=data.loc[0].values -
sum['second value']=data.loc[1].values -
sum['Third value']=data.loc[2].values
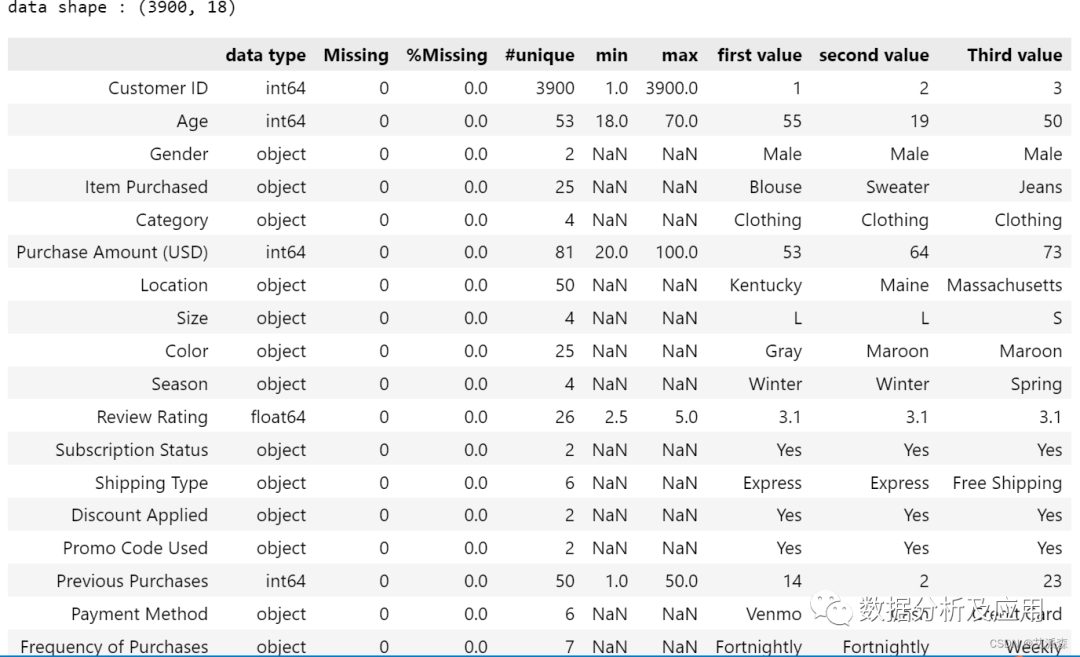
可以发现该数据集的形状为(3900,18)。在这个数据中,有13个分类列和5个数值列。没有缺失值。客户总数为3900。
5.数据可视化
5.1分析性别比例
-
colors = ["#89CFF0", "#FF69B4", "#FFD700", "#7B68EE", "#FF4500", -
"#9370DB", "#32CD32", "#8A2BE2", "#FF6347", "#20B2AA", -
"#FF69B4", "#00CED1", "#FF7F50", "#7FFF00", "#DA70D6"] -
plt.figure(figsize=(6, 4)) -
G_vis = data['Gender'].value_counts() -
bars = plt.bar(G_vis.index, G_vis.values, color='gray') -
plt.ylabel('Number of Gender') -
plt.title('Gender Distribution') -
plt.text(bar.get_x() + bar.get_width() / 2, bar.get_height(), str(int(bar.get_height())), ha='center', va='bottom')
-
plt.figure(figsize = (20, 6)) -
counts = data["Gender"].value_counts() -
counts.plot(kind = 'pie', fontsize = 12, colors = colors, explode = explode, autopct = '%1.1f%%') -
plt.xlabel('Gender', weight = "bold", color = "#2F0F5D", fontsize = 14, labelpad = 20) -
plt.legend(labels = counts.index, loc = "best")
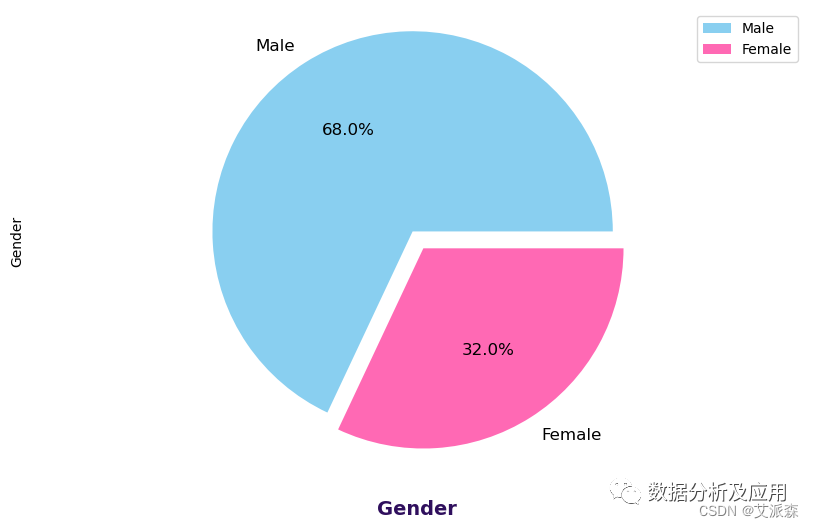
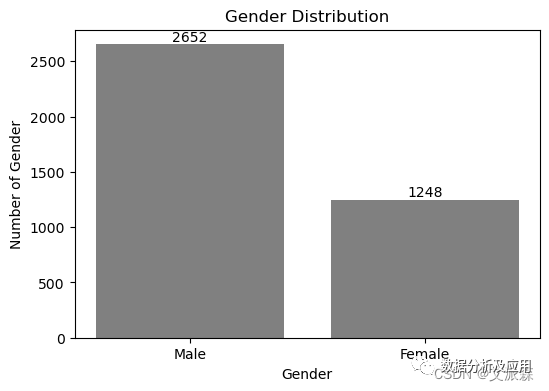
可以看出该数据集的顾客是男性多于女性的。
5.2年龄分布
-
plt.figure(figsize=(8, 4)) -
plt.hist(data['Age'],edgecolor = 'black',alpha=0.7,bins=25,color = 'skyblue',density=True) -
data['Age'].plot(kind='kde', color = 'red') -
plt.ylabel('Count / Density') -
plt.title('Age Distribution Histogram with Density Curve') -
plt.legend(['Density Curve', 'Histogram'])
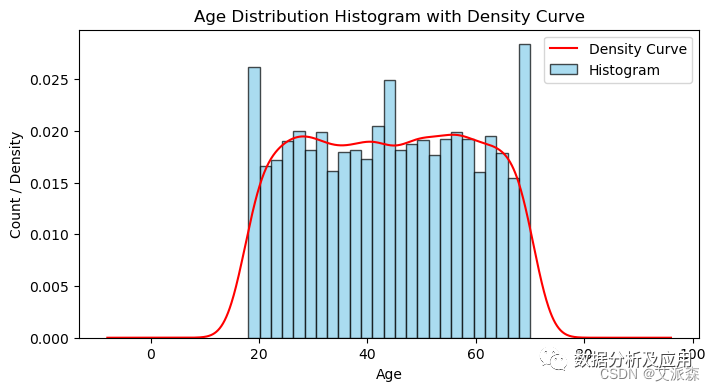
顾客的年龄主要分布在20-70岁之间。
5.3购物种类分析
-
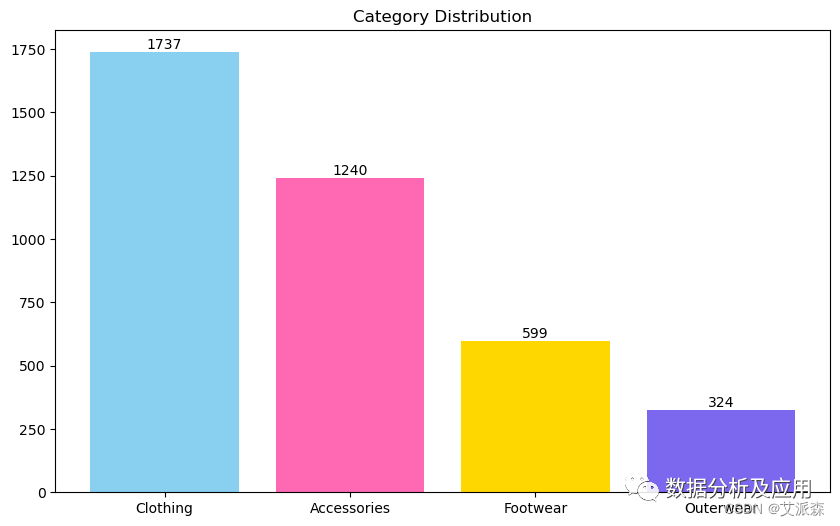
plt.figure(figsize = (10, 6)) -
c=data["Category"].value_counts() -
bar=plt.bar(c.index,c.values,color=colors) -
plt.text(bar.get_x() + bar.get_width() / 2, bar.get_height(), str(int(bar.get_height())), ha='center', va='bottom') -
plt.title('Category Distribution')
-
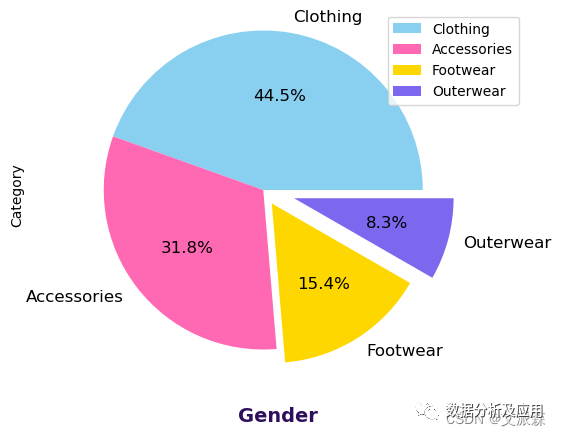
counts = data["Category"].value_counts() -
explode = (0, 0.0, 0.1, 0.2) -
counts.plot(kind = 'pie', fontsize = 12, colors = colors, explode = explode, autopct = '%1.1f%%') -
plt.xlabel('Gender', weight = "bold", color = "#2F0F5D", fontsize = 14, labelpad = 20) -
plt.legend(labels = counts.index, loc = "best")
-
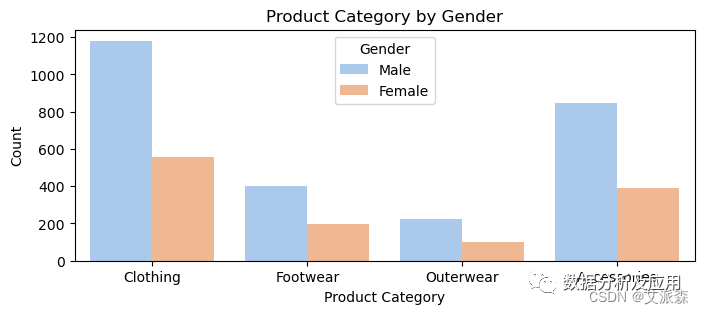
plt.figure(figsize=(8, 3)) -
sns.countplot(data=data, x='Category', hue='Gender',palette='pastel') -
plt.title('Product Category by Gender') -
plt.xlabel('Product Category') -
plt.legend(title='Gender', labels=data['Gender'].unique())
-
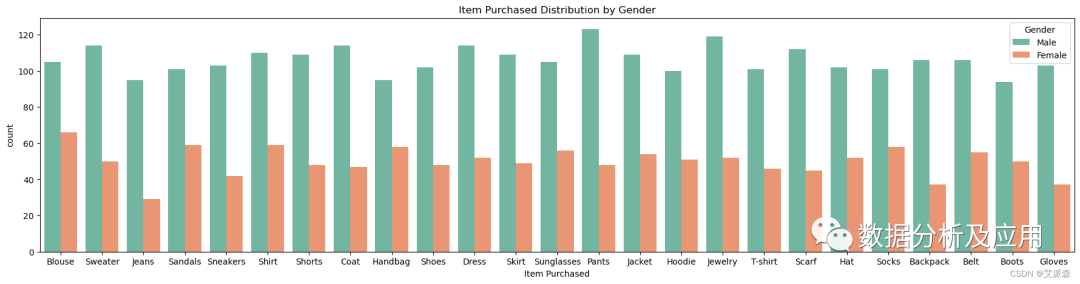
plt.figure(figsize=(22,5)) -
sns.countplot(data=data,x='Item Purchased',hue='Gender',palette='Set2') -
plt.title('Item Purchased Distribution by Gender')
5.4产品型号分析
-
count=data['Size'].value_counts() -
plt.figure(figsize=(6,4)) -
bars=plt.bar(count.index,count.values,color=colors) -
plt.annotate(f'{bar.get_height()}', (bar.get_x() + bar.get_width() / 2., bar.get_height()), ha='center', va='center', fontsize=9, color='black', xytext=(0, 5), textcoords='offset points')
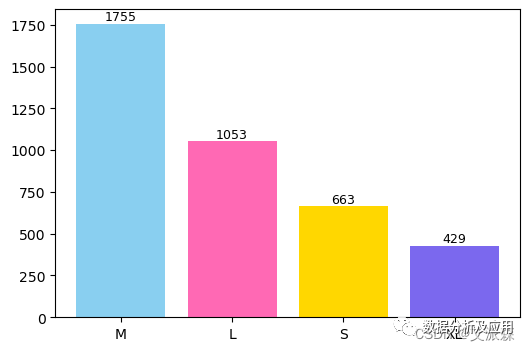
-
sns.countplot(data=data,x='Size' ,hue='Gender')
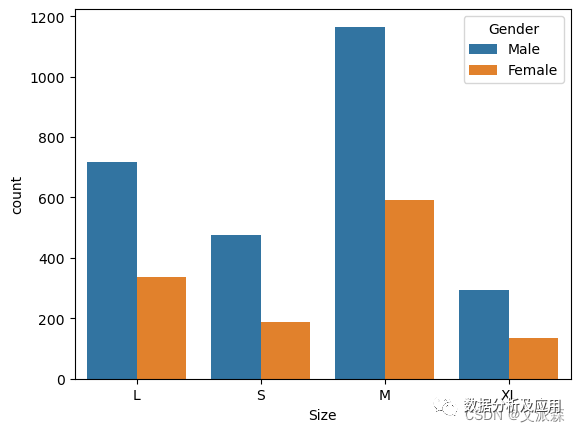
-
plt.figure(figsize=(15,5)) -
sns.countplot(data=data,x='Category' ,hue='Size') -
plt.title('Category distribution by Gender')
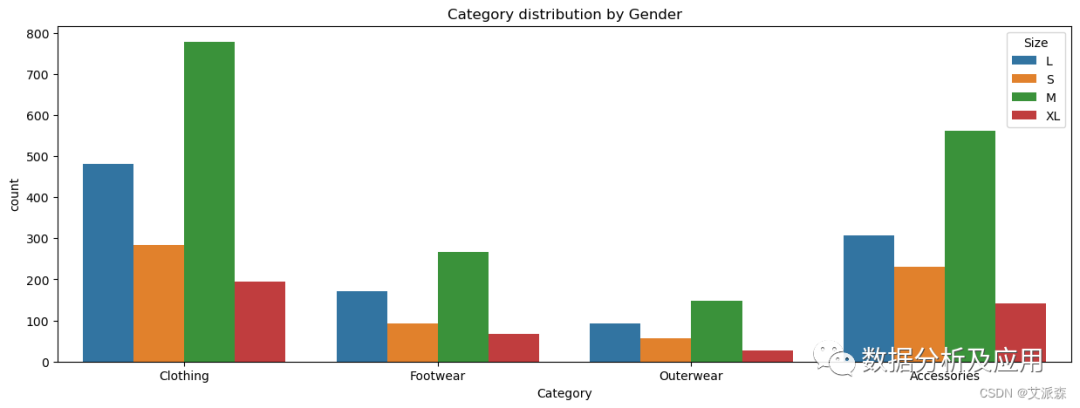
-
plt.figure(figsize=(10,20)) -
sns.countplot(data=data,y='Item Purchased',hue='Size') -
plt.ylabel('Item Purchased', fontsize=10) -
plt.xlabel('\nNumber of Occurrences', fontsize=10) -
plt.title('Item Purchased by Gender\n', fontsize=10)
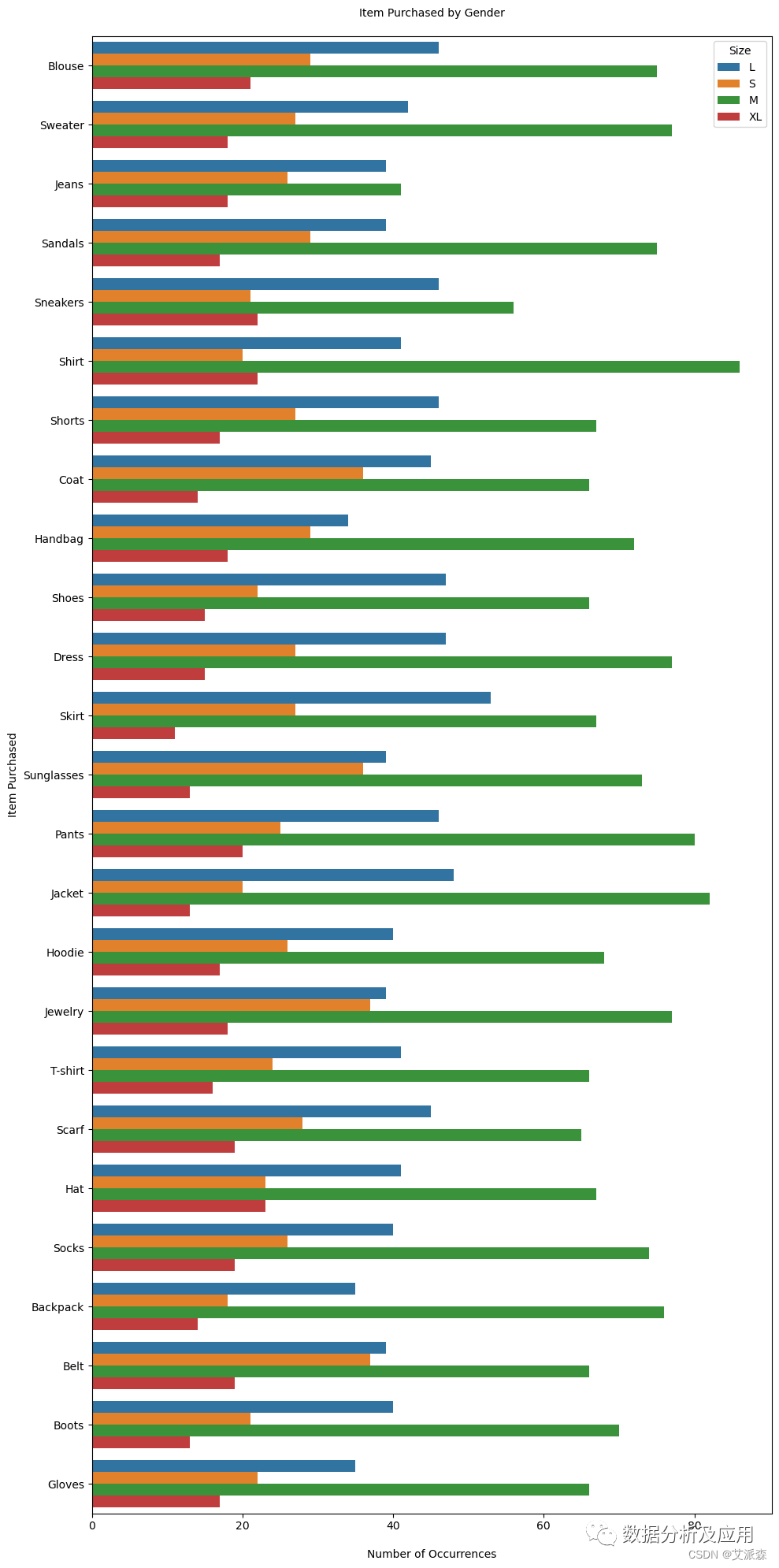
5.5其他分析
-
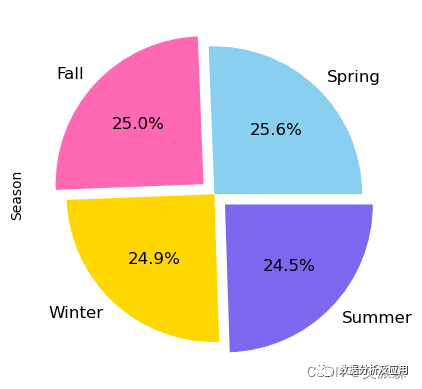
count=data['Season'].value_counts() -
count.plot(kind='pie',colors=colors,fontsize=12,explode=(0,0.1,0,0.1),autopct='%1.1f%%')
-
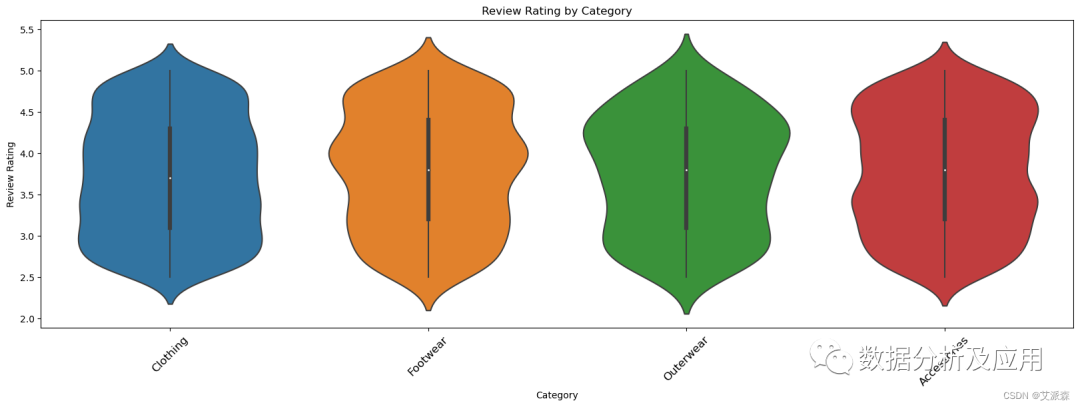
plt.figure(figsize=(20, 6)) -
sns.violinplot(x='Category', y='Review Rating', data=data) -
plt.title('Review Rating by Category') -
plt.ylabel('Review Rating') -
plt.xticks(rotation=45,fontsize=12)
-
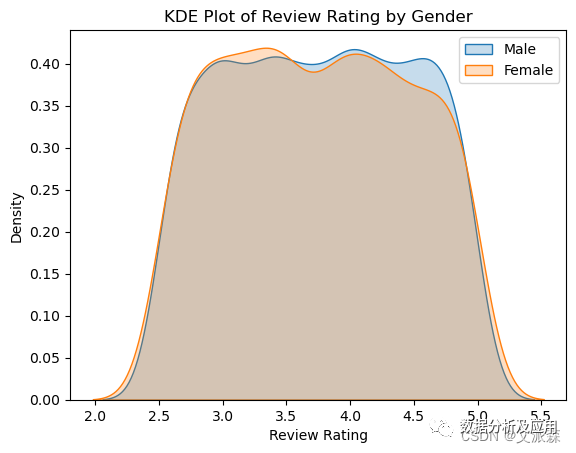
sns.kdeplot(data[data['Gender'] == 'Male']['Review Rating'], label='Male', shade=True) -
sns.kdeplot(data[data['Gender'] == 'Female']['Review Rating'], label='Female', shade=True) -
plt.title('KDE Plot of Review Rating by Gender') -
plt.xlabel('Review Rating')
-
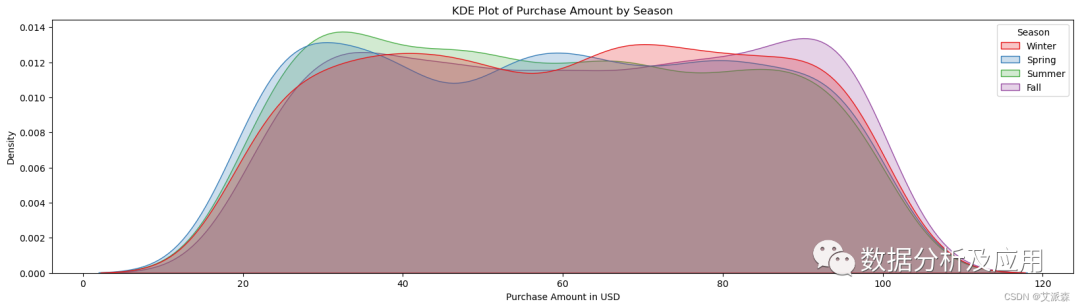
plt.figure(figsize=(20, 5)) -
sns.kdeplot(data = data, x = 'Purchase Amount (USD)', hue = 'Season', common_norm = False, fill = True, palette = 'Set1') -
plt.title('KDE Plot of Purchase Amount by Season') -
plt.xlabel('Purchase Amount in USD')
6.总结
通过本次实验,我们成功地利用数据可视化技术对顾客购物数据进行深入分析,提取了有价值的信息。这些信息可以帮助商家更好地了解市场和消费者行为,优化商业决策。例如,针对消费者的购买习惯周期性特点,商家可以在周末加强促销力度,提高销售额;针对不同地区的销售差异,商家可以制定个性化的销售策略,提高市场占有率;针对某品牌的销售上升趋势,商家可以进一步加大市场推广力度,扩大品牌影响力。















 979
979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









