







1、分析商品页面
https://s.taobao.com/search?page=1&q=ipad&tab=all
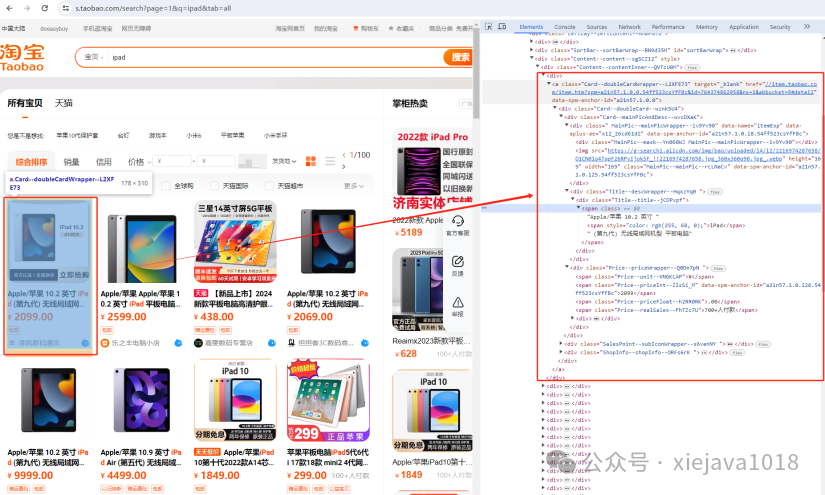
通过Chrome浏览器输入淘宝搜索商品页面链接F12打开开发者工具,分析淘宝搜索商品列表页的源代码,找到商品展示相关源代码包括商品的title、价格、详情页、购买情况等。我们需要通过解析这些源代码获取相应的商品信息。
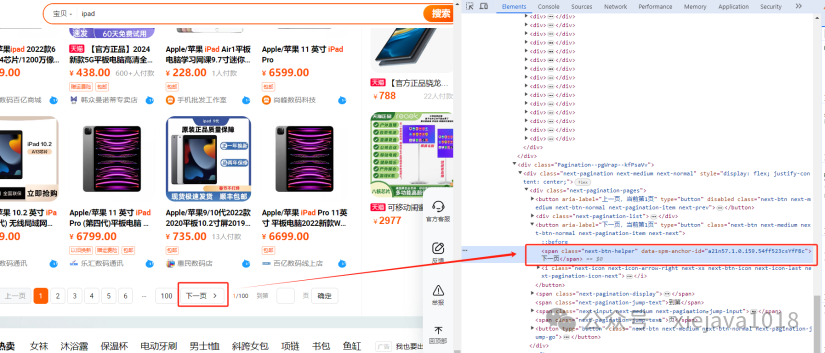
找到下一页翻页的按钮,我们需要控制下一页翻页的按钮来实现自动翻页。
2、实现商品获取代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | # 解析获取商品信息
def get_products():
"""提取商品数据"""
html = driver.page_source
doc = pq(html)
items = doc('.Card--doubleCardWrapper--L2XFE73').items()
for item in items:
product = {'url': item.attr('href'),
'price': item.find('.Price--priceInt--ZlsSi_M').text(),
'realsales': item.find('.Price--realSales--FhTZc7U-cnt').text(),
'title': item.find('.Title--title--jCOPvpf').text(),
'shop': item.find('.ShopInfo--TextAndPic--yH0AZfx').text(),
'location': item.find('.Price--procity--_7Vt3mX').text()}
print(product)
# 自动获取商品信息并自动翻页
def index_page(url,cur_page,max_page):
print(' 正在爬取:'+url)
try:
driver.get(url)
get_products()
next_page_btn = wait.until(EC.element_to_be_clickable((By.XPATH, '//button/span[contains(text(),"下一页")]')))
next_page_btn.click()
do_change = wait.until(EC.url_changes(url))
if do_change and cur_page<max_page:
new_url=driver.current_url
cur_page = cur_page + 1
index_page(new_url,cur_page,max_page)
except TimeoutException:
print('---index_page TimeoutException---')
|
3、实现效果
从浏览器看,Selenium自动访问淘宝登录页,当切到用户名密码登录界面时,Selenium自动输入用户名、密码点击登录。登录成功后,自动访问商品搜索页搜索ipad,进行商信息获取,自动翻下一页。
从后台打印的日志看,显示“开始登录”、“已经登录”,正在爬取的链接和该链接下的商品信息。
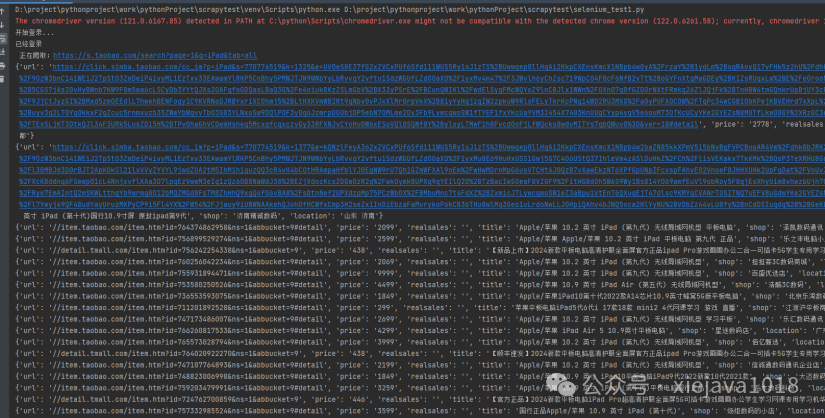
至此,通过Selenium来代码实现模拟登录淘宝并自动爬取商品信息,进行了Selenium的实战。
要注意的是:
1、在Selenium打开登录页面后淘宝默认的是扫码登录,需要人为接入切换用户密码模式。这时也可以让Selenium自动去切到用户密码模式登录。代码如下:
change_type=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ‘.iconfont.icon-password’)))
change_type.click() #切换到用户密码模式登录
2、在运行启动Chrome的远程调试模式,启动Chrome浏览器后,要关闭其他的Chrome浏览器,保留远程调试模式启动的浏览器就好了。如果是存在多个Chrome浏览器Selenium会不知道要接管哪一个。
附上全部完整代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 | from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.common import TimeoutException
from urllib.parse import quote
from pyquery import PyQuery as pq
chrome_options = Options()
chrome_options.add_experimental_option("debuggerAddress", "localhost:9222") #此处端口保持和命令行启动的端口一致
driver = Chrome(options=chrome_options)
wait = WebDriverWait(driver, 10)
# 模拟淘宝登录
def login_taobao():
print('开始登录...')
try:
login_url='https://login.taobao.com/member/login.jhtml'
driver.get(login_url)
change_type=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.iconfont.icon-password')))
change_type.click() #切换到用户密码模式登录
input_login_id = wait.until(EC.presence_of_element_located((By.ID, 'fm-login-id')))
input_login_password = wait.until(EC.presence_of_element_located((By.ID, 'fm-login-password')))
input_login_id.send_keys('your account') # 用你自己的淘宝账号替换
input_login_password.send_keys('your password') # 用你自己的密码替换
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.fm-button.fm-submit.password-login')))
submit.click()
is_loging = wait.until(EC.url_changes(login_url))
return is_loging
except TimeoutException:
print('login_taobao TimeoutException')
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.fm-button.fm-submit')))
submit.click()
is_loging = wait.until(EC.url_changes(login_url))
if is_loging:
return is_loging
else:
login_taobao()
# 解析获取商品信息
def get_products():
"""提取商品数据"""
html = driver.page_source
doc = pq(html)
items = doc('.Card--doubleCardWrapper--L2XFE73').items()
for item in items:
product = {'url': item.attr('href'),
'price': item.find('.Price--priceInt--ZlsSi_M').text(),
'realsales': item.find('.Price--realSales--FhTZc7U-cnt').text(),
'title': item.find('.Title--title--jCOPvpf').text(),
'shop': item.find('.ShopInfo--TextAndPic--yH0AZfx').text(),
'location': item.find('.Price--procity--_7Vt3mX').text()}
print(product)
# 自动获取商品信息并自动翻页
def index_page(url,cur_page,max_page):
print(' 正在爬取:'+url)
try:
driver.get(url)
get_products()
next_page_btn = wait.until(EC.element_to_be_clickable((By.XPATH, '//button/span[contains(text(),"下一页")]')))
next_page_btn.click()
do_change = wait.until(EC.url_changes(url))
if do_change and cur_page<max_page:
new_url=driver.current_url
cur_page = cur_page + 1
index_page(new_url,cur_page,max_page)
except TimeoutException:
print('---index_page TimeoutException---')
if __name__ == '__main__':
is_loging=login_taobao()
if is_loging:
print('已经登录')
KEYWORD = 'iPad'
url = 'https://s.taobao.com/search?page=1&q=' + quote(KEYWORD) + '&tab=all'
max_page=10
index_page(url,1,max_page)
|















 4304
4304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









