






小说推文跟抄小说是一个性质,都是用复制小说做成视频的形式,帮小说平台拉新用户、新会员,以此来拿到平台给的提成,也就是佣金。
但是抄书的性质完全跟推文不一样!
1、什么叫小说推文/抄小说?
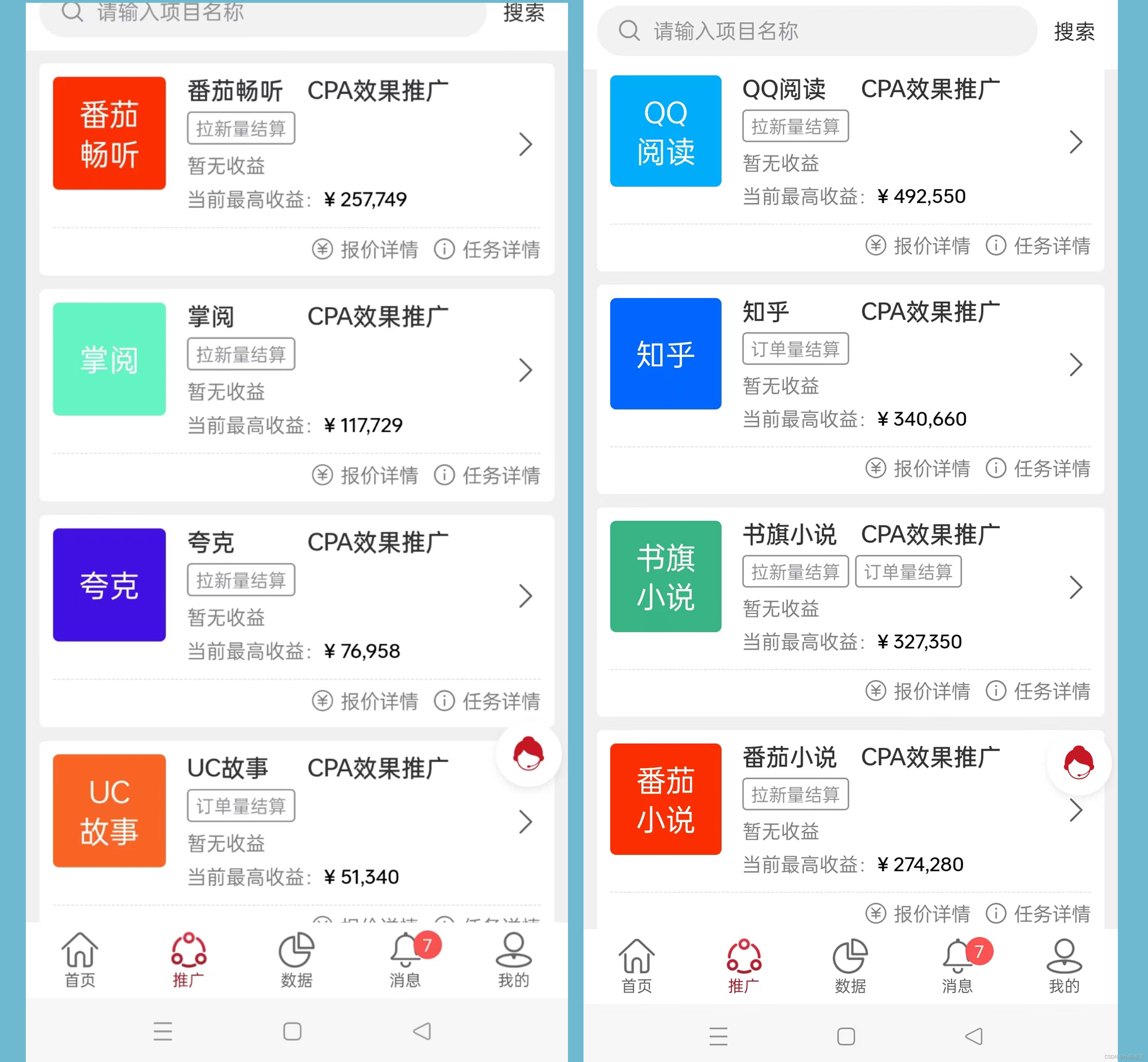
小说推文准确说是博主帮平台拉新用户、拉回老用户、拉会员,来拿提成;比如知乎,小说推文博主帮知乎拉会员,会员9.9元、博主拉到了一个就能得到7块钱佣金。
比如番茄小说,博主帮番茄小说平台拉到新用户,可以拿到8块钱佣金!
最高的像抖音故事推文,拉会员模式可以拿到12元一单的佣金!
现在小说推文的单价在7-12元,这个佣金不算低了,选择的平台也多,都是给知名平台官方干活,有一定的保障,只要肯努力、肯花心思运营下账号,就可以用这个赚钱当副业、甚至全职。

推文适合大学生、宝妈、上班做副业、想全职自媒体的伙伴!不适合非常非常忙的人,因为找小说、剪辑也需要一点时间成本。
小说推文发展到现在已经成为了一个项目,有知乎、番茄小说、番茄畅听、掌阅、书旗小说、七猫小说、UC故事、抖音故事、起点、飞卢、夸克、今日头条等一些知名的平台推出的项目;
只要小程序或者授权团队拿到授权,就可以直接推广小说,很多团队都是公司化运营,小程序也是能看到小说平台的官方活动奖励,提现也可以自提,不用担心被骗。
2、为什么说抄小说跟抄书是不一样的?
如果说抄小说就是小说推文,那么抄书就是赚取抖音中视频的钱了。
抄书是把一篇好看、励志的复制出来,放到风景视频上,做成横屏视频,发布到抖音,赚抖音、西瓜视频、今日头条三个平台的中视频播放量收益。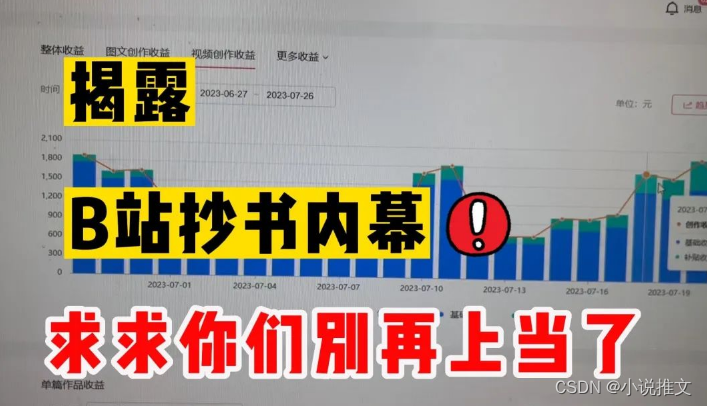
赚取播放量的收益是不稳定的,一但视频没爆或者播放量没几个,收益就几分钱、几毛钱,一顿操作下来什么都拿不到,能赚到抄书钱的是哪种人呢?
是已经把抖音账号做起来了的博主!这种博主发出来的播放量才高,可以赚取抖音播放量的收益,可是想要做到这一步很难!尤其是对新人来说真的非常非常难;
不过中视频达到很高的播放量确实可以赚钱,可做出高播放量视频不容易,对比下来也没有小说推文稳定。
现在抖音就有很多教大家抄书赚钱的,想想,如果真的有这么赚钱,为什么自己不偷摸赚?
而是发布出来让你们做,让同行多一个竞争力?错!大错特错!真有这么好心吗?
所以,小说推文抄小说跟抄书没有任何关系,也不等于抄书,抄书收益是不稳定的,想要做起来困难度非常高,小说推文的话,直接零粉丝就可以做,而且很快可以做出订单量,看到实实在在的佣金到手。
3、可不可以做小说推文的同时也做中视频?
不可以!
中视频有三个要求达到才能做!
(1)三个视频达到17000播放量
(2)横屏视频
(3)原创
小说推文视频刚发布有流量扶持,达到17000播放量很简单,也可以做成横屏推文,但横屏不代表就是中视频了,因为原创这点小说推文过不了审。
为什么呢?
小说推文的操作过程是复制小说平台里的小说,来制作视频发布,光是这一点就不是原创了,小说是平台作者里面著作的,不属于自己原创因此无法过抖音中视频审核。

















 1261
1261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









