






1.前言
首先,c++兼容c语言百分之九十八、九十九的内容,可以认为这是两种不分家的语言
c的语法几乎能在c++上都能跑
在一个后缀为.cpp的文件中,我们以面向过程的思考(C语言的逻辑)写下如下代码:
#include <stdio.h>
int main(){
printf("hello world");
return 0;
} (这是一个cpp项目,跑起来没有任何问题)
(这是一个cpp项目,跑起来没有任何问题)
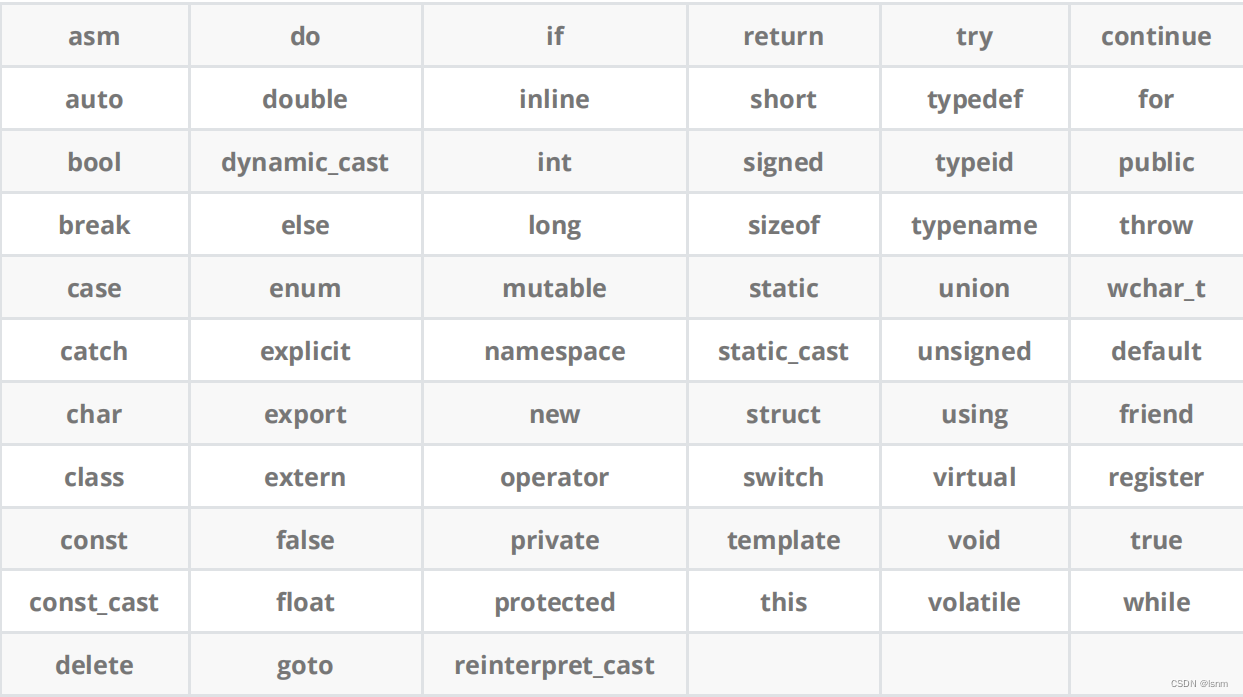
2. 认识C++关键字(C++98)
3.cpp解决了c的一些不足
#include <stdio.h>
int rand=2;
int main()
{
printf("%d",rand);
return 0;
}在C的环境中,以上代码能够跑起来,但若稍加修改:
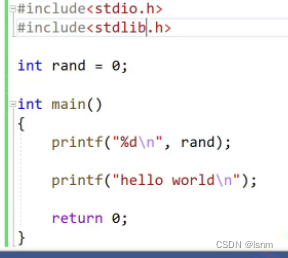
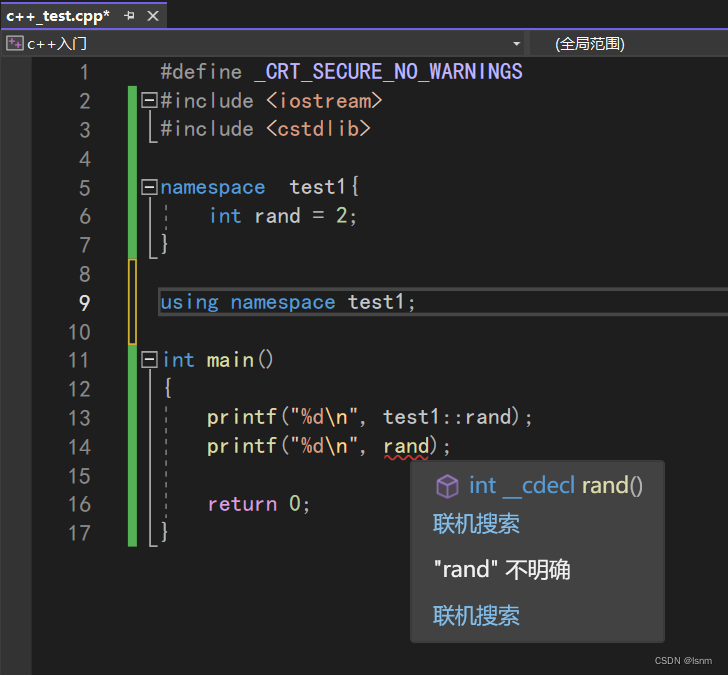
出现问题:命名冲突,rand是函数还是变量?
程序员自己写的东西和库中的名字可能发生冲突。
由此,c++之父本贾尼(Bjarne)创造了namespace
补充:但如果这个rand变量在main函数内或者其他任意类域内定义,则会因为优先级的原因而不发生冲突,这一点在之后会讲解。
4. namespace命名空间(熟记三种使用方法)
在 C++ 中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,这可能会导致很多冲突。尤其是在工程项目中,每一个人写的部分都有可能使用相同名字的变量。使用命名空间的目的是对标识符的名称进行本地化 , 以避免命名冲突或名字污染 , namespace 关键字的出现就是针对这种问题的
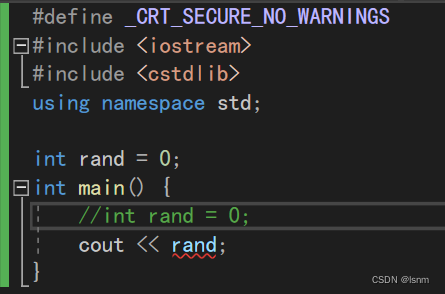
我们利用namespace解决上文中rand的问题:
正如上图中使用的那样,namespace相当于开辟了一个新的作用域。在不同的作用域中, 域,可以做到名字的隔离。
此时,变量的名字是可以相同的,他们不会被报错。就像全局变量和局部变量都定义一个a,但是编译器不会把他们当作同一个a。
我们会发现,直接使用rand时,打印的结果任然是一个伪随机数。
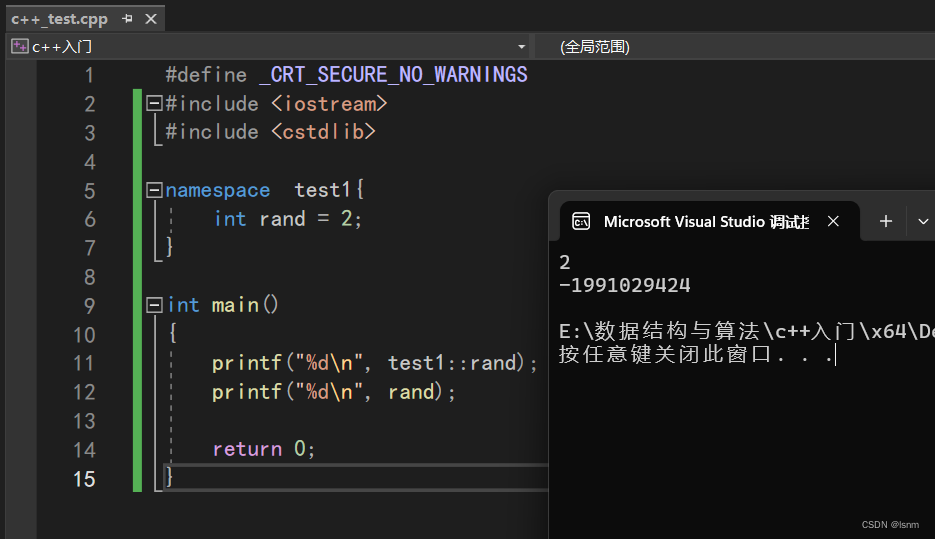
如何使用我们取名为test1中的变量?
有以下三种方法:
方法1:
printf("%d",test1::rand);如上图中所写,我们使用两个冒号::来从一个命名空间中展开该作用域的该变量。
方法2:
全部展开该命名空间,其任然作为一个单独的作用域存在,不过此处仍然与rand函数相冲突。因此,在项目中,全部展开也是不常使用的。
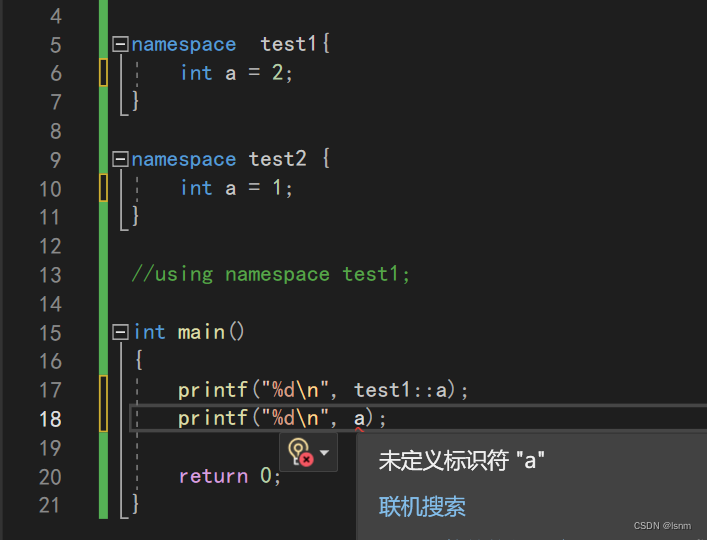
可见,不展开就找不到a是谁。
编译器默认的查找顺序是:优先当前的局部变量,再全局变量,再或者到展开的命名空间中查找。
请注意:全局域中寻找和到展开的命名空间中查找是同时、同等级进行的。因此,如果一个被展开的命名空间中有函数add,全局域中也有函数add,就会报错。
方法3:
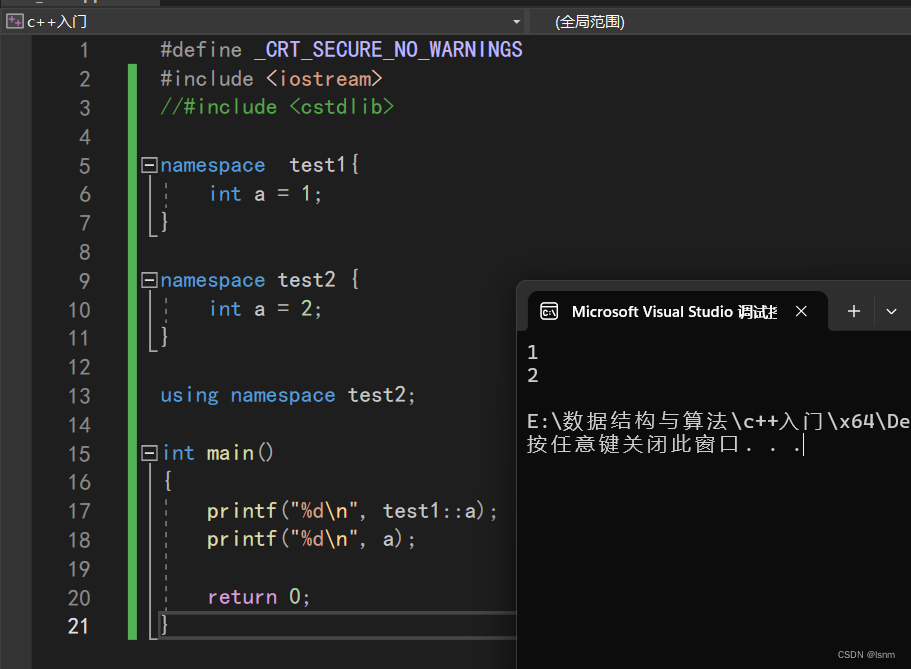
如果一个数据经常使用且没有重名变量,又不便于整个展开namespace,那我们可以指定展开该变量。

在介绍完大致的使用后,命名空间的以下几点值得注意:
1.命名空间是可以嵌套定义的。
2.命名空间都是“全局变量”,其作用域为整个工程
3.同名的命名空间会被合并成同一个,变成同一个作用域,因此相同命名空间时不能定义同名变量。
4.库函数中的变量名使用时需要展开
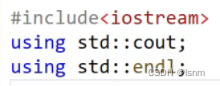
using namespace std;否则,cin或者cout等就无法再使用(后文会对这两种操作作出解释)
工程文件中任然不建议直接展开,但是在平时的练习、做题中,直接展开即可。
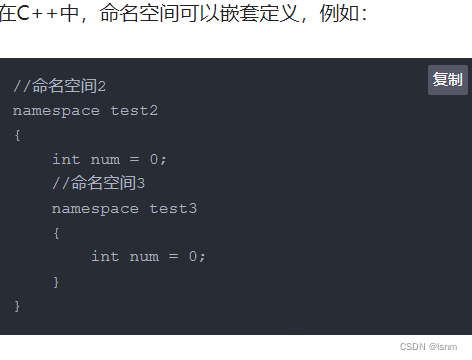
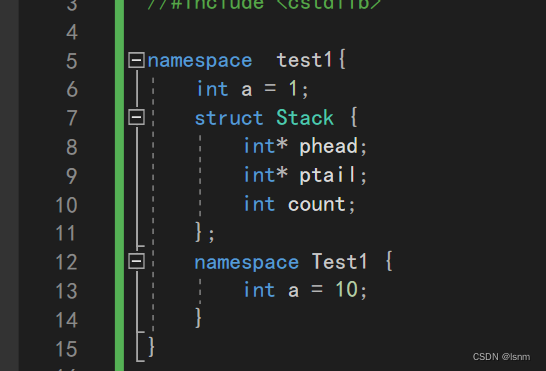
可嵌套,嵌套中也可重名。
另外,展开命名空间不同于展开头文件。头文件被展开是在编译过程中完全写入.c文件里namespace的展开更类似于是给这一块的作用域贴上标签:“我可以被使用了”因此,编译器的查找范围是:优先到当前局部变量中找,再到全局域中找,还能自由到被展开的命名空间中找
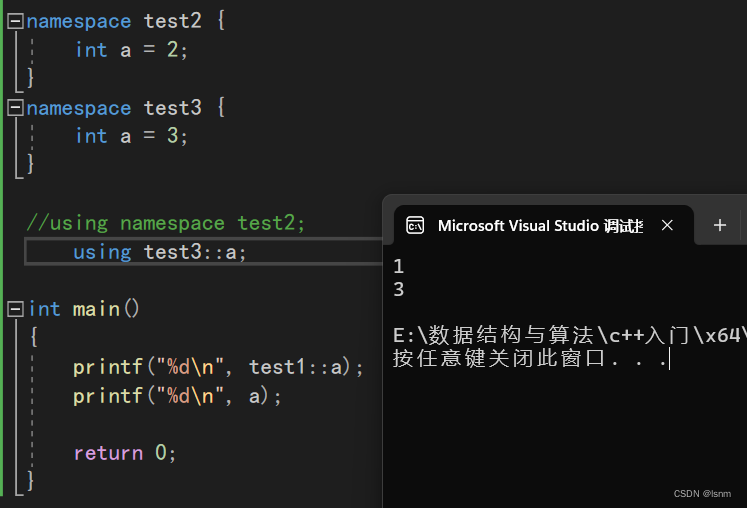
展开之后可能的问题:全局变量和命名空间中的变量重复,会冲突。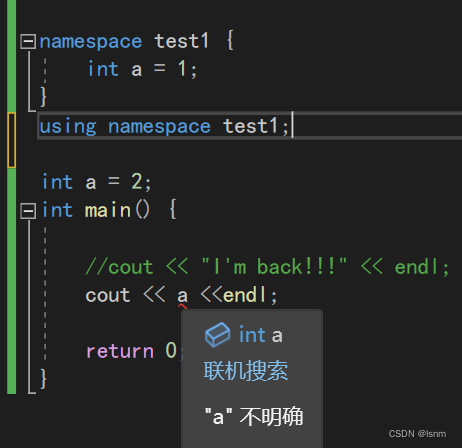 命名空间中test1的a和命名空间test2的a同时被展开,冲突,编译器任然无法识别。
命名空间中test1的a和命名空间test2的a同时被展开,冲突,编译器任然无法识别。
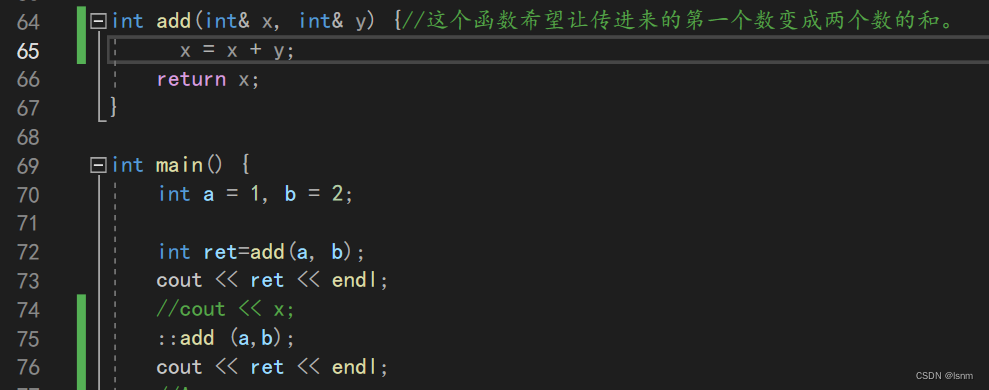
如果在使用::前不加命名空间的名字,就是直接对全局域(不查找单独命名空间)中的 函数 或者 变量 进行查找。
5.cpp的输入和输出
由于cpp兼容c,使用c中的printf和scanf也能实现输入输出。
不过cpp在iostream(in out 流)中设计了cout和cin(console out & console in)
console译为控制台。
两者经常搭配流插入使用(细的方向就是指向)
此处适合搭配文件操作中“流”的概念来理解。
<<:流插入运算符,将右侧的数据放入左侧的流中
>>:流提取运算符,将左侧的数据放入右侧的流中
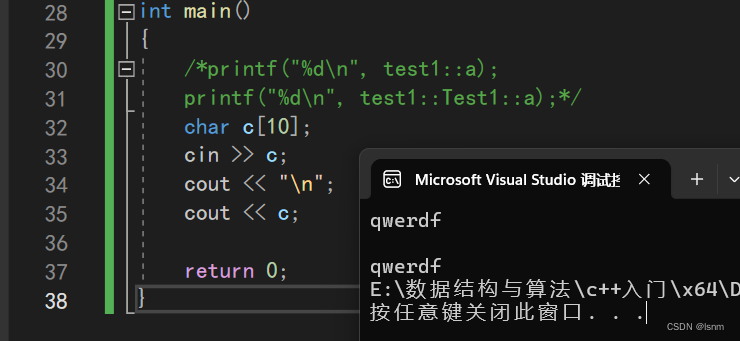
可以连续的写,可以自动识别类型,不需要占位符。
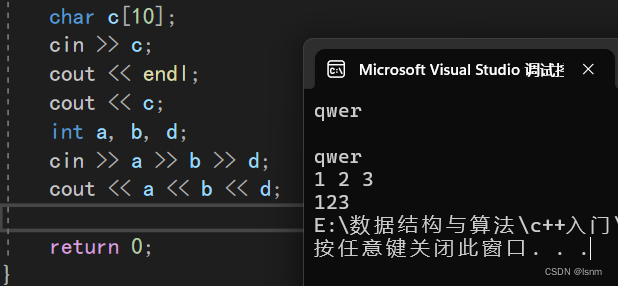
endl:end line
end line也就是换行
![]()
这样就一下换了两行。
再度总结三种用法:
c++将库中的name包含到了std中,若我们不适用语句using namespace std的话,就得:

如上,第一种,指定访问
 项目中不要,日常很方便
项目中不要,日常很方便
如上,第二种,完全展开
如上,第三种,指定展开。
( 第四种,: : add(a,b) )
6.头文件
c++在优化之后,新版的cpp头文件(如iostream)和新版的c语言头文件(cstdio)都不再带.h的后缀了,而cpp兼容c语言的语法,旧版的头文件也能使用,所以stdio.h等也能被拿来使用。

printf和cin cout能交错使用,要控制精度之类的可以直接使用printf,这样对于我们更熟悉更方便。
万能头文件:
#include <bits/stdc++.h>
(vs中不能识别,一般推荐在竞赛中使用,不建议在项目中使用)
7.缺省参数
缺省参数是 声明或定义函数时 为函数的 参数指定一个缺省值 。在调用该函数时,如果没有指定实 参则采用该形参的缺省值,否则使用指定的实参。如果声明和定义分离,则缺省参数应当在声明中给出。

 也就是默认参数
也就是默认参数
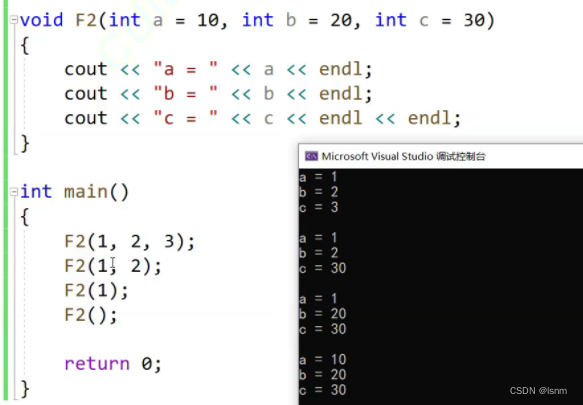
不能实现跳跃着传。
缺省类型分为全缺省和半缺省,上图中全为全缺省。
还可以半缺省,但是只能 从右往左缺省(右边有值,左边没有值)
目的是为了避免歧义
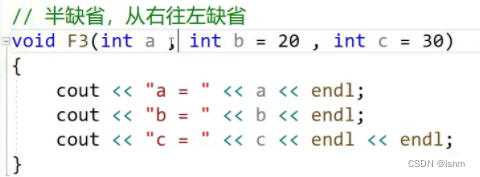
若左有右没有,传参数的时候就会有歧义
缺省一个至少传一个,但是可以传两个到三个。如上图,传一个就作为a的值,传两个就作为a和b的值。
半缺省可用于官方指导值
为什么缺省参数要在声明中给:
否则,如果缺省参数在声明和定义中同时给,用谁的?
8.函数重载
如果有一个场景需要我们交换各种类型的变量,c语言只能多写几次相同意义不同参数类型的函数。

c语言中不允许同名函数,这样的情况就不太方便。而cpp的函数重载功能,更能帮助我们实现泛型编程
同一作用域的函数重载 (函数重载也只针对同一作用域):
函数重载表示相同名字的函数可以同时使用
(非同作用域不算函数重载)
名字可以相同,形参列表,也就是 参数个数 或 类型 或 类型顺序 中任意一项不相同即可
(但是相同名字的函数看似工作原理很像,也很冗余,这一部分会在之后的函数模版中去处理)

这样是不行的。函数重载要求的是形参类型,而不是形参的名字。
(编译器会自动匹配参数类型)
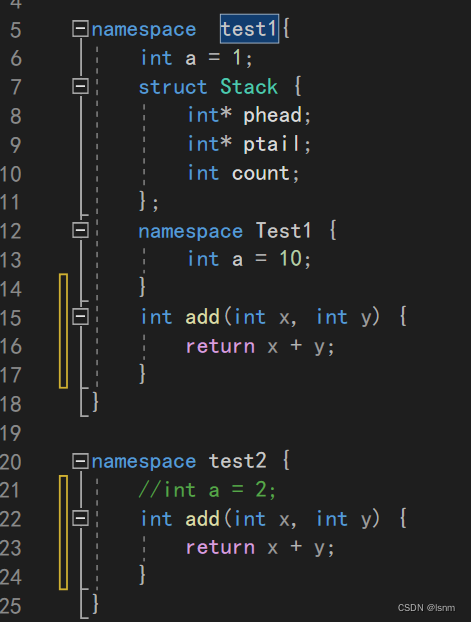
test1和test2中的add不构成函数重载,因为不在同一作用域中,不存在函数重载的概念。
若把两个命名空间展开之后,两者依然不构成重载。展开并不代表把两个函数放在全局,两个add的作用域依然各是各的。只要不调用add就不会报错
若调用,此时发生的错误叫作:调用歧义
返回值是否相同与是否重构无关,只关注参数是否类型、顺序、个数等。
因为,对于只调用函数而不接受返回值的使用情况,到底该调用有返回值的还是没有返回值呢?
int add(int x,int y){
return x+y;
}
void add(int x,int y){
return x+y;
}
//如果两函数在不同作用域会有调用歧义,相同作用域则会因为形参的类型、顺序、个数都一样而不发生重载
//从而报错如果有隐式转换 如以下代码:调用f( ' a ' , ' b ' );
也会有调用歧义。
void f(int a, char b)
{
cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{
cout << "f(char b, int a)" << endl;
}因此,只有返回值不同或者在隐式类型转换之后有调用歧义的,都不可取。
还有一些调用歧义的类型:
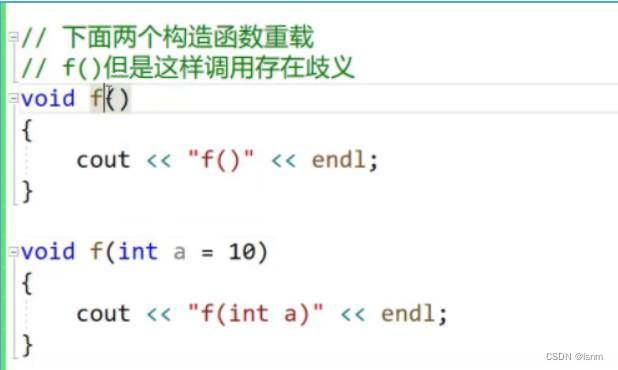
调用的时候,若像下文一样使用:
f();就会出现调用歧义。
存在调用歧义时候,若修改代码而不再调用该函数(比如直接注释),那么就都不会报错。
9.为什么cpp支持函数重载(面试题)?
为什么c语言不支持,cpp支持?
这与函数名修饰规则有关:
在函数执行的汇编代码中,每次遇到一个函数都需要执行call语句。call的本质是call函数的地址,函数中有一堆要执行的指令,函数的地址本质是第一句指令的地址
对于一个只有声明没有定义的函数,有声明,所以不会报错,但是只有声明,没有函数执行各步骤的有效地址。所以在链接之前并找不到函数实质性的地址,声明与调用相匹配,就能够调用了
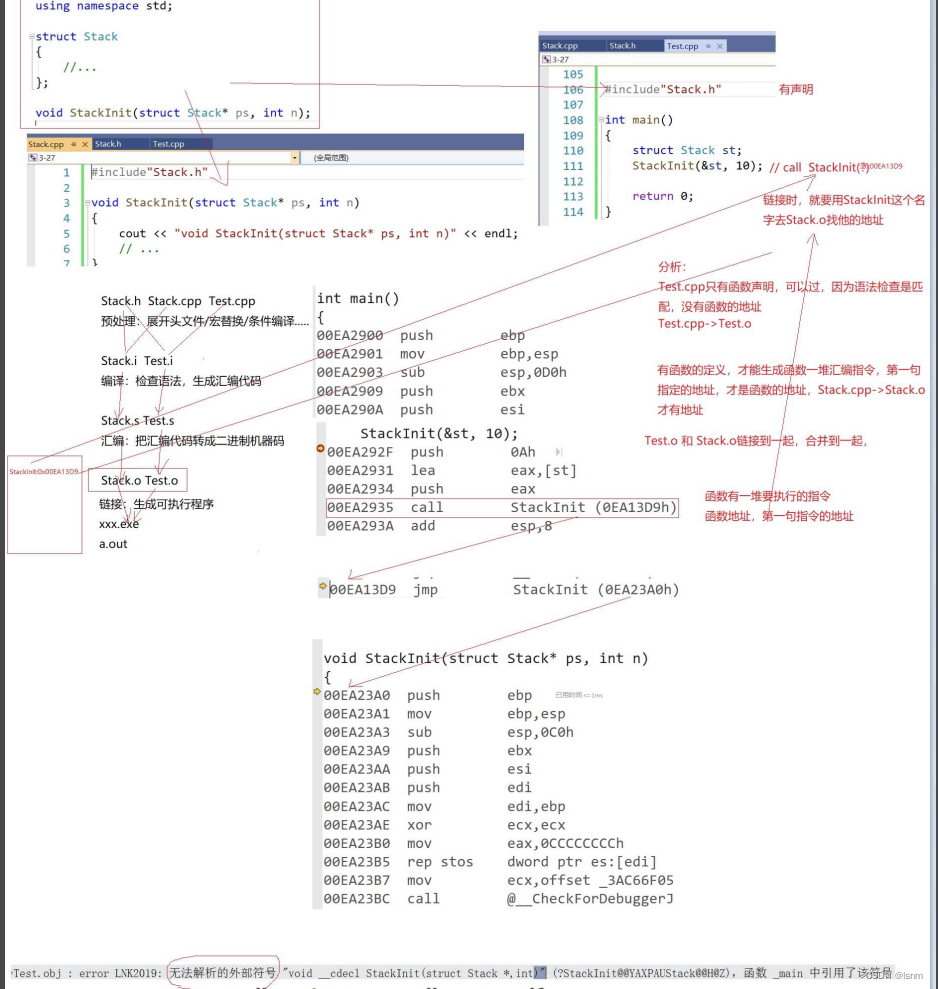 c会在查找时直接用函数名去查找;
c会在查找时直接用函数名去查找;
而cpp会在查找时用修饰过的函数名去查找,不同的编译器修饰办法不一样,但是都能区分参数之间的不同。
修饰的规则会与参数的类型、顺序有关系

(这是vs的命名规则)
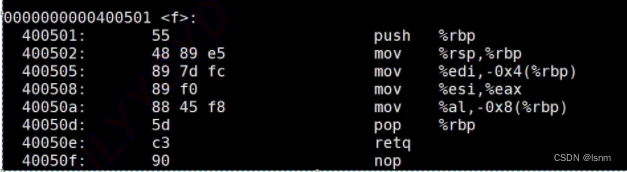
而c语言不修饰,若函数名是一样的,寻找有效地址时就会发生歧义,就不支持重载。















 965
965











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









