







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的健身动作识别计数系统
设计思路
一、课题背景与意义
健身活动在现代社会中越来越受到重视,人们更加注重身体健康和运动锻炼。为了辅助健身者在训练过程中进行正确、高效的动作执行,基于深度学习的健身动作识别计数系统应运而生。该系统利用深度学习技术结合计算机视觉技术,能够自动识别和计数健身动作,为健身者提供实时的反馈和指导。这对于提高健身训练的效果和安全性具有重要意义。
二、算法理论原理
2.1 卷积神经网络
卷积神经网络(CNN)是一种广泛应用于图像识别、计算机视觉和自然语言处理等领域的深度学习模型。它的设计灵感来源于生物学上视觉皮层的工作原理,通过局部感知野、权值共享和池化等特性,能够有效地提取图像和序列数据中的特征。卷积神经网络能够自动学习和提取图像中的特征,如边缘、纹理和形状等,并通过层层堆叠的结构实现对更高级别的语义信息的理解。卷积神经网络主要由卷积层、池化层和全连接层等组成。
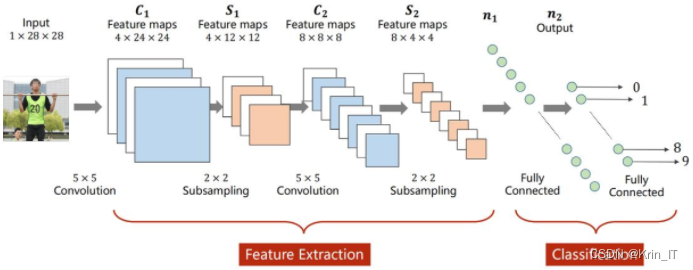
在卷积层中,通过应用一组卷积核(或滤波器)对输入数据进行卷积操作,从而提取输入中的局部特征。卷积操作通过滑动窗口的方式,在不同的位置对输入数据进行局部感知,从而实现对不同位置的特征提取。卷积操作具有权值共享的特性,即同一个卷积核在不同位置提取的特征是共享权值的,这样可以大大减少模型的参数量,提高模型的训练效率。
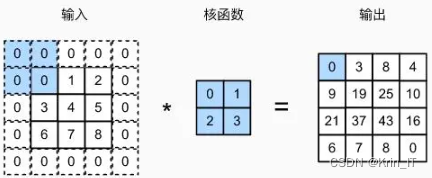
池化层用于对卷积层提取的特征进行下采样和压缩,以减少模型的参数量和计算复杂度。常见的池化操作包括最大池化(Max Pooling)和平均池化(Average Pooling),它们通过在局部区域内取最大值或平均值来保留主要特征信息。

全连接层通常在卷积层和输出层之间,用于将卷积层提取的特征映射到具体的类别或标签。全连接层中的每个节点都与上一层的所有节点相连接,通过学习权值参数来实现特征的组合和分类。
2.2 网络模型
多空间特征融合时空图卷积神经网络模型是一种用于动作识别任务的改进模型,通过采用远空间分区策略和注意力机制,能够提高动作识别的精度。该模型首先将输入的时空数据划分为多个远空间区域,每个区域包含一组相关的时空特征。这样的划分有助于捕捉不同空间位置的特征差异,并避免信息的混杂。每个远空间区域都经过独立的卷积神经网络处理,提取局部特征。
在多空间特征融合阶段,通过引入注意力机制,模型能够自动学习并加权不同远空间区域的特征重要性。注意力机制利用注意力权重来调节每个区域的贡献,使得模型更加关注对动作识别有重要影响的区域。这样能够提高网络的表达能力和泛化性能。模型使用时空图卷积操作来处理融合后的多空间特征。时空图卷积神经网络能够充分利用时序信息和空间结构,通过在时序和空间维度上进行卷积操作来提取更丰富的特征表示。这样可以捕捉到动作的时序演变和空间关系,进一步提高动作识别的准确性。通过全连接层和softmax激活函数,将时空图卷积神经网络输出的特征映射到具体的动作类别,实现动作识别任务。
多空间特征融合时空图卷积神经网络模型的优点在于它能够充分利用多个远空间区域的特征信息,并通过注意力机制进行自适应特征融合,从而提高了动作识别的精度。该模型在动作识别领域具有良好的应用潜力,可以在视频监控、运动分析和虚拟现实等领域发挥重要作用。
三、检测的实现
3.1 数据集
由于网络上没有现有的合适数据集,我决定进行网络爬取,收集了大量的健身动作相关数据,并制作了一个全新的数据集。这个数据集包含了各种健身动作的视频和图像,通过网络爬取和数据整理,我能够获得多样化、全面的健身动作数据,包括不同角度、不同光照条件下的动作示例。通过使用数据增强技术,包括图像旋转、缩放、裁剪等操作,我生成了更多的样本,使数据集更具丰富性。此外,还利用健身动作的标注信息,对动作进行计数,并加入噪声提供更真实的数据情况。
3.2 实验环境搭建
实验基于64位Windows 10操作系统,在硬件配置上采用了Intel Xeon E5-1680 v4处理器、32GB内存和NVIDIA TITAN XP 12GB显卡。软件环境方面,使用了CUDA 10.1和cudnn 7.6.5作为图形处理加速器,编程语言为Python 3.8,深度学习框架为PyTorch 1.7.1。
3.3 实验及结果分析
健身动作计数方法包括以下步骤:
- 健身视频采集:使用矿用监控摄像头获取健身运动视频数据。
- 人体骨架数据获取:采用高精度人体姿态估计算法(如Alphapose算法)检测工人的身体关键点信息,获取单帧图像上的人体骨架和连续图像序列上的骨架序列数据。这样做是为了减少图像背景对动作识别的干扰。
- 动作识别:在基于改进时空图卷积神经网络的模型(如MST-GCN模型)的基础上,采用远空间分区策略和注意力机制设计了MST-GCN模型。该模型能够有效识别骨架序列上的动作类型,并提高打钻动作的识别精度。
- 动作开始位置捕获:使用支持向量机(SVM)算法辨识用户的健身运动姿势。如果姿势判断成功,则保存150帧人体骨架序列,并输入MST-GCN模型进行识别。
- 健身运动数量计算:为了减少模型出错的概率,将健身运动视频手动分割成引体向上视频和向下视频,并分别在每种视频上只识别对应的动作。在向下视频中,MST-GCN模型每次从引体向上姿势出现的位置预测一次动作。如果结果为引体向上动作,则引体向上数量加1,并在一定时间间隔后再重新识别。

相关代码示例:
import torch
from model import MST_GCN # 导入MST-GCN模型
# 定义计数函数
def count_actions(video_frames):
# 加载训练好的MST-GCN模型
model = MST_GCN()
model.load_state_dict(torch.load('mst_gcn_model.pth'))
model.eval()
# 将视频帧转换为张量并进行预处理
frames_tensor = preprocess_frames(video_frames)
# 将张量输入到模型进行推理
with torch.no_grad():
output = model(frames_tensor)
# 对输出进行后处理,根据具体任务进行动作计数
action_count = process_output(output)
return action_count
# 预处理视频帧,根据模型要求进行数据转换和标准化
def preprocess_frames(frames):
# 根据模型要求进行数据预处理,例如将帧调整为指定大小、标准化等操作
# ...
# 将预处理后的帧转换为张量并添加批次维度
frames_tensor = torch.tensor(frames).unsqueeze(0)
return frames_tensor
# 处理模型输出,根据具体任务进行动作计数
def process_output(output):
# 根据模型输出进行后处理,例如根据阈值进行动作分类和计数
# ...
# 返回动作计数结果
action_count = 0 # 这里只是一个示例,需要根据具体任务进行计数
return action_count
# 加载视频帧数据
video_frames = load_video_frames('video_frames.npy')
# 调用计数函数进行动作计数
count = count_actions(video_frames)
# 输出动作计数结果
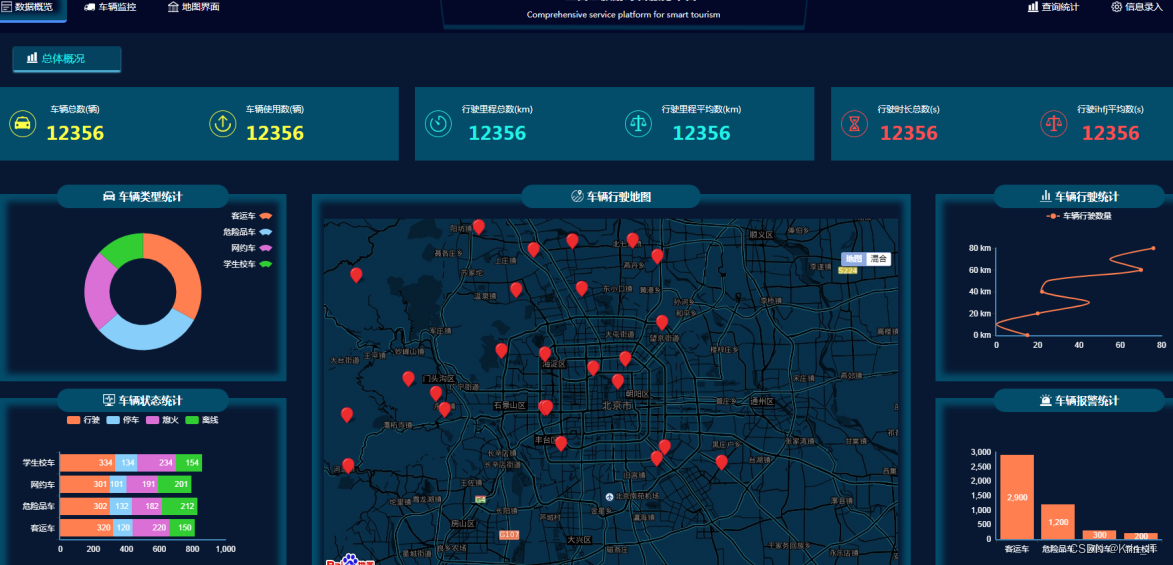
print("动作计数:", count)实现效果图样例:



创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









