







 本文介绍了基于深度学习的天气与空气质量预测系统的选题背景、理论原理,包括深度学习、循环神经网络、注意力机制的应用。详细描述了数据集的获取、实验环境的搭建,以及模型的实现和结果分析,展示了如何通过LSTM等模型进行预测并评估预测精度。
本文介绍了基于深度学习的天气与空气质量预测系统的选题背景、理论原理,包括深度学习、循环神经网络、注意力机制的应用。详细描述了数据集的获取、实验环境的搭建,以及模型的实现和结果分析,展示了如何通过LSTM等模型进行预测并评估预测精度。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的天气与空气质量预测系统
设计思路
一、课题背景与意义
天气和空气质量对人们的日常生活和健康具有重要影响,因此准确预测天气和空气质量成为了一个关键的任务。传统的天气和空气质量预测方法依赖于物理模型和统计方法,存在预测准确性和实时性的限制。天气与空气质量预测系统通过对大量天气和空气质量数据的分析和学习,可以实现准确、实时的预测,为人们提供更可靠的天气和空气质量信息,帮助人们做出更好的决策,提高生活质量和健康水平。
二、算法理论原理
2.1 深度学习
人工神经网络包括前馈神经网络和后馈神经网络。前馈和后馈神经网络存在着明显的不同,其差异具体表现为神经网络的模型结构以及信息传递的权值更新方式。前馈神经网络和后馈神经网络在结构和信息传递的权值更新方式上存在明显的差异。前馈神经网络的模型结构是单向的,每一层的神经元只接收上一层神经元的输出作为输入。在前馈神经网络的训练过程中,输入和输出通过迭代和计算逐渐减小误差,直到误差满足可接受范围,网络停止训练。如果误差不满足可接受范围,神经网络会继续对连接权重进行迭代更新调整。
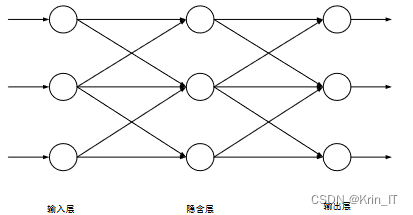
后馈神经网络是一种反馈动力学系统,神经元将自身的输出作为输入传递给其他神经元,使用非线性差分方程或微分方程描述计算过程。后馈神经网络包括Hopfield、CG和DHNN等模型。Hopfield网络是最早提出的单层反馈网络,也是最简单且广泛使用的后馈神经网络。它验证了给予后馈型神经网络演化方式,其运行状态最终能达到稳定的假设。改进后的Hopfield网络也可应用于快速寻优问题。Hopfield神经网络的神经元输入和输出为{0,1}或{-1,1},因此也被称为离散型Hopfield网络。
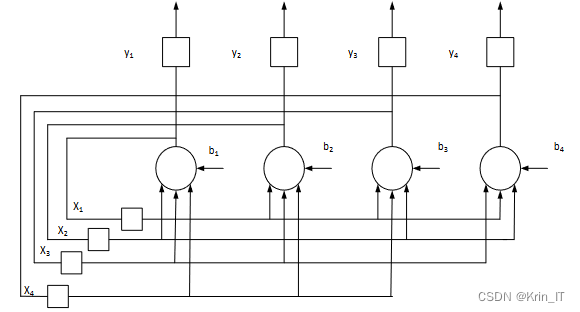
2.2 循环神经网络
循环神经网络是一种特殊的递归神经网络结构,在深度学习中被广泛应用。循环神经网络的节点按照链式方式连接在一起,并在输入序列数据的演进方向上进行递归操作。它特别适用于处理文本、时间序列和音视频等具有时序性的数据,并能够深入挖掘这些序列数据的时序和语义信息。
循环神经网络的结构包含一个循环环路,它将输出状态信息作为下一时刻的输入。这种循环连接使得循环神经网络能够记忆先前的输入信息,并在处理后续输入时将其考虑在内。这种记忆能力使得循环神经网络在处理序列数据时具有优势,能够捕捉到数据中的时序依赖关系。
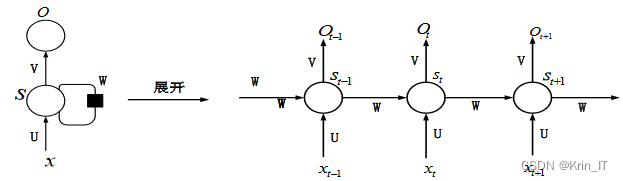
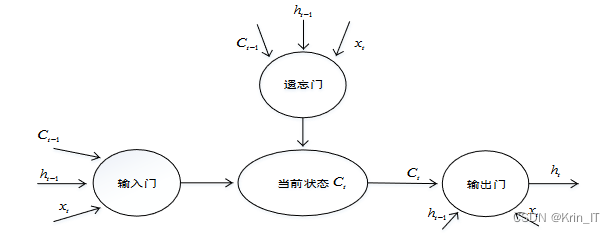
LSTM是一种特殊的循环神经网络,用于解决常规RNN中存在的长期依赖问题。通过引入输入门、遗忘门和输出门的机制,LSTM能够选择性地传递、记忆和输出信息,从而更好地捕捉长序列数据的依赖关系。这使得LSTM在处理顺序数据时表现出色,并具有广泛的应用潜力。
2.3 注意力机制
引入注意力机制可以使模型更关注输入特征中更重要的部分,并将有限的信息处理资源分配给这些部分,从而提高模型的表达能力。其次,注意力机制一般可以分为基于项的注意力和基于位置的注意力,它们的输入形式存在差异。基于项的注意力机制的输入是具有确定信息的输入项序列,或者是经过预处理生成的包含明确输入项的序列(如向量、矩阵或特征图)。而基于位置的注意力机制适用于单独的特征图输入,其中需要人为指定要重点关注的目标部分的位置。总之,注意力机制通过对重要部分的关注和资源分配,提升了模型的表达能力,并根据输入形式的不同,可以选择不同类型的注意力机制。
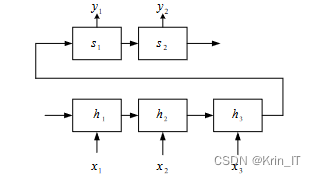
三、检测的实现
3.1 数据集
由于网络上没有现有的合适的天气和空气质量数据集,通过互联网收集了大量包含天气信息和空气质量指数的数据,以扩充数据集的多样性和覆盖范围。通过数据收集,我们能够获得真实、准确的天气和空气质量数据,为基于深度学习的天气与空气质量预测系统的研究提供可靠的数据基础。
3.2 实验环境搭建
实验环境使用Windows操作系统,并利用Python作为主要的编程语言进行算法和模型的实现。使用PyTorch作为深度学习框架,构建和训练神经网络模型。借助Pandas等库,完成数据的加载、处理和转换。这样的实验环境提供了一个方便和高效的平台,用于开发和测试算法系统。
3.3 实验及结果分析
为了避免训练过程受到输入值大小的影响,研究中对所有属性数据进行了归一化处理,将其转换到相同的范围内,即[0, 1]。这样做可以避免训练结果受到较大输入值的影响而产生偏差。针对神经网络模型,通过训练这些模型并进行下一小时的温度和降雨预测。根据实验结果,绘制了各模型在100次迭代时的平均总误差(Ltotle)图。通过对图表的分析,发现各模型的总误差逐渐减少。LSTM和BP模型在训练过程中快速拟合完毕,而DRNN和ALSTM的总误差稳定地下降。
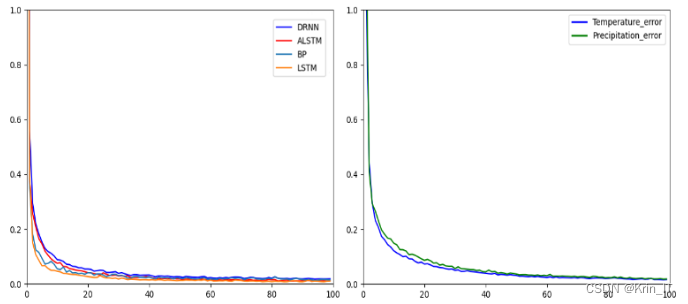
为了验证模型的预测效果,使用测试数据集对模型进行了验证,测试数据按照时间顺序排列。在实验中,采用平均绝对误差(MAE)作为衡量偏差程度的评价指标,它能更好地反映预测值与真实值之间的误差情况,并使用1-MAE的结果作为模型预测精度的评价指标。
相关代码示例:
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Input
# 定义模型输入
inputs = Input(shape=(input_dim,))
# 定义隐藏层
hidden1 = Dense(64, activation='relu')(inputs)
hidden2 = Dense(64, activation='relu')(hidden1)
# 定义输出层
output1 = Dense(1, activation='linear', name='output1')(hidden2)
output2 = Dense(1, activation='sigmoid', name='output2')(hidden2)
# 构建模型
model = Model(inputs=inputs, outputs=[output1, output2])
# 编译模型
model.compile(optimizer='adam', loss={'output1': 'mean_squared_error', 'output2': 'binary_crossentropy'})
# 训练模型
model.fit(x_train, {'output1': y_train1, 'output2': y_train2}, epochs=10, batch_size=32)
# 对测试数据进行预测
predictions = model.predict(x_test)
# 获取输出结果
output1_pred = predictions[0]
output2_pred = predictions[1]实现效果图样例:




创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

















 285
285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









