






-

-
什么是pandas环境依赖?
-
pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
-
什么是Scikit-learn?
-
Scikit-learn(以前称为scikits.learn,也称为sklearn)是针对Python 编程语言的免费软件机器学习库[1]。它具有各种分类,回归和聚类算法,包括支持向量机,随机森林,梯度提升,k均值和DBSCAN,并且旨在与Python数值科学库NumPy和SciPy联合使用。
-
什么是rdkit?
-
RDKit是一款基于Python的开源化学信息学工具包,其核心为分子模型和算法。通过RDKit,用户可以轻松地进行分子的构建、修改、查询以及分子特征的提取等操作。此外,RDKit还提供了丰富的接口和工具,方便用户进行大规模的化合物数据处理和分析。
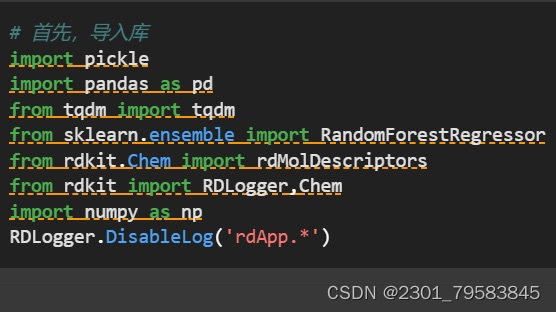
- 导入pickle库,用于对象的序列化(将Python对象转换为字节流)和反序列化(从字节流转换为Python对象)。在机器学习中常用于保存和加载训练好的模型或数据。
- tqdm是一个快速、可扩展的进度条工具,用于在循环或迭代过程中显示进度条,提升用户体验。
- 从sklearn库中的ensemble模块导入随机森林回归器。随机森林是一种集成学习方法,适用于回归和分类问题。
- rdMolDescriptors包含了一些分子描述符的计算方法。
- RDLogger用于控制rdkit的日志记录,通常在运行时可以禁用某些日志以减少输出。Chem模块提供了化学信息学的核心功能,包括分子的表示和操作。
- 导入numpy库,并给其起了一个别名np。numpy是Python中用于科学计算的核心库,提供了高效的多维数组对象和数学函数。
- RDLogger.DisableLog('rdApp.*'): 禁用rdkit的日志记录器(Logger),通常用于屏蔽一些不必要的输出信息,以提高程序的运行效率和简洁性。
-
什么是随机森林?
-
随机森林是集成学习中的Bagging(Bootstrap Aggregation)方法的一种实现,是由很多决策树作为基础估计器集成的一个同质估计器。
各决策树之间没有关联,在用随机森林进行分类时,每个样本会被森林中的每一颗决策树进行判断和分类,每个决策树会得到一个分类结果,哪一个分类的结果最多(众数),就是随机森林的最终结果。 -
学习参考:随机森林 Random Forest
-
暂时还是不懂得怎么调节参数或者换模型来提高分数。但运行了几次之后分数有提高















 1504
1504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









