






什么是文生图?
文生图是一种利用人工智能技术生成图片的方法,它能够根据用户输入的文字描述来生成相应的图像。
什么是SD系列基础模型?
stable diffusion(稳定扩散)(简称SD)正在席卷世界,让任何人都可以使用各种风格的人工智能技术生成图像。Stable Diffusion(稳定扩散)指的是一种文本到图像的人工神经网络模型,能够理解用户输入的描述并生成相应的图像。这种模型基于大量的数据进行训练,其作用是学习如何将输入的文本描述转化为图像内容。
特点: 自由度高,界面直观,流程定制性高,结果的可重用性,经济的显存占用
稳定扩散模型允许您控制图像生成的风格。使用专门针对真实图像训练的模型将产生逼真的结果,例如照片真实感的肖像。另一方面,使用经过水彩插图训练的模型会给你一个看起来像是用同一风格画的图像。
SD模型的分类?
【1】大模型/底模型-属于基础模型也叫预调模型
SD能够绘图的基础模型。安装完SD软件后,必须搭配基础模型才能使用。不同的基础模型,其画风和擅长的领域会有侧重。
(尾缀ckpt、safetensors。safetendersor文件被认为更安全)
【2】Lora模型-属于微调模型
在大模型得基础上用于满足一种特定的风格,或指定的人物特征属性。
(尾缀多了pt)
【3】VAE美化模型
全名Variational autoenconder,中文叫变分自编码器。作用是:滤镜+微调。
详见SD模型介绍
提示词promts
分为正向和负向,一般描述:主体、细节、修饰词、艺术风格、艺术家。
Lora模型详谈
LoRA模型,全称Low-Rank Adaptation of Large Language Models,是一种用于微调大型语言模型的低秩适应技术。它最初应用于NLP领域,特别是用于微调GPT-3等模型。LoRA通过仅训练低秩矩阵,然后将这些参数注入到原始模型中,从而实现对模型的微调。这种方法不仅减少了计算需求,而且使得训练资源比直接训练原始模型要小得多,因此非常适合在资源有限的环境中使用。
LoRA 是如何工作的?
LoRA 对Stable Diffusion模型中最关键的部分进行微小改动:交叉注意力层。这是模型中图像和提示相遇的部分。研究人员发现,仅微调模型的这一部分就足以实现良好的训练效果。交叉注意力层在下方的Stable Diffusion模型架构中以黄色部分表示。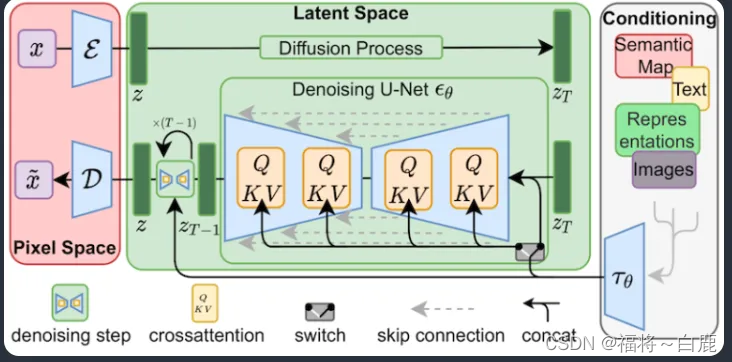
交叉注意力层的权重被排列成矩阵形式。矩阵就像 Excel 电子表格中按列和行排列的一系列数字。LoRA 模型通过将其权重添加到这些矩阵中来对模型进行微调。
什么是ComfyUI?
ComfyUI,一款基于节点工作流稳定扩散算法的图形界面。通过将稳定扩散的流程巧妙分解成各个节点,成功实现了工作流的精准定制和可靠复现。
ComfyUI工作流指的是一种基于节点式的工作流程,它通过将稳定扩散的流程分解成多个节点,实现了更加精细化的流程定制和更高的结果可重用性。这种工作流的设计使得用户能够通过直观的节点式界面设计和执行复杂的稳定扩散工作流程,无需编写任何代码。ComfyUI工作流不仅提高了工作效率,还使得复杂任务的处理变得更加直观和高效。在图像生成方面,ComfyUI相较于传统的WebUI具有更快的速度和更经济的显存占用,特别是在生成大图片时,不会导致显存爆满,而是通过切块运算来避免图片碎裂的问题。
什么是参考图控制?
Control Net是一种在生成图像任务中用于提高生成质量的神经网络技术。它通常被用于生成对抗网络(GANs)中,用于更精细地控制图像生成的过程,例如指定图像中对象的位置、大小、姿态等属性。
在传统的GANs中,生成器(Generator)从随机噪声中生成图像,而判别器(Discriminator)则负责区分生成的图像和真实图像。虽然这样的模型可以生成高质量的图像,但很难精确控制生成图像的特定方面。Control Net通过添加额外的条件输入,如边缘图、语义分割图或关键点位置,来引导生成过程,从而使得生成器在生成图像时能够遵循这些额外的条件。
参考图控制分类
openpose姿势控制:输入姿势图片
canny精准绘制:输入线稿
hed绘制:输入线稿、可获取渐变色条
深度图midas:输入深度图(黑白)
颜色color控制:输入参考图和颜色控制

















 278
278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









