









注意:下面介绍了多种详细的分片算法和对应配置,内容有点多。希望通过代码亲身实践,噢力给
全部demo案例 GitHub 地址:
https://github.com/chengxy-nds/Springboot-Notebook/tree/master/shardingsphere101/shardingsphere-algorithms
分片策略
ShardingSphere提供了standard、complex、hint、inline、none分片策略。
标准分片策略(standard)适用于具有单一分片键的标准分片场景。该策略支持精确分片,即在SQL中包含=、in操作符,以及范围分片,包括BETWEEN AND、>、<、>=、<=等范围操作符。
该策略下有两个属性,分片字段shardingColumn和分片算法名shardingAlgorithmName。
spring:
shardingsphere:
rules:
sharding:
tables:
t_order: # 逻辑表名称
# 数据节点:数据库.分片表
actual-data-nodes: db$->{0..1}.t_order_${1..10}
# 分库策略
databaseStrategy: # 分库策略
standard: # 用于单分片键的标准分片场景
shardingColumn: order_id # 分片列名称
shardingAlgorithmName: # 分片算法名称
tableStrategy: # 分表策略,同分库策略 行表达式分片策略(inline)适用于具有单一分片键的简单分片场景,支持SQL语句中=和in操作符。
它的配置相当简洁,该分片策略支持在配置属性algorithm-expression中书写Groovy表达式,用来定义对分片健的运算逻辑,无需单独定义分片算法了。
spring:
shardingsphere:
rules:
sharding:
tables:
t_order: # 逻辑表名称
# 数据节点:数据库.分片表
actual-data-nodes: db$->{0..1}.t_order_${1..10}
# 分库策略
databaseStrategy: # 分库策略
inline: # 行表达式类型分片策略
algorithm-expression: db$->{order_id % 2} Groovy表达式
tableStrategy: # 分表策略,同分库策略 复合分片策略(complex)适用于多个分片键的复杂分片场景,属性shardingColumns中多个分片健以逗号分隔。支持 SQL 语句中有>、>=、<=、<、=、IN 和 BETWEEN AND 等操作符。
比如:我们希望通过user_id和order_id等多个字段共同运算得出数据路由到具体哪个分片中,就可以应用该策略。
spring:
shardingsphere:
rules:
sharding:
tables:
t_order: # 逻辑表名称
# 数据节点:数据库.分片表
actual-data-nodes: db$->{0..1}.t_order_${1..10}
# 分库策略
databaseStrategy: # 分库策略
complex: # 用于多分片键的复合分片场景
shardingColumns: order_id,user_id # 分片列名称,多个列以逗号分隔
shardingAlgorithmName: # 分片算法名称
tableStrategy: # 分表策略,同分库策略 Hint强制分片策略相比于其他几种分片策略稍有不同,该策略无需配置分片健,由外部指定分库和分表的信息,可以让SQL在指定的分库、分表中执行。
使用场景:
-
分片字段不存在SQL和数据库表结构中,而存在于外部业务逻辑。
-
强制在指定数据库进行某些数据操作。
比如,我们希望用user_id做分片健进行路由订单数据,但是t_order表中也没user_id这个字段啊,这时可以通过Hint API手动指定分片库、表等信息,强制让数据插入指定的位置。
spring:
shardingsphere:
rules:
sharding:
tables:
t_order: # 逻辑表名称
# 数据节点:数据库.分片表
actual-data-nodes: db$->{0..1}.t_order_${1..10}
# 分库策略
databaseStrategy: # 分库策略
hint: # Hint 分片策略
shardingAlgorithmName: # 分片算法名称
tableStrategy: # 分表策略,同分库策略 不分片策略比较好理解,设置了不分片策略,那么对逻辑表的所有操作将会执行全库表路由。
spring:
shardingsphere:
rules:
sharding:
tables:
t_order: # 逻辑表名称
# 数据节点:数据库.分片表
actual-data-nodes: db$->{0..1}.t_order_${1..10}
# 分库策略
databaseStrategy: # 分库策略
none: # 不分片
tableStrategy: # 分表策略,同分库策略 分片算法:
前面说过inline是直接指定了分片的表达式了
ShardingSphere 内置了多种分片算法,按照类型可以划分为自动分片算法、标准分片算法、复合分片算法和 Hint 分片算法,能够满足我们绝大多数业务场景的需求。 取模分片算法是内置的一种比较简单的算法,定义算法时类型MOD,表达式大致(分片健/数据库实例) % sharding-count,它只有一个 props 属性sharding-count代表分片表的数量。
这个 sharding-count 数量使用时有点小坑,比如db0和db1都有分片表t_order_1,那么实际上数量只能算一个。YML核心配置如下:
spring:
shardingsphere:
rules:
sharding:
# 自动分片表规则配置
auto-tables:
t_order:
actual-data-sources: db$->{0..1}
sharding-strategy:
standard:
sharding-column: order_date
sharding-algorithm-name: t_order_table_mod
# 分片算法定义
sharding-algorithms:
t_order_table_mod:
type: MOD # 取模分片算法
props:
# 指定分片数量
sharding-count: 6
tables:
t_order: # 逻辑表名称
actual-data-nodes: db$->{0..1}.t_order_${0..2}
# 分库策略
database-strategy:
....
# 分表策略
table-strategy:
standard:
sharding-column: order_id
sharding-algorithm-name: t_order_table_mod 基于分片容量的范围分片算法,依据数据容量来均匀分布到分片表中。
它适用于数据增长趋势相对均匀,按分片容量将数据均匀地分布到不同的分片表中,可以有效避免数据倾斜问题;由于数据已经被按照范围进行分片,支持频繁进行范围查询场景。
不仅如此,该算法支持动态的分片调整,可以根据实际业务数据的变化动态调整分片容量和范围,使得系统具备更好的扩展性和灵活性。
VOLUME_RANGE算法主要有三个属性: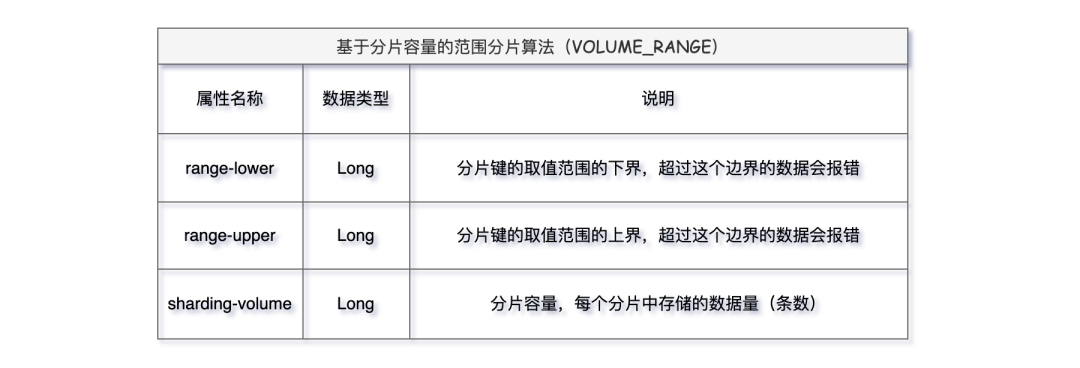
看完是不是一脸懵逼,上界下界都是什么含义,我们实际使用一下就清晰了。为t_order逻辑表设置VOLUME_RANGE分片算法,range-lower下界数为 2,range-upper上界数为 20,分量容量sharding-volume 10。
yml核心配置如下:
# 分片算法定义
spring:
shardingsphere:
rules:
sharding:
# 自动分片表规则配置
auto-tables:
t_order:
actual-data-sources: db$->{0..1}
sharding-strategy:
standard:
sharding-column: order_date
sharding-algorithm-name: t_order_table_volume_range
sharding-algorithms:
t_order_table_volume_range:
type: VOLUME_RANGE
props:
range-lower: 2 # 范围下界,超过边界的数据会报错
range-upper: 20 # 范围上界,超过边界的数据会报错
sharding-volume: 10 # 分片容量
tables:
t_order: # 逻辑表名称
actual-data-nodes: db$->{0..1}.t_order_${0..2}
# 分库策略
database-strategy:
....
# 分表策略
table-strategy:
standard:
sharding-column: order_id
sharding-algorithm-name: t_order_table_volume_range
这个配置的意思就是说,分片健t_order_id的值在界值 [range-lower,range-upper) 范围内,每个分片表最大存储 10 条数据;低于下界的值 [ 1,2 ) 数据分布到 t_order_0,在界值范围内的数据 [ 2,20 ) 遵循每满足 10 条依次放入 t_order_1、t_order_2;超出上界的数据[ 20,∞ ) 即便前边的分片表里未满 10条剩下的也全部放在 t_order_3。
基于分片边界的范围分片算法,和分片容量算法不同,这个算法根据数据的取值范围进行分片,特别适合按数值范围频繁查询的场景。该算法只有一个属性sharding-ranges为分片健值的范围区间。
比如,我们配置sharding-ranges=10,20,30,40,它的范围默认是从 0开始,范围区间前闭后开。配置算法以后执行建表语句,生成数据节点分布如:
db0-
|_t_order_0
|_t_order_2
|_t_order_4
db1-
|_t_order_1
|_t_order_3
那么它的数据分布应该如下:
[ 0,10 )数据分布到t_order_0,
[ 10,20 )数据分布到t_order_1,
[ 20,30 )数据分布到t_order_2,
[ 30,40 )数据分布到t_order_3,
[ 40,∞ )数据分布到t_order_4。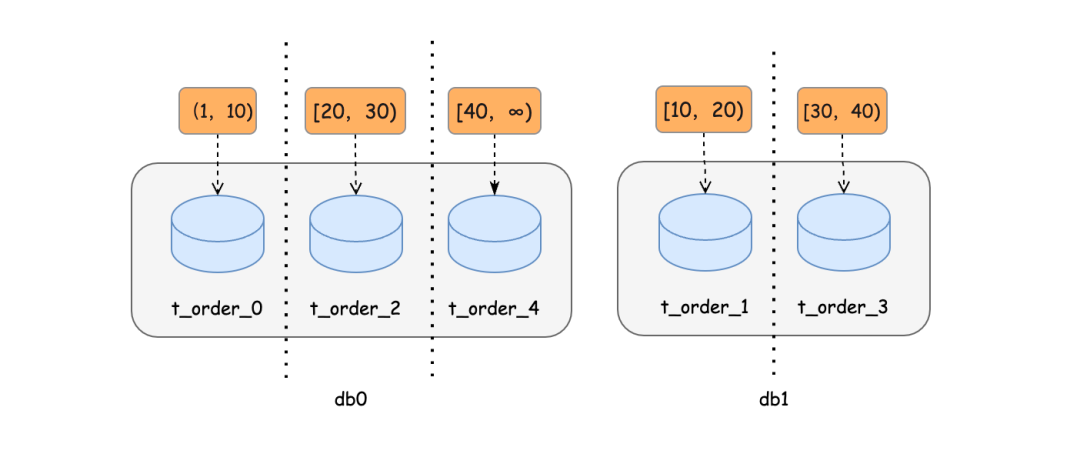
基于分片边界的范围分片算法
BOUNDARY_RANGE算法的YML核心配置如下:
spring:
shardingsphere:
rules:
sharding:
# 自动分片表规则配置
auto-tables:
t_order:
actual-data-sources: db$->{0..1}
sharding-strategy:
standard:
sharding-column: order_date
sharding-algorithm-name: t_order_table_boundary_range
sharding-algorithms:
# 基于分片边界的范围分片算法
t_order_table_boundary_range:
type: BOUNDARY_RANGE
props:
sharding-ranges: 10,20,30,40 # 分片的范围边界,多个范围边界以逗号分隔
tables:
t_order: # 逻辑表名称
actual-data-nodes: db$->{0..1}.t_order_${0..2}
# 分库策略
database-strategy:
....
# 分表策略
table-strategy:
standard:
sharding-column: order_id
sharding-algorithm-name: t_order_table_boundary_range 自动时间段分片算法,适用于以时间字段作为分片健的分片场景,和VOLUME_RANGE基于容量的分片算法用法有点类似,不同的是AUTO_INTERVAL依据时间段进行分片。主要有三个属性datetime-lower分片健值开始时间(下界)、datetime-upper分片健值结束时间(上界)、sharding-seconds单一分片表所能容纳的时间段。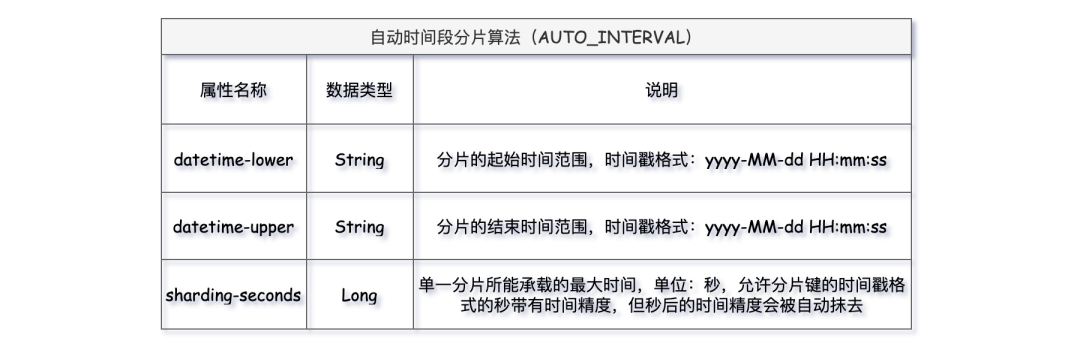
这里分片健已经从t_order_id替换成了order_date。现在属性 datetime-lower 设为 2023-01-01 00:00:00,datetime-upper 设为 2025-01-01 00:00:00,sharding-seconds为 31536000 秒(一年)。策略配置上有些改动,将分库和分表的算法全替换成AUTO_INTERVAL。
YML核心配置如下:
spring:
shardingsphere:
rules:
sharding:
# 自动分片表规则配置
auto-tables:
t_order:
actual-data-sources: db$->{0..1}
sharding-strategy:
standard:
sharding-column: order_date
sharding-algorithm-name: t_order_table_auto_interval
# 分片算法定义
sharding-algorithms:
# 自动时间段分片算法
t_order_table_auto_interval:
type: AUTO_INTERVAL
props:
datetime-lower: '2023-01-01 00:00:00' # 分片的起始时间范围,时间戳格式:yyyy-MM-dd HH:mm:ss
datetime-upper: '2025-01-01 00:00:00' # 分片的结束时间范围,时间戳格式:yyyy-MM-dd HH:mm:ss
sharding-seconds: 31536000 # 单一分片所能承载的最大时间,单位:秒,允许分片键的时间戳格式的秒带有时间精度,但秒后的时间精度会被自动抹去
tables:
# 逻辑表名称
t_order:
# 数据节点:数据库.分片表
actual-data-nodes: db$->{0..1}.t_order_${0..2}
# 分库策略
database-strategy:
standard:
sharding-column: order_date
sharding-algorithm-name: t_order_table_auto_interval
# 分表策略
# table-strategy:
# standard:
# sharding-column: order_date
# sharding-algorithm-name: t_order_table_auto_interval
只要你理解了上边 VOLUME_RANGE 算法的数据分布规则,那么这个算法也很容易明白,分片健值在界值范围内 [datetime-lower,datetime-upper) 遵循每满足 sharding-seconds 时间段的数据放入对应分片表,超出界值的数据上下顺延到其他分片中。
它的数据分布应该如下:
-
[ 2023-01-01 00:00:00,2024-01-01 00:00:00 )数据分布到 t_order_0, -
[ 2024-01-01 00:00:00,2025-01-01 00:00:00 )数据分布到 t_order_1, -
[ 2025-01-01 00:00:00,2026-01-01 00:00:00 )数据分布到 t_order_2。 -
[ 2026-01-01 00:00:00,∞ )数据分布到 t_order_3。
为了方便测试,手动执行插入不同日期的数据,按照上边配置的规则应该t_order_0会有一条 23 年的数据,t_order_1 中有两条 24 年的数据,t_order_2 中有两条 25 年的数据,t_order_3 中有两条 26、27 年的数据。
// 放入 t_order_0 分片表
INSERT INTO `t_order` VALUES (1, '2023-03-20 00:00:00', 1, '1', 1, 1.00);
// 放入 t_order_1 分片表
INSERT INTO `t_order` VALUES (2, '2024-03-20 00:00:00', 2, '2', 2,1.00);
INSERT INTO `t_order` VALUES (3, '2024-03-20 00:00:00', 3, '3', 3, 1.00);
// 放入 t_order_2 分片表
INSERT INTO `t_order` VALUES (4,'2025-03-20 00:00:00',4, '4', 4, 1.00);
INSERT INTO `t_order` VALUES (5,'2025-03-20 00:00:00',5, '5', 5, 1.00);
// 放入 t_order_3 分片表
INSERT INTO `t_order` VALUES (6,'2026-03-20 00:00:00',6, '6', 6, 1.00);
INSERT INTO `t_order` VALUES (7,'2027-03-20 11:19:58',7, '7', 7, 1.00); 行表达式分片算法,适用于比较简单的分片场景,利用Groovy表达式在算法属性内,直接书写分片逻辑,省却了配置和代码开发,只支持SQL语句中的 = 和 IN 的分片操作,只支持单分片键。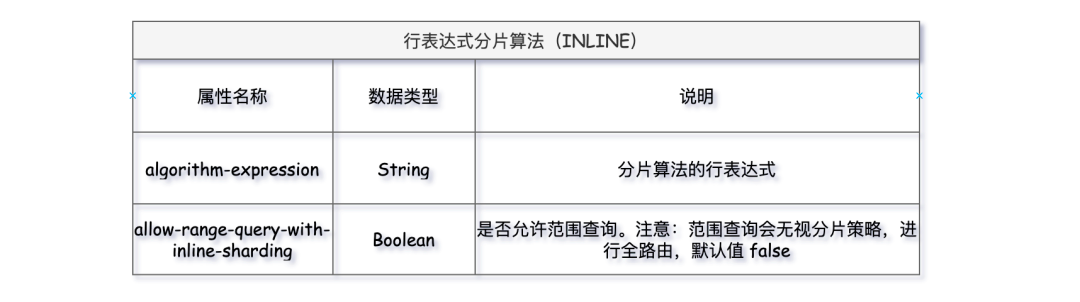
该算法有两属性:
-
algorithm-expression:编写Groovy的表达式,比如:t_order_$->{t_order_id % 3}表示根据分片健 t_order_id 取模获得 3 张 t_order 分片表 t_order_0 到 t_order_2。 -
allow-range-query-with-inline-sharding:由于该算法只支持含有 = 和 IN 操作符的SQL,一旦SQL使用了范围查询 >、< 等操作会报错。要想执行范围查询成功,该属性开启为true即可,一旦开启范围查询会无视分片策略,进行全库表路由查询,这个要慎重开启!
项目代码示例
动态管理 ShardingSphere 中的分表配置,支持运行时添加新表并更新分片规则。
✅ 类的主要作用总结:
-
初始化分表配置(
@PostConstruct):-
在容器启动时自动执行
initialize()方法,根据已有的空间(Space)动态生成所有实际表名,并更新 ShardingSphere 中的actual-data-nodes配置。
-
-
动态创建表(
createSpacePictureTable(Space space)):-
针对特定类型和等级的空间(如旗舰版团队空间),动态创建以空间 ID 命名的新表(例如
picture_123456),并更新分片配置。
-
-
与 ShardingSphere 深度集成:
-
通过
ContextManager操作 ShardingSphere 的运行时元数据,实现动态规则的更新和数据库的重载。
-
@Component
@Slf4j
public class DynamicShardingManager {
@Resource
private DataSource dataSource;
@Resource
private SpaceApplicationService spaceApplicationService;
private static final String LOGIC_TABLE_NAME = "picture";
private static final String DATABASE_NAME = "logic_db"; // 配置文件中的数据库名称
@PostConstruct
public void initialize() {
log.info("初始化动态分表配置...");
updateShardingTableNodes();
}
/**
* 获取所有动态表名,包括初始表 picture 和分表 picture_{spaceId}
*/
private Set<String> fetchAllPictureTableNames() {
// 为了测试方便,直接对所有团队空间分表(实际上线改为仅对旗舰版生效)
Set<Long> spaceIds = spaceApplicationService.lambdaQuery()
.eq(Space::getSpaceType, SpaceTypeEnum.TEAM.getValue())
.list()
.stream()
.map(Space::getId)
.collect(Collectors.toSet());
Set<String> tableNames = spaceIds.stream()
.map(spaceId -> LOGIC_TABLE_NAME + "_" + spaceId)
.collect(Collectors.toSet());
tableNames.add(LOGIC_TABLE_NAME); // 添加初始逻辑表
return tableNames;
}
/**
* 更新 ShardingSphere 的 actual-data-nodes 动态表名配置
*/
private void updateShardingTableNodes() {
Set<String> tableNames = fetchAllPictureTableNames();
// picture.picture_112321321,picture.picture_1123213123
String newActualDataNodes = tableNames.stream()
.map(tableName -> "picture." + tableName) // 确保前缀合法
.collect(Collectors.joining(","));
log.info("动态分表 actual-data-nodes 配置: {}", newActualDataNodes);
ContextManager contextManager = getContextManager();
ShardingSphereRuleMetaData ruleMetaData = contextManager.getMetaDataContexts()
.getMetaData()
.getDatabases()
.get(DATABASE_NAME)
.getRuleMetaData();
Optional<ShardingRule> shardingRule = ruleMetaData.findSingleRule(ShardingRule.class);
if (shardingRule.isPresent()) {
ShardingRuleConfiguration ruleConfig = (ShardingRuleConfiguration) shardingRule.get().getConfiguration();
List<ShardingTableRuleConfiguration> updatedRules = ruleConfig.getTables()
.stream()
.map(oldTableRule -> {
if (LOGIC_TABLE_NAME.equals(oldTableRule.getLogicTable())) {
ShardingTableRuleConfiguration newTableRuleConfig = new ShardingTableRuleConfiguration(LOGIC_TABLE_NAME, newActualDataNodes);
newTableRuleConfig.setDatabaseShardingStrategy(oldTableRule.getDatabaseShardingStrategy());
newTableRuleConfig.setTableShardingStrategy(oldTableRule.getTableShardingStrategy());
newTableRuleConfig.setKeyGenerateStrategy(oldTableRule.getKeyGenerateStrategy());
newTableRuleConfig.setAuditStrategy(oldTableRule.getAuditStrategy());
return newTableRuleConfig;
}
return oldTableRule;
})
.collect(Collectors.toList());
ruleConfig.setTables(updatedRules);
contextManager.alterRuleConfiguration(DATABASE_NAME, Collections.singleton(ruleConfig));
contextManager.reloadDatabase(DATABASE_NAME);
log.info("动态分表规则更新成功!");
} else {
log.error("未找到 ShardingSphere 的分片规则配置,动态分表更新失败。");
}
}
/**
* 动态创建空间图片分表
*
* @param space
*/
public void createSpacePictureTable(Space space) {
// 仅为旗舰版团队空间创建分表
if (space.getSpaceType() == SpaceTypeEnum.TEAM.getValue() && space.getSpaceLevel() == SpaceLevelEnum.FLAGSHIP.getValue()) {
Long spaceId = space.getId();
String tableName = LOGIC_TABLE_NAME + "_" + spaceId;
// 创建新表
String createTableSql = "CREATE TABLE " + tableName + " LIKE " + LOGIC_TABLE_NAME;
try {
SqlRunner.db().update(createTableSql);
// 更新分表
updateShardingTableNodes();
} catch (Exception e) {
e.printStackTrace();
log.error("创建图片空间分表失败,空间 id = {}", space.getId());
}
}
}
/**
* 获取 ShardingSphere ContextManager
*/
private ContextManager getContextManager() {
try (ShardingSphereConnection connection = dataSource.getConnection().unwrap(ShardingSphereConnection.class)) {
return connection.getContextManager();
} catch (SQLException e) {
throw new RuntimeException("获取 ShardingSphere ContextManager 失败", e);
}
}
}
经典分表算法:
-
yml配置sharding:
配置文件:
# 空间图片分表
shardingsphere:
datasource:
names: picture
picture:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/picture
username: root
password: 123456
rules:
sharding:
tables:
picture:
actual-data-nodes: picture.picture # 动态分表
table-strategy:
standard:
sharding-column: spaceId
sharding-algorithm-name: picture_sharding_algorithm # 使用自定义分片算法
sharding-algorithms:
picture_sharding_algorithm:
type: CLASS_BASED
props:
strategy: standard
algorithmClassName: package权限包名.PictureShardingAlgorithm
props:
sql-show: true
-
实现对应的分片类
// avaliableTargetNames表示实际的表明集合
// preciseShardingValue封装了分片键和逻辑表名等信息, 如:分片键值(如 spaceId)和逻辑表名(如 "picture")
// 这里的spaceId是分片路由的分片键的字段,配置文件使用的字段:
public class PictureShardingAlgorithm implements StandardShardingAlgorithm<Long> {
// 范围查询的分片算法,完成多个表间的范围查询
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Long> rangeShardingValue) {
Range<Long> range = rangeShardingValue.getValueRange();
Long lower = range.hasLowerBound() ? range.lowerEndpoint() : null;
Long upper = range.hasUpperBound() ? range.upperEndpoint() : null;
Set<String> result = new HashSet<>();
for (Long i = lower != null ? lower : 0;
upper != null ? i <= upper : i < Long.MAX_VALUE;
i++) {
long suffix = i % 10;
String tableName = "picture_" + suffix;
if (availableTargetNames.contains(tableName)) {
result.add(tableName);
}
// ⚠️ 为了防止死循环,设置一个合理范围限制
if (result.size() >= availableTargetNames.size()) {
break;
}
}
return result;
}
// 处理范围的查询
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
return new ArrayList<>();
}
// 下面是初始时完成对应的ymal文件
@Override
public Properties getProps() {
return null;
}
@Override
public void init(Properties properties) {
}
}

















 436
436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









