







文章目录
前言
神经网络是一种机器学习程序或模型,它以类似于人脑的方式做出决策,通过使用模仿生物神经元协同工作方式的过程来识别现象、权衡利弊并得出结论。
每个神经网络都由多个节点层或人工神经元组成 – 一个输入层、一个或多个隐藏层和一个输出层。每个节点都与其他节点相连,具有一个关联的权重和阈值。如果任何单个节点的输出高于指定的阈值,那么该节点将被激活,并将数据发送到网络的下一层。否则,不会将数据传递到网络的下一层。
神经网络依靠训练数据来学习并随着时间的推移提高其准确性。一旦对其准确性进行微调,它们就会成为计算机科学和人工智能领域的强大工具,使我们能够高速对数据进行分类和聚类。与人类专家的人工识别相比,人工智能进行语音识别或图像识别只需几分钟,而人工识别则需要几小时。神经网络最著名的例子之一就是 Google 的搜索算法。
神经网络有时被称为人工神经网络 (ANN) 或模拟神经网络 (SNN)。它们是机器学习的一个子集,是深度学习模型的核心。
摘至IBM:什么是神经网络?
1.如何快捷打开
在命令执行窗口输入nnstart。若要单独打开也可直接输入nftool等
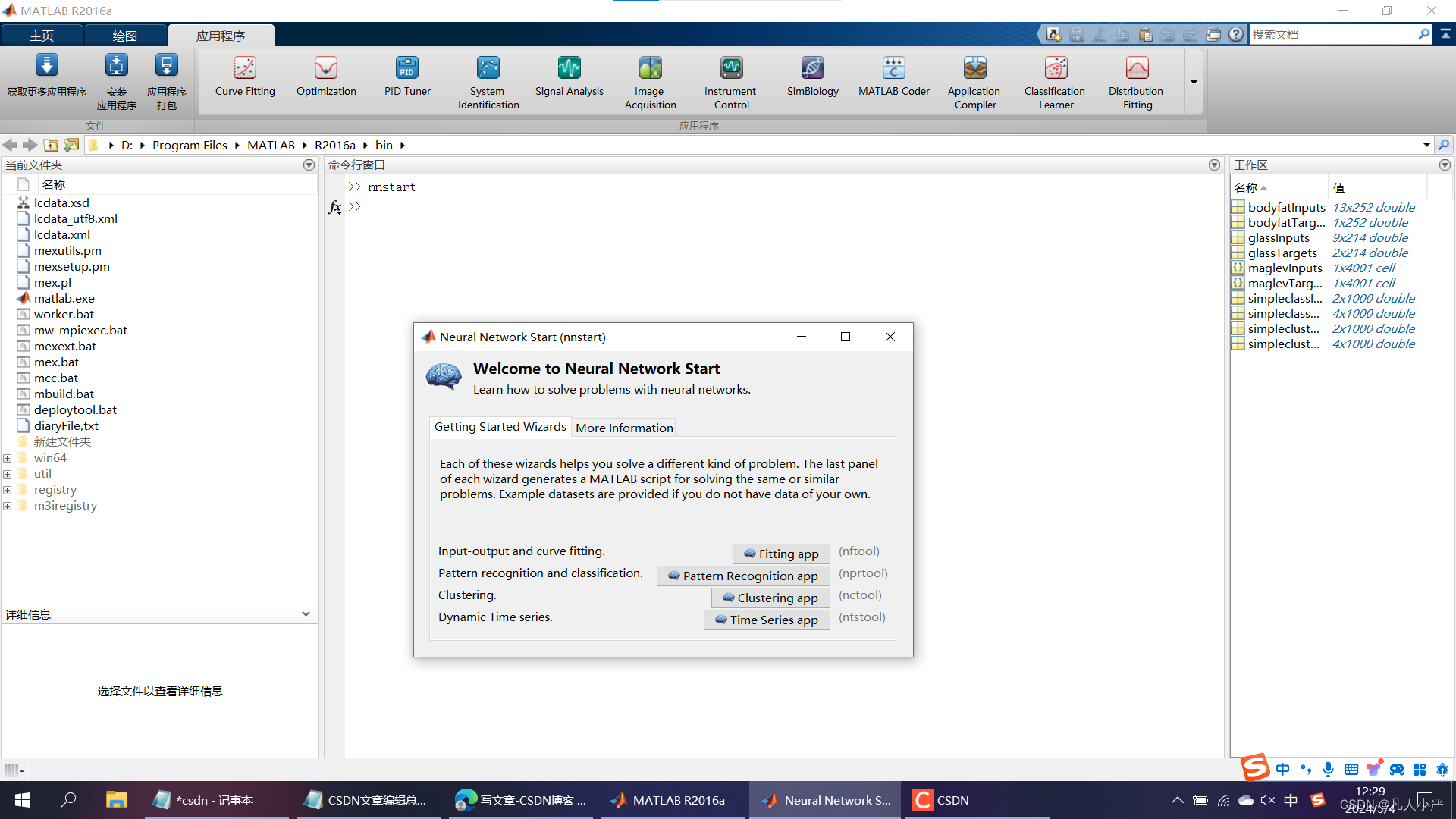
或打开应用程序
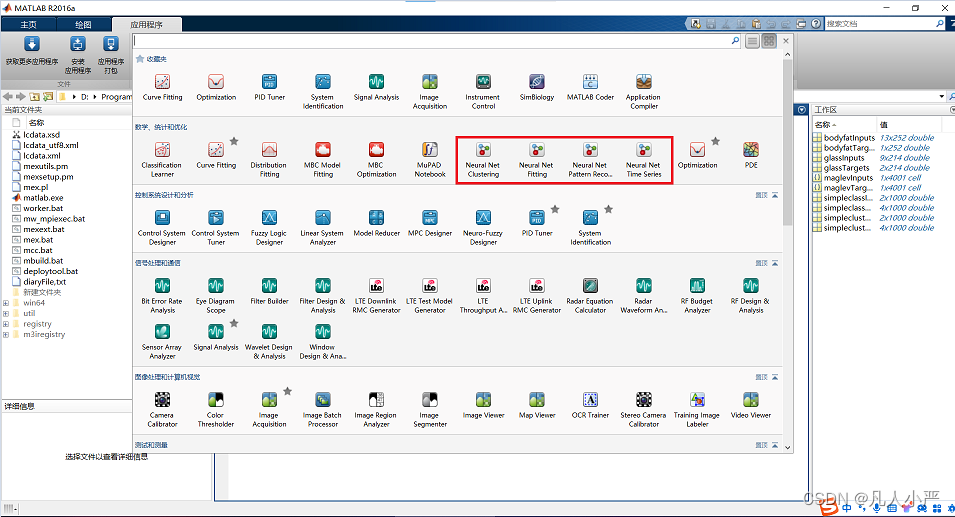
2.nnstart界面介绍
信息量很大,各种功能各取所需,下面主要从nftool介绍,其余类似。
神经网络设计手册和资源貌似无法访问
3.概念引入
泛化
这里不过多介绍了,下面博主介绍的非常棒了
隐藏层
这里介绍完隐藏层,后续对样本元素就好解释了
隐藏层
隐藏层w,b参数(文章开头的IBM摘取文章中也有涉及)
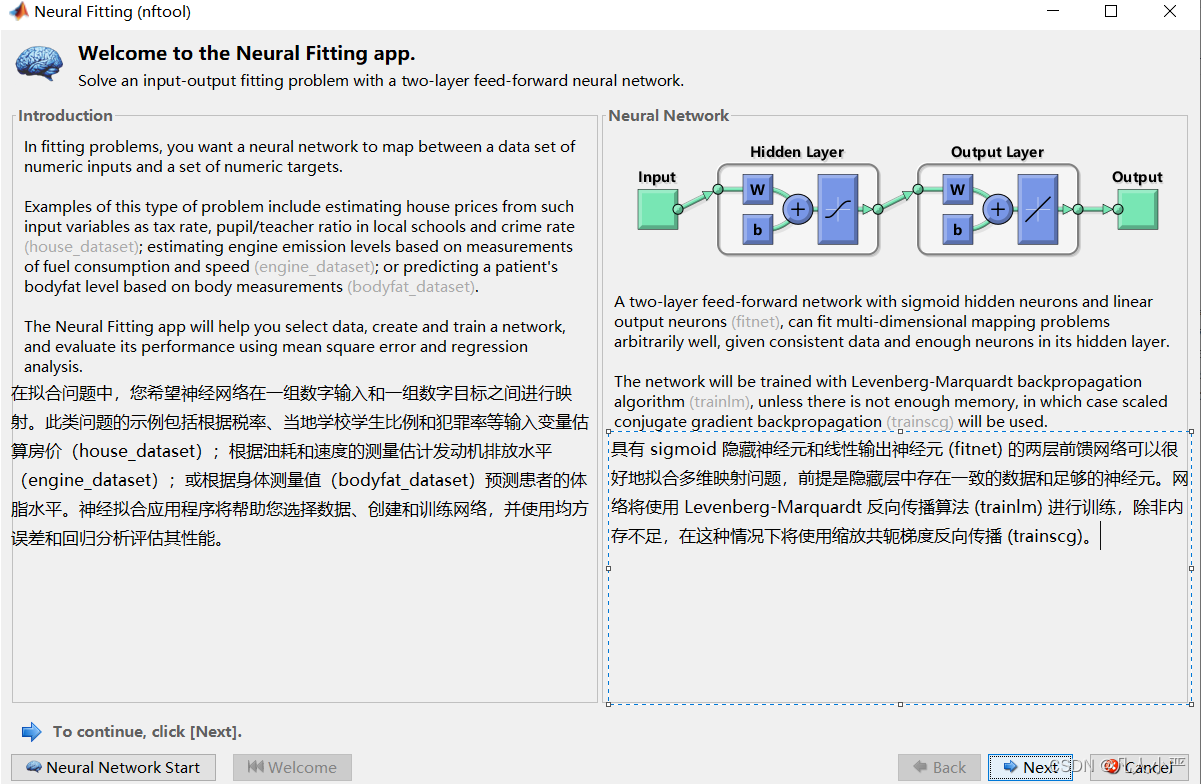
4.nftool介绍
在了解泛化与隐藏层后,官方介绍也就不难理解了。
所谓拟合,便是神经网络经过处理输入数据,抽象出来的数据模型。这个模型在经过均方误差和回归分析就可以测量泛化能力。
当模型提取出来后,你可再输入一组数据,模型便能迅速处理出结果。
5.数据选择、输入与介绍
这里你可以自行构造样本数据或确实有样本,将其利用Excel修改成矩阵排列形式再导入。(注意:当模型提取出来后,你再代入的样本也需满足相同的矩阵排列形式)
若无样本,我们便可下载MATLAB自带的样本。
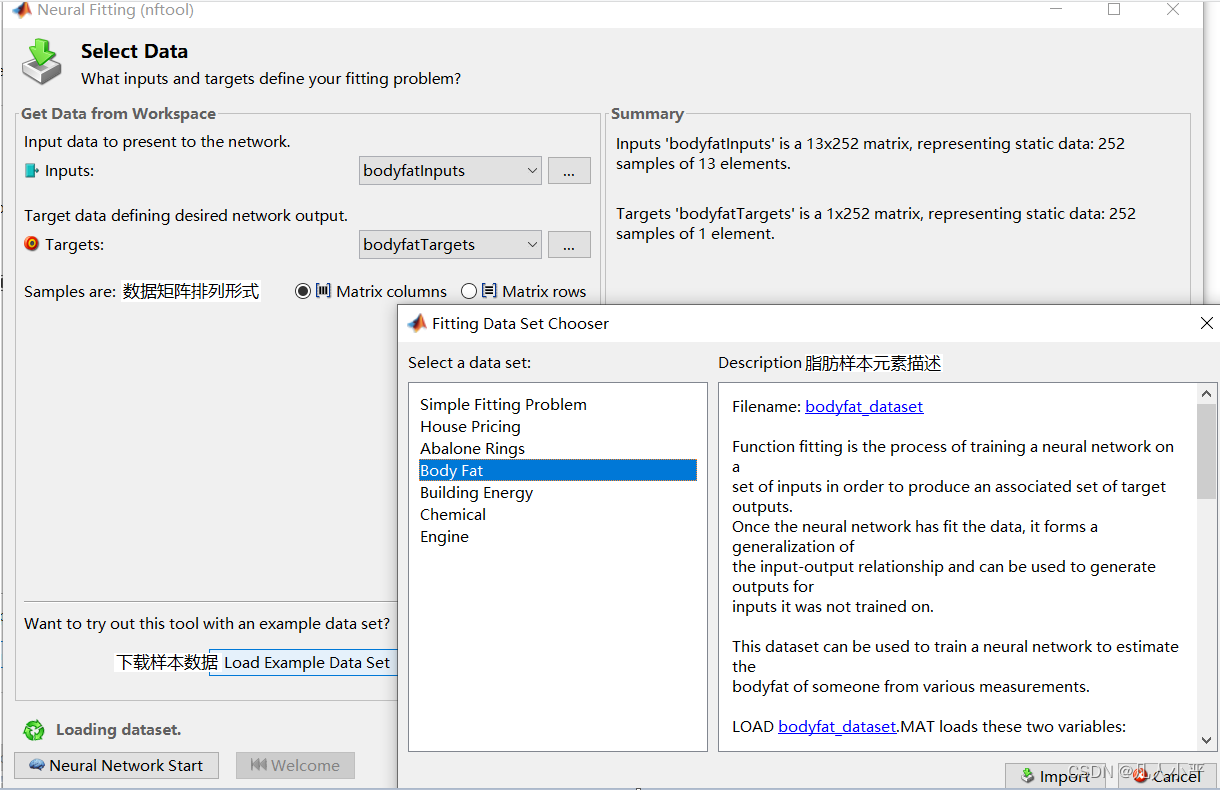
这里就以身体脂肪为例。(以下为其样本描述及其模型提取后的使用方法)
文件名:bodyfat_dataset 函数拟合是在一组输入上训练神经网络以产生一组相关的目标输出的过程。一旦神经网络拟合了数据,它就会形成输入输出关系的概括,并可用于为未经训练的输入生成输出。该数据集可用于训练神经网络,以根据各种测量值估计某人的体脂。 LOAD bodyfat_dataset.MAT 加载这两个变量: bodyfatInputs - 一个 13x252 矩阵,定义 252 人的 13 个属性。 1. 年龄(岁) 2. 体重(磅) 3. 身高(英寸) 4. 颈围(厘米) 5. 胸围(厘米) 6. 腹围 2 围(厘米) 7. 臀围(厘米) 8. 大腿周长(厘米) 9. 膝周长(厘米) 10. 脚踝周长(厘米) 11. 二头肌(伸展)周长(厘米) 12. 前臂周长(厘米) 13. 手腕周长(厘米) bodyfatTargets - 相关身体的 1x252 矩阵脂肪百分比,根据输入估算。 [X,T] = bodyfat_dataset 将输入和目标加载到您自己选择的变量中。有关神经拟合应用程序拟合的介绍,请单击第二个面板中的“加载示例数据集”并选择此数据集。以下是如何使用命令行中的数据设计一个具有 10 个隐藏神经元的拟合神经网络。请参阅 fitnet 了解更多详细信息。 [x,t] = bodyfat_dataset;净 = 健身网 (10);净=火车(净,x,t);视图(净) y = 净(x);另请参见 NFTOOL、FITNET、NNDATASETS。
这里13种样本数据便是隐藏层的分析对象。
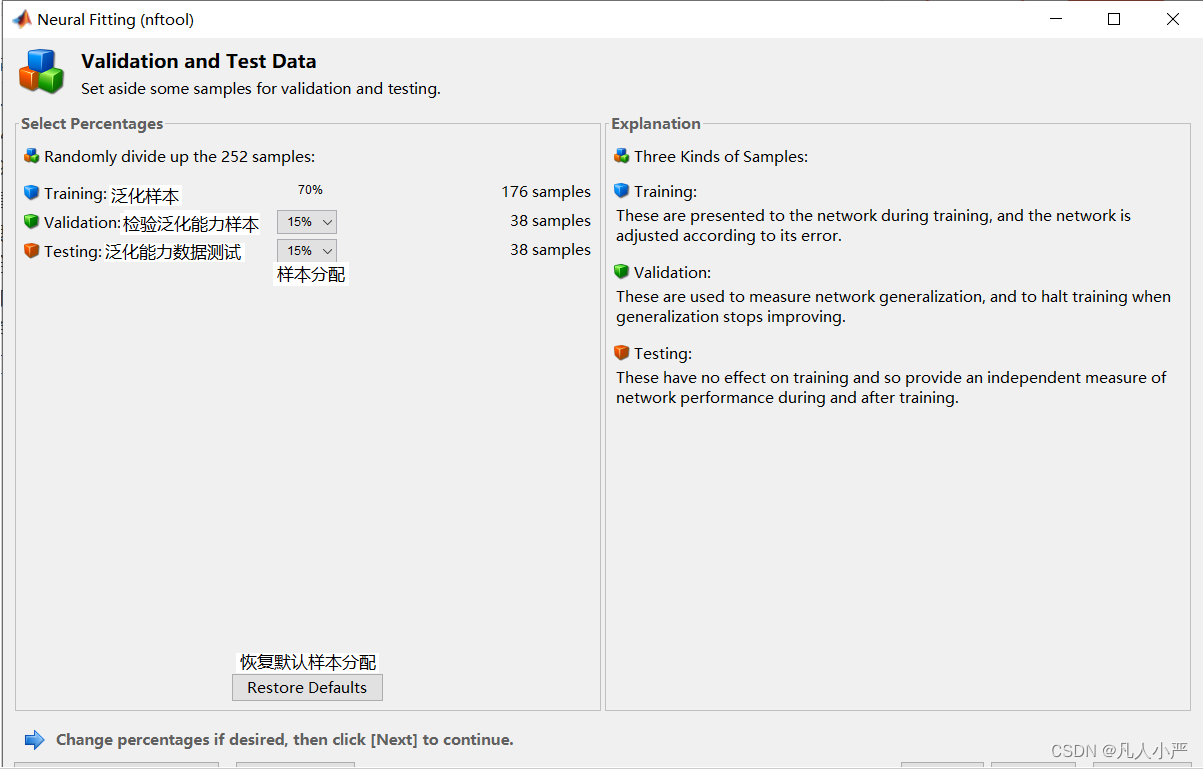
6.样本分配
这里的样本分配将直接影响模型的泛化能力以及可视化图的效果展示。
若想了解更多,请参照下方链接
样本分配介绍
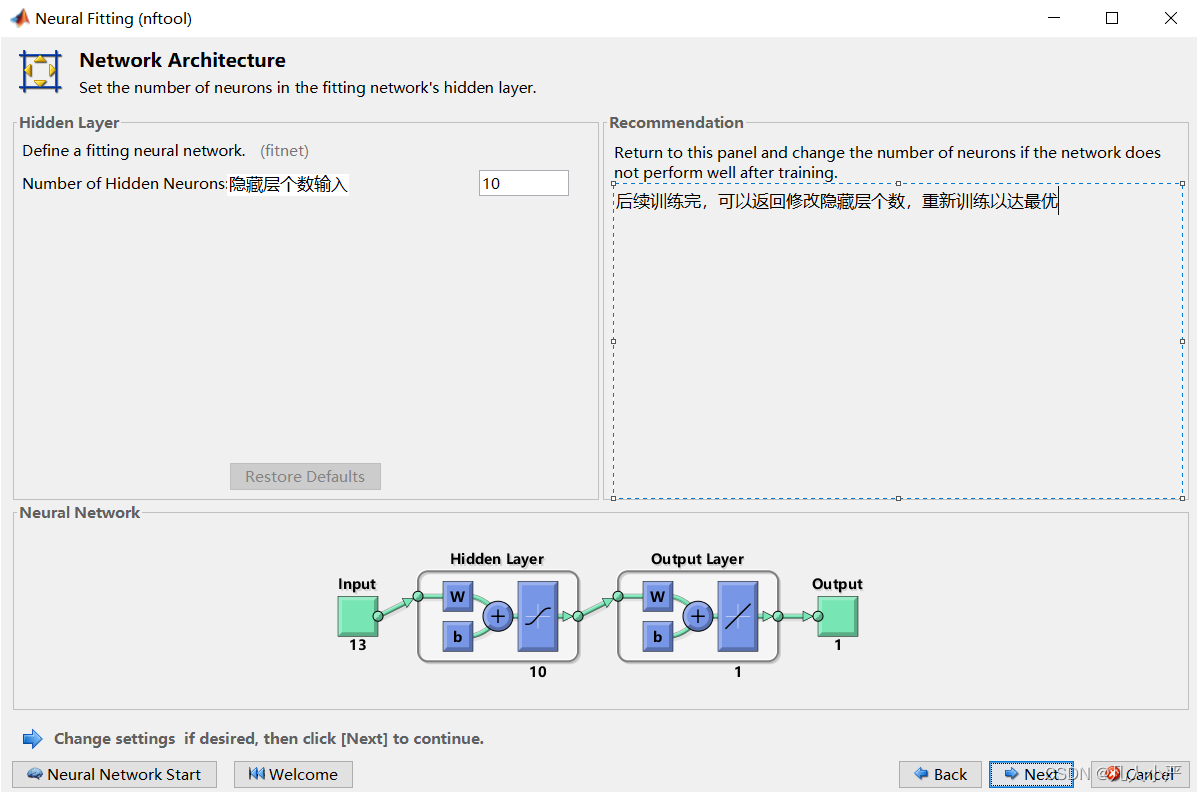
7.隐藏层分配个数
这里我们可以修改隐藏层,适当增大或缩小隐藏层个数,可以优化模型的泛化能力。但具体多少最优,这就需要不断修改调试了,非技术人员无法预测神经网络下一步如何泛化。
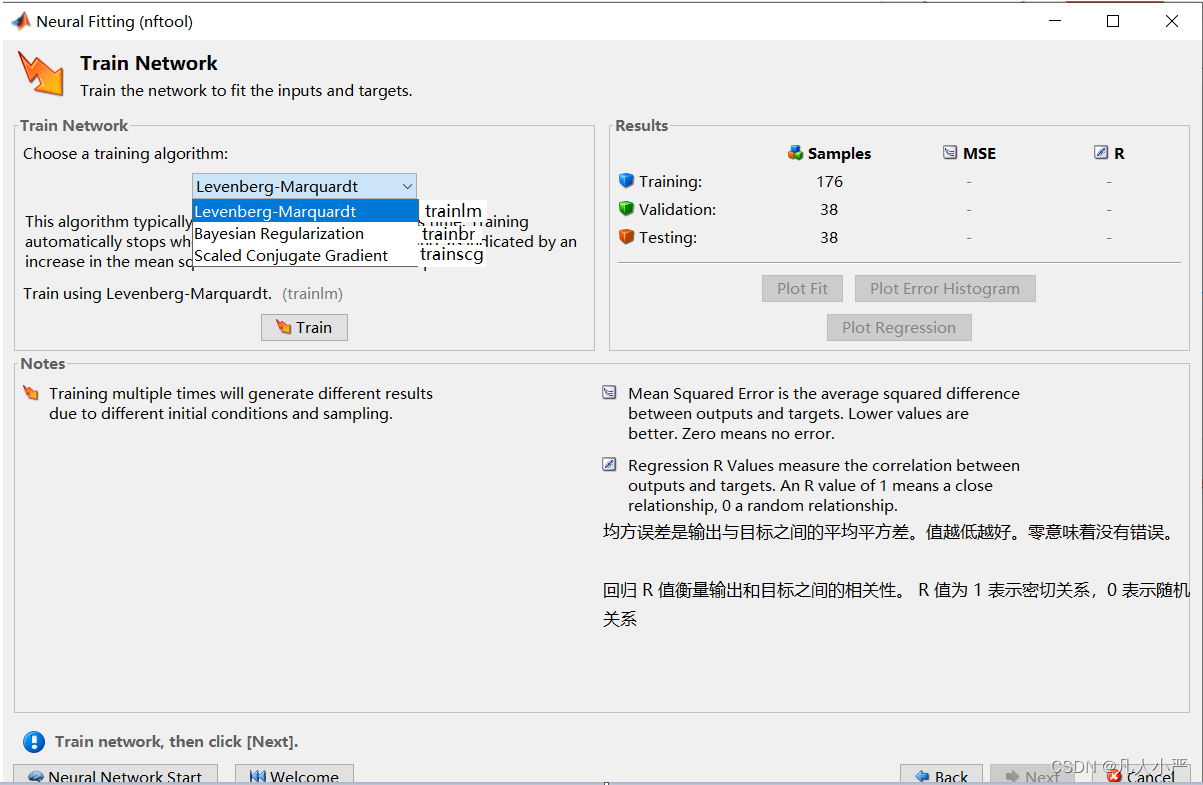
8.训练
这里涉及三种算法。
trainlm算法是Levenberg-Marquardt算法的缩写,集合了牛顿法和梯度下降法。一般情况下,在函数逼近问题上,对于包含多达几百个权重的网络,莱文贝格-马夸特算法具有最快的收敛。如果需要非常准确的训练,这种优势尤其明显。然而,随着网络中权重数量的增加,trainlm 的优势会减小。此外,trainlm 在模式识别问题上的表现相对较差。trainlm 的存储要求高于被测的其他算法。Levenberg-Marquardt 高斯-牛顿迭代法
trainbr算法是Bayesian Regularization算法的缩写,基于莱文贝格-马夸特优化更新权重和偏置值,并确定正确的组合以产生泛化能力强的网络。此算法通常需要更多时间,但对于困难、小型或嘈杂的数据集,可以减小过拟合的风险,提高模型的泛化能力。根据自适应权重最小化(正则化)停止训练。
trainscg算法是Scaled Conjugate Gradient算法缩写,基于量化共轭梯度法更新权重和偏置值,具有普遍性。对于大型问题,推荐使用量化共轭梯度,因为它使用的梯度计算比莱文贝格-马夸特或贝叶斯正则化使用的雅可比矩阵计算更节省内存。
9.拟合分析
根据误差分析与回归曲线确定此模型是否拟合,若不拟合,可重新训练。
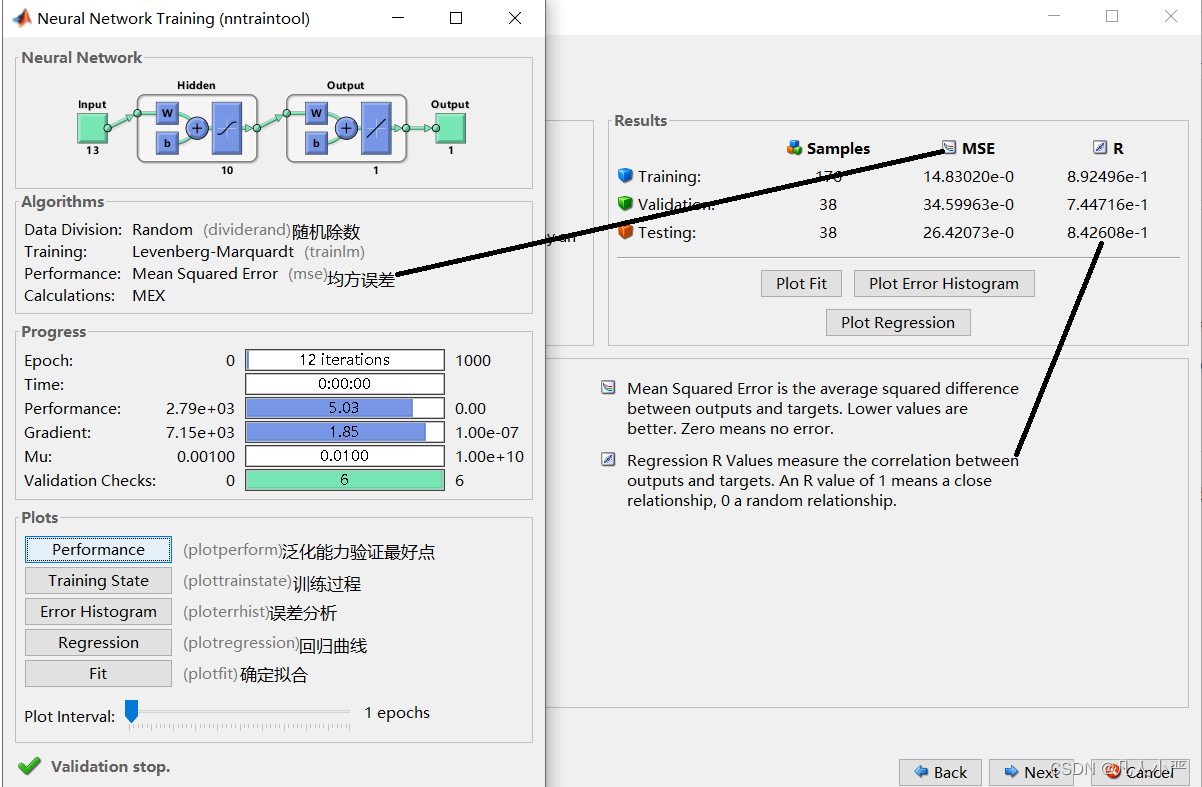
10.重新拟合
如果拟合效果不好就可以采取以下三种方法。
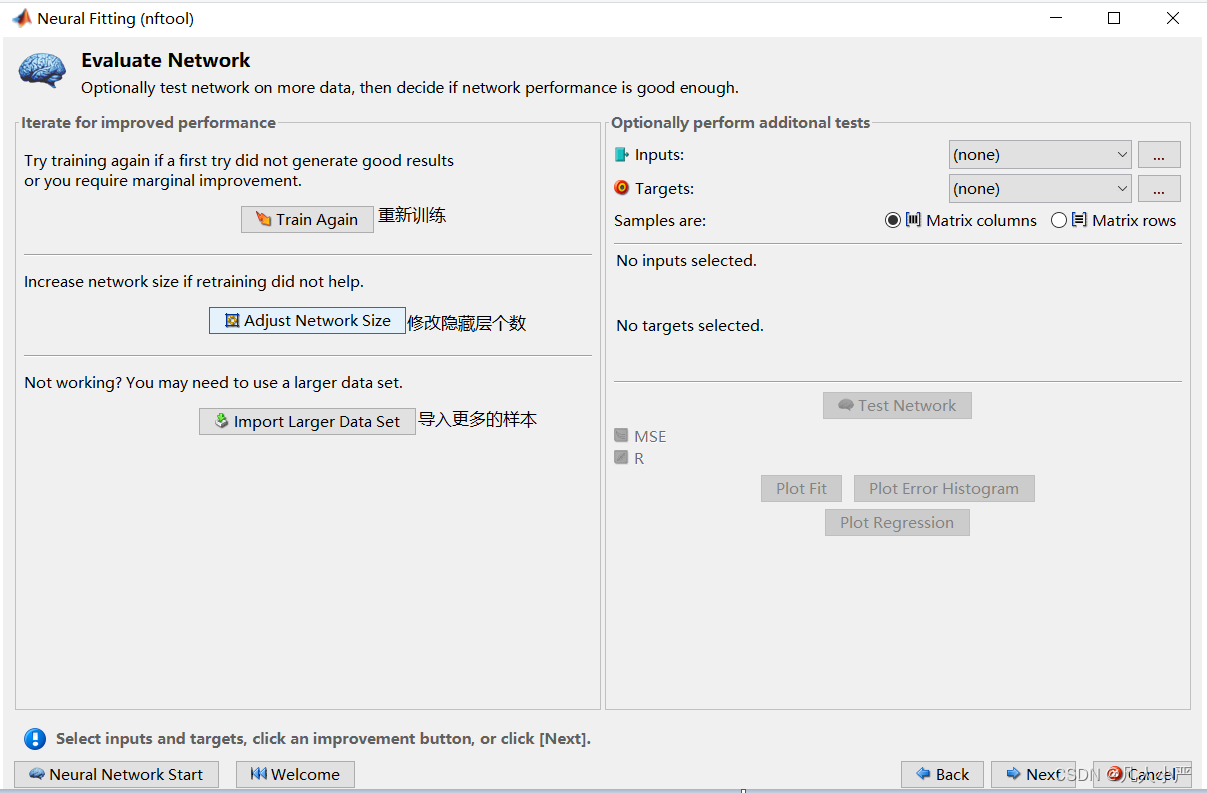
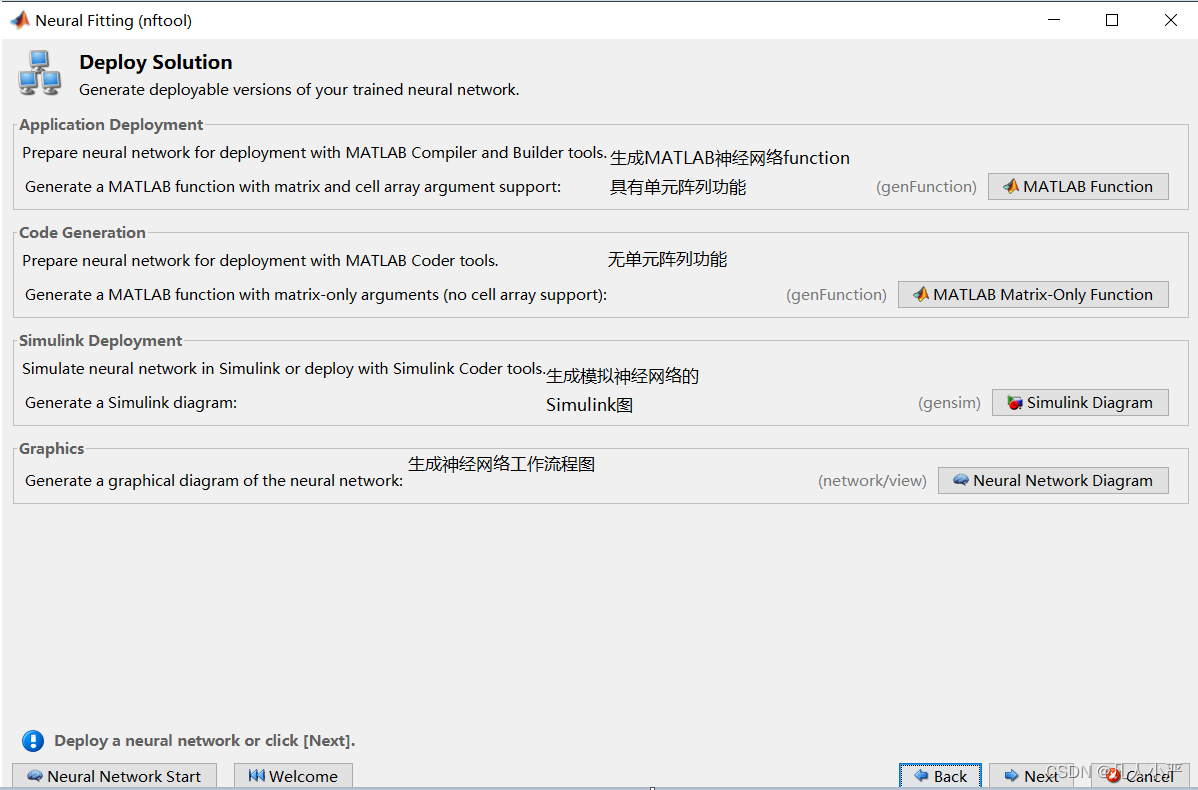
11.辅助生成代码图文
这里生成的图文主要是帮助我们理解神经网络是如何工作的。
12.生成脚本
生成脚本后保存,你就可以根据脚本内容重复神经网络拟合过程了。
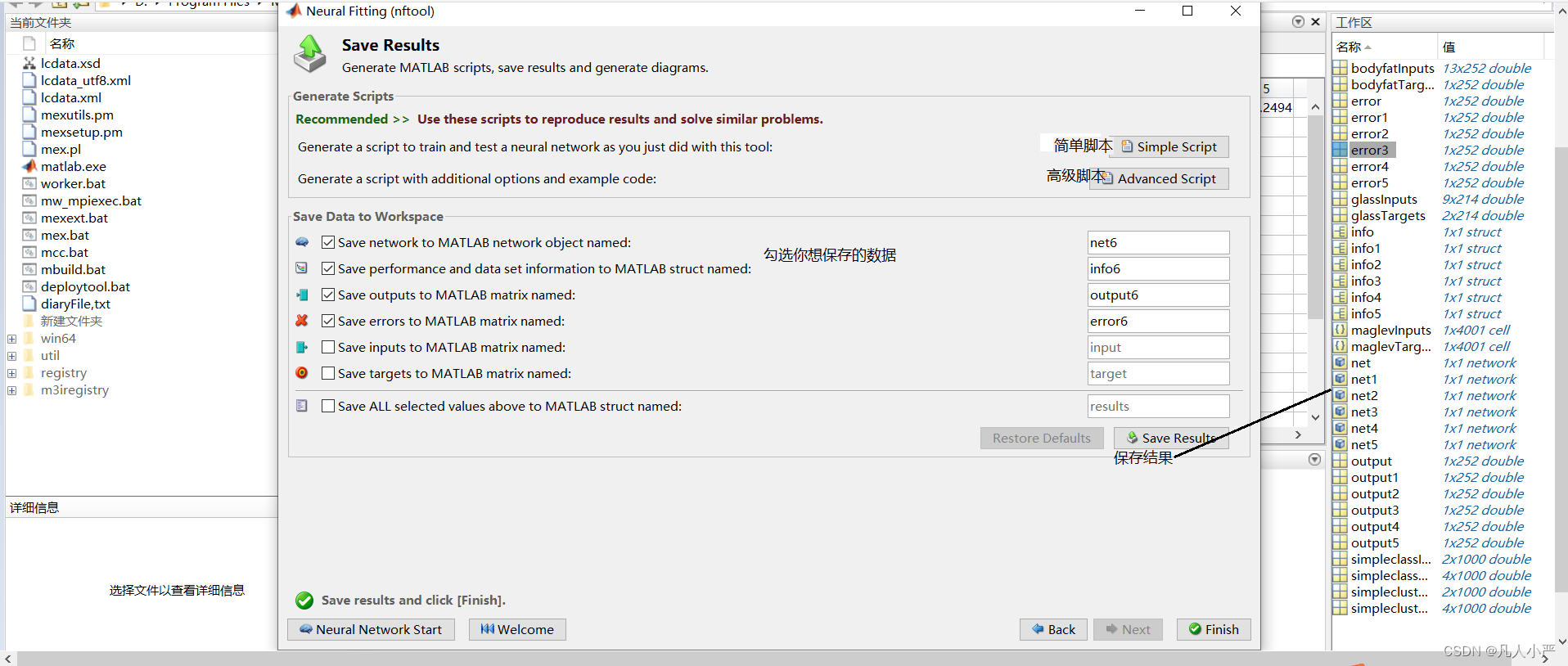
这里是简单脚本
% Solve an Input-Output Fitting problem with a Neural Network
% Script generated by Neural Fitting app
% Created 04-May-2024 15:17:51
%
% This script assumes these variables are defined:
%
% bodyfatInputs - input data. 输入数据
% bodyfatTargets - target data.
x = bodyfatInputs;
t = bodyfatTargets;
% Choose a Training Function 选择训练模式
% For a list of all training functions type: help nntrain
% 'trainlm' is usually fastest.
% 'trainbr' takes longer but may be better for challenging problems.
% 'trainscg' uses less memory. Suitable in low memory situations.
trainFcn = 'trainlm'; % Levenberg-Marquardt backpropagation.
% Create a Fitting Network 隐藏层个数
hiddenLayerSize = 10;
net = fitnet(hiddenLayerSize,trainFcn);
% Setup Division of Data for Training, Validation, Testing 样本分配
net.divideParam.trainRatio = 70/100;
net.divideParam.valRatio = 15/100;
net.divideParam.testRatio = 15/100;
% Train the Network 训练
[net,tr] = train(net,x,t);
% Test the Network 测试
y = net(x);
e = gsubtract(t,y);
performance = perform(net,t,y)
% View the Network 数据分析
view(net)
% Plots
% Uncomment these lines to enable various plots.
%figure, plotperform(tr)
%figure, plottrainstate(tr)
%figure, ploterrhist(e)
%figure, plotregression(t,y)
%figure, plotfit(net,x,t)
到这nftool的简单使用就结束了。
希望对你有帮助!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









