







二分查找算法也称折半查找,是一种非常高效的工作于有序数组的查找算法。
1) 基础版Basic
需求:在有序数组 A 内,查找值 target
-
如果找到返回索引
-
如果找不到返回 -1
算法描述
| 前提 | 给定一个内含 n 个元素的有序数组 A,满足 A0 <= A1 <= A2 <= ... <=An-1,一个待查值 target(允许两个元素相等,后面会展开讲解) |
| 1 | 设置 i=0,j=n-1 |
| 2 | 如果 i > j,结束查找,没找到 |
| 3 | 设置 m = floor((i+j)/2) ,m 为中间索引,floor 是向下取整( <= (i+j)/2 的最小整数) |
| 4 | 如果 target < Am 设置 j = m - 1,跳到第2步 |
| 5 | 如果 Am < target 设置 i = m + 1,跳到第2步 |
| 6 | 如果 Am = target,结束查找,找到了 |
P.S.
对于一个算法来讲,都有较为严谨的描述,上面是一个例子
后续讲解时,以简明直白为目标,不会总以上面的方式来描述算法

 target == 14
target == 14


第二种情况:


第三种情况:找不到





public class BinarySearch {
/**
* <h1>二分查找基础版</h1>
* @Params:a-待查找的升序数组
* <p>target-待查找的目标值</p>
* @Returns:
* <p>找到则返回索引</p>
* <p>找不到返回-1</p>
*/
public static int binarySearchBasic(int[] a,int target) {
int i = 0, j = a.length - 1;//设置指针和初值
while (i <= j) { // 范围内有东西 为什么要i<=j参考上面二分查找的可视化过程 i跟j相等的元素不能漏掉!
int m = (i+j)>>>1;
if (target < a[m]) { //目标在左边
j = m - 1;
} else if (a[m]<target) { //目标在右边
i = m + 1;
} else { //找到
return m;
}
}
return -1;
}
/*
问题1:
i<=j的理解==>不要漏掉i=j指向的元素
问题2:
m = (i+j)/2 有没有问题?
来看这样一个示例: int i = 0;int j = Integer.MAX_VALUE-1;
int m = (i+j)/2;
System.out.println(m); 1073741823
i = m+1;
m = (i+j)/2;
System.out.println(m); -536870913
//因为i = m+1已经是一个很大的数字 然后i再加j就超出了整数的最大值 因此为负数
Java中没有无符号的整数
同一个二进制数 第一个是不是符号位会导致结果不同 11111111 255 11111111 -1
解决:无符号右移运算符>>>
m = (i+j)>>>1;
问题3:
都写成小于号有啥好处?
因为数组是升序的,一目了然
*/
}

Java会把最高位视为最高位

改动版: j 作为边界 指向的一定不是查找目标
做题常见
也可以返回 ==> i : 就是最左边找到的情况or
i : 没找到的情况比target大的最靠左的索引
所以 返回i的含义就是 返回 <= target的最靠左索引
/**
* <h1>二分查找改动版</h1>
* @Params:a-待查找的升序数组
* <p>target-待查找的目标值</p>
* @Returns:
* <p>找到则返回索引</p>
* <p>找不到返回-1</p>
*/
public static int binarySearchBasic(int[] a,int target) {
int i = 0, j = a.length;//第一处
while (i < j) { //第二处
int m = (i+j)>>>1;
if (target < a[m]) { //第三处
j = m;
} else if (a[m]<target) {
i = m + 1;
} else {
return m;
}
}
return -1;
}





如果加上了在if(i<=j)的话会进入死循环
衡量算法好坏

事后统计法:跟数据规模和硬件有关.如果数据量规模很小的话两个算法可能差不多
事前分析法:前提:1.只分析最差的执行情况,2.假设每行语句执行时间一样 t
线性查找 int i = 0 1
i<a.length n+1
i++ n
a[i] == target n
return -1; 1 运算运行语句总次数: 3*n + 3
________________________________________________________________________
二分查找:
1 [2,3,4] 5 相比左侧 右侧没找到更差
int i = 0, j = a.length -1 ; 2
return -1; 1
元素个数是4-7 执行次数是3次 floor(log_2(4)) = 2 +1
8-15 4 floor(log_2(8)) = 3 +1
16-31 5 floor(log_2(16)) = 4 +1
32-63 6 floor(log_2(32)) = 5 +1
.... ....
循环次数 L = floor(log_2(n)) + 1
i <= j L+1
int m = (i+j) >>>1; L
target < a[m] L
a[m] < target L
i = m +1 L
(floor(log_2(n)) + 1) * 5 + 4
____________________________________________________________________
当 n = 4 时: 线性查找 :3*4 + 3 = 15t 二分查找: 19t
n = 1024 3074t 59t



计算机科学中,时间复杂度是用来衡量:一个算法的执行,随数据规模增大,而增长的时间成本
-
不依赖于环境因素
如何表示时间复杂度呢?
-
假设算法要处理的数据规模是 n,代码总的执行行数用函数 f(n) 来表示,例如:
-
线性查找算法的函数 f(n) = 3*n + 3
-
二分查找算法的函数 f(n) = (floor(log_2(n)) + 1) * 5 + 4
-
-
为了对 f(n) 进行化简,应当抓住主要矛盾,找到一个变化趋势与之相近的表示法
-




空间复杂度
与时间复杂度类似,一般也使用大 O 表示法来衡量:一个算法执行随数据规模增大,而增长的额外空间成本
这个算法占用额外空间 i , j, m ==> 3*4=12个字节 O(1)
public static int binarySearchBasic(int[] a, int target) {
int i = 0, j = a.length - 1; // 设置指针和初值
while (i <= j) { // i~j 范围内有东西
int m = (i + j) >>> 1;
if(target < a[m]) { // 目标在左边
j = m - 1;
} else if (a[m] < target) { // 目标在右边
i = m + 1;
} else { // 找到了
return m;
}
}
return -1;
}二分查找性能
下面分析二分查找算法的性能
时间复杂度
-
最坏情况:O(log n) (平均情况也是)
-
最好情况:如果待查找元素恰好在数组中央,只需要循环一次 O(1)
空间复杂度
-
需要常数个指针 $i,j,m$,因此额外占用的空间是 O(1)
二分查找平衡版
public static int binarySearchBasic(int[] a,int target) {
int i = 0, j = a.length-1;
//假设while循环了L次 元素在左边也是运行L次
//如果元素在最右边 既要执行if 也要执行else if 这个时候运行2L次
//左右不平衡 左边查找成本低,右边查找成本高
while (i <= j) {
int m = (i+j)>>>1;
if (target < a[m]) { //
j = m-1;
} else if (a[m]<target) { //
i = m + 1;
} else {
return m;
}
}
return -1;
}所以来看如何达到平衡:



public static int binarySearchBalance(int[] a, int target) {
int i = 0, j = a.length;
while (1 < j - i) {
int m = (i + j) >>> 1;
if (target < a[m]) {
j = m;
} else {
i = m;
}
}
return (a[i] == target) ? i : -1;
}思想:
-
左闭右开的区间,i 指向的可能是目标,而 j 指向的不是目标
-
不奢望循环内通过 m 找出目标, 缩小区间直至剩 1 个, 剩下的这个可能就是要找的(通过 i)
-
j - i > 1的含义是,在范围内待比较的元素个数 > 1
-
-
改变 i 边界时,它指向的可能是目标,因此不能 m+1
-
循环内的平均比较次数减少了
-
时间复杂度 O(log(n))
Java 版
private static int binarySearch0(long[] a, int fromIndex, int toIndex,
long key) {
int low = fromIndex;
int high = toIndex - 1;
while (low <= high) {
int mid = (low + high) >>> 1;
long midVal = a[mid];
if (midVal < key)
low = mid + 1;
else if (midVal > key)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); // key not found.
}




-
例如 [1,3,5,6] 要插入 2 那么就是找到一个位置,这个位置左侧元素都比它小
-
等循环结束,若没找到,low 左侧元素肯定都比 target 小,因此 low 即插入点
-
-
插入点取负是为了与找到情况区分
-
-1 是为了把索引 0 位置的插入点与找到的情况进行区分
对于我们基础版的代码i 和 java版的代码 就是找不到数据但是按照升序要插入的点
为什么要 - (low + 1) 因为假设low等于0 那0 和 - 0 总是相等的,所以不知道你是找到了0这个插入点还是你找不到返回了一个0,所以必须加一个-1

3) Leftmost 与 Rightmost
有时我们希望返回的是最左侧的重复元素,如果用 Basic 二分查找
-
对于数组 [1, 2, 3, 4, 4, 5, 6, 7],查找元素4,结果是索引3
-
对于数组 [1, 2, 4, 4, 4, 5, 6, 7],查找元素4,结果也是索引3,并不是最左侧的元素
看一下运行过程:

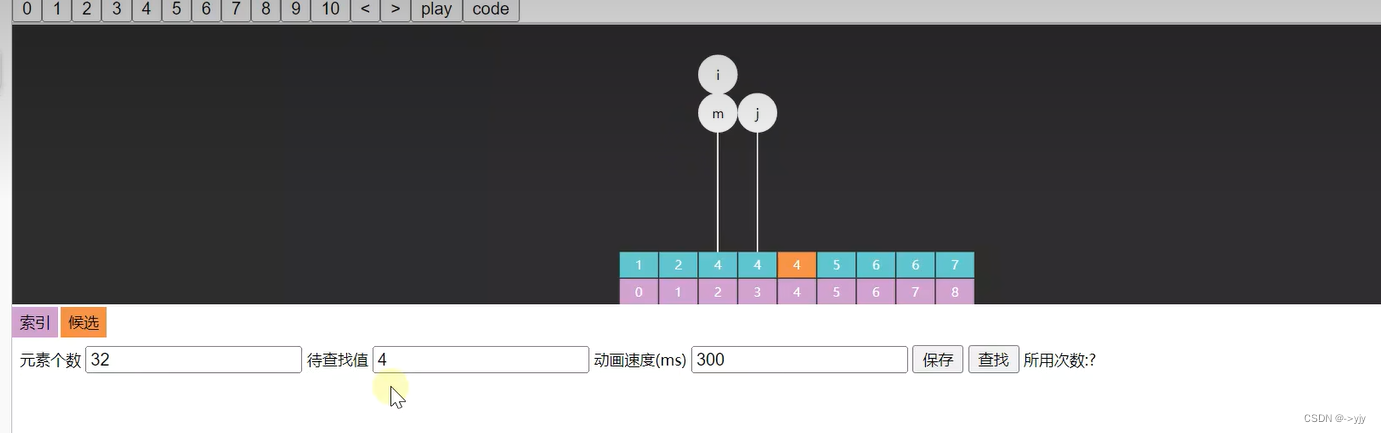

再看一个:


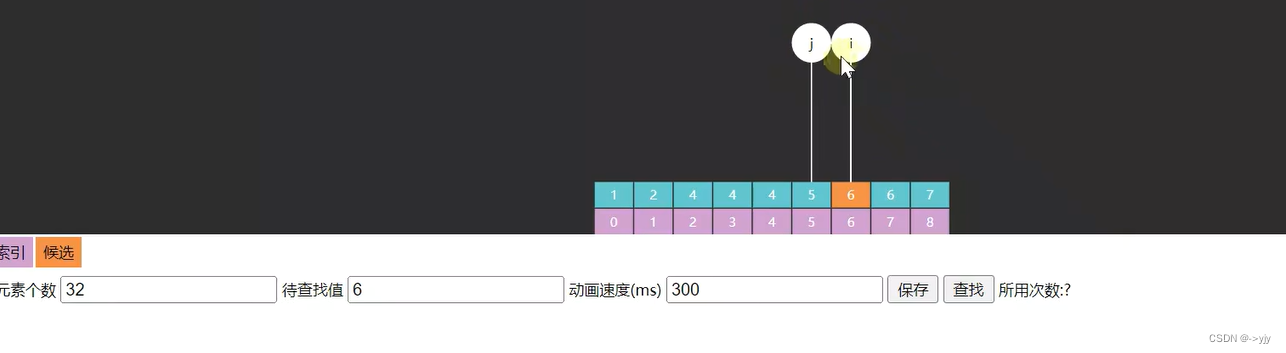
public static int binarySearchLeftmost1(int[] a,int target) {
int i = 0, j = a.length-1;
int candidate = -1;
while (i <= j) {
int m = (i+j)>>>1;
if (target < a[m]) {
j = m-1;
} else if (a[m]<target) {
i = m + 1;
} else {
// 记录候选位置
candidate = m;
j = m-1;//向左走
}
}
return candidate;
}如果希望返回的是最右侧元素
public static int binarySearchRightmost1(int[] a, int target) {
int i = 0, j = a.length - 1;
int candidate = -1;
while (i <= j) {
int m = (i + j) >>> 1;
if (target < a[m]) {
j = m - 1;
} else if (a[m] < target) {
i = m + 1;
} else {
candidate = m; // 记录候选位置
i = m + 1; // 继续向右
}
}
return candidate;
}应用
对于 Leftmost 与 Rightmost,可以返回一个比 -1 更有用的值
public static int binarySearchLeftmost2(int[] a,int target) {
int i = 0, j = a.length-1;
while (i <= j) {
int m = (i+j)>>>1;
if (target <= a[m]) {
j = m-1;
} else{
i = m + 1;
}
}
return i;//返回i的含义:
}
i : 就是最左边找到的情况

再看一个:

i : 没找到的情况比target大的最靠左的索引
所以 返回i的含义就是 返回 <= target的最靠左索引
同样的 Rightmost
public static int binarySearchRightmost(int[] a, int target) {
int i = 0, j = a.length - 1;
while (i <= j) {
int m = (i + j) >>> 1;
if (target < a[m]) {
j = m - 1;
} else {
i = m + 1;
}
}
return i - 1;
}-
大于等于中间值,都要向右找
-
如果找不到找到的值是比目标值小的<=目标
返回小于等于target最靠右的索引

范围查询:
-
查询 x < 4,0 .. leftmost(4) - 1
-
查询 x <= 4,0 .. rightmost(4)
-
查询 4 >x,rightmost(4) + 1 .. 无穷大
-
查询 4 >= x, leftmost(4) .. 无穷大
-
查询 4 <= x <=7,leftmost(4) .. rightmost(7)
-
查询 4 < x < 7,rightmost(4)+1 .. leftmost(7)-1
求排名:leftmost(target) + 1
-
target 可以不存在,如:leftmost(5)+1 = 6
-
target 也可以存在,如:leftmost(4)+1 = 3
求前任(predecessor):leftmost(target) - 1
-
$leftmost(3) - 1 = 1$,前任 a_1 = 2
-
$leftmost(4) - 1 = 1$,前任 a_1 = 2
求后任(successor):$rightmost(target)+1$
-
rightmost(5) + 1 = 5,后任 a_5 = 7
-
rightmost(4) + 1 = 5,后任 a_5 = 7
求最近邻居:
-
前任和后任距离更近者
习题
1) 时间复杂度估算
用函数 f(n) 表示算法效率与数据规模的关系,假设每次解决问题需要 1 微秒(10^{-6} 秒),进行估算:
-
如果 f(n) = n^2 那么 1 秒能解决多少次问题?1 天呢?
-
如果 f(n) = log_2(n) 那么 1 秒能解决多少次问题?1 天呢?
-
如果 f(n) = n! 那么 1 秒能解决多少次问题?1 天呢?
参考解答
-
1秒 sqrt{10^6} = 1000 次,1 天 sqrt{10^6 * 3600 * 24} \approx 293938$ 次
-
1秒 2^{1,000,000} 次,一天 $2^{86,400,000,000}$
-
推算如下
-
$10! = 3,628,800$ 1秒能解决 $1,000,000$ 次,因此次数为 9 次
-
$14!=87,178,291,200$,一天能解决 $86,400,000,000$ 次,因此次数为 13 次
-
2) 耗时估算
一台机器对200个单词进行排序花了200秒(使用冒泡排序),那么花费800秒,大概可以对多少个单词进行排序
a. 400
b. 600
c. 800
d. 1600
答案
-
a
解释
-
冒泡排序时间复杂度是 $O(N^2)$
-
时间增长 4 倍,而因此能处理的数据量是原来的 $\sqrt{4} = 2$ 倍
3) E01. 二分查找-Leetcode 704
要点:减而治之,可以用递归或非递归实现
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1
例如
输入: nums = [-1,0,3,5,9,12], target = 9 输出: 4 解释: 9 出现在 nums 中并且下标为 4 输入: nums = [-1,0,3,5,9,12], target = 2 输出: -1 解释: 2 不存在 nums 中因此返回 -1
参考答案:略,可以用讲过的任意一种二分求解
4) E02. 搜索插入位置-Leetcode 35
要点:理解谁代表插入位置
给定一个排序数组和一个目标值
-
在数组中找到目标值,并返回其索引
-
如果目标值不存在于数组中,返回它将会被按顺序插入的位置
例如
输入: nums = [1,3,5,6], target = 5 输出: 2 输入: nums = [1,3,5,6], target = 2 输出: 1 输入: nums = [1,3,5,6], target = 7 输出: 4
参考答案1:用二分查找基础版代码改写,基础版中,找到返回 m,没找到 i 代表插入点,因此有
public int searchInsert(int[] a, int target) {
int i = 0, j = a.length - 1;
while (i <= j) {
int m = (i + j) >>> 1;
if (target < a[m]) {
j = m - 1;
} else if (a[m] < target) {
i = m + 1;
} else {
return m;
}
}
return i; // 原始 return -1
}参考答案2:用二分查找平衡版改写,平衡版中
-
如果 target == a[i] 返回 i 表示找到
-
如果 target < a[i],例如 target = 2,a[i] = 3,这时就应该在 i 位置插入 2
-
如果 a[i] < target,例如 a[i] = 3,target = 4,这时就应该在 i+1 位置插入 4
public static int searchInsert(int[] a, int target) {
int i = 0, j = a.length;
while (1 < j - i) {
int m = (i + j) >>> 1;
if (target < a[m]) {
j = m;
} else {
i = m;
}
}
return (target <= a[i]) ? i : i + 1;
// 原始 (target == a[i]) ? i : -1;
}参考答案3:用 leftmost 版本解,返回值即为插入位置(并能处理元素重复的情况)
public int searchInsert(int[] a, int target) {
int i = 0, j = a.length - 1;
while(i <= j) {
int m = (i + j) >>> 1;
if(target <= a[m]) {
j = m - 1;
} else {
i = m + 1;
}
}
return i;
}5) E03. 搜索开始结束位置-Leetcode 34
给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
你必须设计并实现时间复杂度为 O(log n) 的算法解决此问题
例如
输入:nums = [5,7,7,8,8,10], target = 8 输出:[3,4] 输入:nums = [5,7,7,8,8,10], target = 6 输出:[-1,-1] 输入:nums = [], target = 0 输出:[-1,-1]
参考答案
public static int left(int[] a, int target) {
int i = 0, j = a.length - 1;
int candidate = -1;
while (i <= j) {
int m = (i + j) >>> 1;
if (target < a[m]) {
j = m - 1;
} else if (a[m] < target) {
i = m + 1;
} else {
candidate = m;
j = m - 1;
}
}
return candidate;
}
public static int right(int[] a, int target) {
int i = 0, j = a.length - 1;
int candidate = -1;
while (i <= j) {
int m = (i + j) >>> 1;
if (target < a[m]) {
j = m - 1;
} else if (a[m] < target) {
i = m + 1;
} else {
candidate = m;
i = m + 1;
}
}
return candidate;
}
public static int[] searchRange(int[] nums, int target) {
int x = left(nums, target);
if(x == -1) {
return new int[] {-1, -1};
} else {
return new int[] {x, right(nums, target)};
}
}6) E04.准时到达的列车最小时速 -Leetcode
题目描述
给你一个浮点数 hour ,表示你到达办公室可用的总通勤时间。要到达办公室,你必须按给定次序乘坐 n 趟列车。另给你一个长度为 n 的整数数组 dist ,其中 dist[i] 表示第 i 趟列车的行驶距离(单位是千米)。
每趟列车均只能在整点发车,所以你可能需要在两趟列车之间等待一段时间。
- 例如,第
1趟列车需要1.5小时,那你必须再等待0.5小时,搭乘在第 2 小时发车的第2趟列车。
返回能满足你准时到达办公室所要求全部列车的 最小正整数 时速(单位:千米每小时),如果无法准时到达,则返回 -1 。
生成的测试用例保证答案不超过 107 ,且 hour 的 小数点后最多存在两位数字 。
示例 1:
输入:dist = [1,3,2], hour = 6 输出:1 解释:速度为 1 时: - 第 1 趟列车运行需要 1/1 = 1 小时。 - 由于是在整数时间到达,可以立即换乘在第 1 小时发车的列车。第 2 趟列车运行需要 3/1 = 3 小时。 - 由于是在整数时间到达,可以立即换乘在第 4 小时发车的列车。第 3 趟列车运行需要 2/1 = 2 小时。 - 你将会恰好在第 6 小时到达。
示例 2:
输入:dist = [1,3,2], hour = 2.7 输出:3 解释:速度为 3 时: - 第 1 趟列车运行需要 1/3 = 0.33333 小时。 - 由于不是在整数时间到达,故需要等待至第 1 小时才能搭乘列车。第 2 趟列车运行需要 3/3 = 1 小时。 - 由于是在整数时间到达,可以立即换乘在第 2 小时发车的列车。第 3 趟列车运行需要 2/3 = 0.66667 小时。 - 你将会在第 2.66667 小时到达。
示例 3:
输入:dist = [1,3,2], hour = 1.9 输出:-1 解释:不可能准时到达,因为第 3 趟列车最早是在第 2 小时发车。
提示:
n == dist.length1 <= n <= 10^51 <= dist[i] <= 10^51 <= hour <= 10^9hours中,小数点后最多存在两位数字
思路:
如果列车的速度大于等于最小时速,则一定可以准时到达;如果列车的速度小于最小时速,则一定不能准时到达。因此,这道题是二分查找判定问题,需要找到最小时速。

62ms
class Solution {
public int minSpeedOnTime(int[] dist, double hour) {
if (dist.length > Math.ceil(hour)) return -1;
// 搜索边界
int left = 1, right = Integer.MAX_VALUE;//right是取不到的只是一个边界
while (left < right) {
int mid = (left+right)>>>1;
// 如果以 mid 速度可达,那么就尝试减小速度
if (check(dist, hour, mid)) right = mid;
// 否则就需要加了
else left = mid + 1;
}
return left;
}
private boolean check(int[] dist, double hour, int speed) {
double cnt = 0.0;
// 对除了最后一个站点以外的时间进行向上取整累加
for (int i = 0; i < dist.length - 1; ++i) {
// 除法的向上取整
cnt += (dist[i]- 1) / speed+1;
}
// 加上最后一个站点所需的时间
cnt += (double) dist[dist.length - 1] / speed;
return cnt <= hour;
}
}
46ms
class Solution {
public int minSpeedOnTime(int[] dist, double hour) {
if (dist.length > Math.ceil(hour)) return -1;
int r = 0;
for(int a_ : dist) {
r = Math.max(a_, r);
}//找出dist最大的路程 而不是跟上一段代码一样从1e7开始
// 搜索边界
int left = 1, right = r * 100;//
while (left < right) {
int mid = (left+right)>>>1;
// 如果以 mid 速度可达,那么就尝试减小速度
if (check(dist, hour, mid)) right = mid;
// 否则就需要加了
else left = mid + 1;
}
return left;
}
private boolean check(int[] dist, double hour, int speed) {
double cnt = 0.0;
// 对除了最后一个站点以外的时间进行向上取整累加
for (int i = 0; i < dist.length - 1; ++i) {
// 除法的向上取整
cnt += (dist[i]- 1) / speed+1;
}
// 加上最后一个站点所需的时间
cnt += (double) dist[dist.length - 1] / speed;
return cnt <= hour;
}
}
class Solution {
public int minSpeedOnTime(int[] dist, double hour) {
//边界条件
if(dist.length > Math.ceil(hour)){
return -1;
}
//确定上下边界
int left = 1;
int right = 0;
for(int a :dist){
right = Math.max(a,right);
}//数组最大的路程
right = right * 100;//因为hour小数点后最多存两位数字
//因为最后一次的时候时间就直接等于路程除以速度不用向上取整
//如果此时的时间是0.几几个小时的话那算就会比right大至多100倍
while(left<right){
int mid = (left+right)>>>1;
if(check(dist,mid,hour)){
right = mid;//符合那就看看有没有速度再慢的符合
}
else{
left = mid +1;
}
}
return left;
}
private boolean check(int[] dist,int speed,double hour){
double ConsumingTime = 0;
for(int i = 0;i<dist.length-1;i++){
ConsumingTime+=(dist[i]-1)/speed+1;
}
ConsumingTime +=(double) (dist[dist.length-1])/speed;
return ConsumingTime<=hour;
}
}有的文章可能会在 (right + left)>>>1写成: left + (right - left) / 2
这是用的一个小技巧,防止左右边界相加溢出的操作。
上边界取 max( dist数组的最大, hour的小数部分在dist[dist.length-1]的速度)
java的执行用时能到51ms
int max=(int)(dist[dist.length-1]/(hour-(int)hour))+1;
int left=1,right=Math.max(dist.length,max);
for (int i : dist) {
right=Math.max(right,i);
}7) E05 可移除字符的最大数目-Leetcode 1898
题目描述
给你两个字符串 s 和 p ,其中 p 是 s 的一个 子序列 。同时,给你一个元素 互不相同 且下标 从 0 开始 计数的整数数组 removable ,该数组是 s 中下标的一个子集(s 的下标也 从 0 开始 计数)。
请你找出一个整数 k(0 <= k <= removable.length),选出 removable 中的 前 k 个下标,然后从 s 中移除这些下标对应的 k 个字符。整数 k 需满足:在执行完上述步骤后, p 仍然是 s 的一个 子序列 。更正式的解释是,对于每个 0 <= i < k ,先标记出位于 s[removable[i]] 的字符,接着移除所有标记过的字符,然后检查 p 是否仍然是 s 的一个子序列。
返回你可以找出的 最大 k ,满足在移除字符后 p 仍然是 s 的一个子序列。
字符串的一个 子序列 是一个由原字符串生成的新字符串,生成过程中可能会移除原字符串中的一些字符(也可能不移除)但不改变剩余字符之间的相对顺序。
示例 1:
输入:s = "abcacb", p = "ab", removable = [3,1,0] 输出:2 解释:在移除下标 3 和 1 对应的字符后,"abcacb" 变成 "accb" 。 "ab" 是 "accb" 的一个子序列。 如果移除下标 3、1 和 0 对应的字符后,"abcacb" 变成 "ccb" ,那么 "ab" 就不再是 s 的一个子序列。 因此,最大的 k 是 2 。
示例 2:
输入:s = "abcbddddd", p = "abcd", removable = [3,2,1,4,5,6] 输出:1 解释:在移除下标 3 对应的字符后,"abcbddddd" 变成 "abcddddd" 。 "abcd" 是 "abcddddd" 的一个子序列。
示例 3:
输入:s = "abcab", p = "abc", removable = [0,1,2,3,4] 输出:0 解释:如果移除数组 removable 的第一个下标,"abc" 就不再是 s 的一个子序列。
提示:
1 <= p.length <= s.length <= 1050 <= removable.length < s.length0 <= removable[i] < s.lengthp是s的一个 子字符串s和p都由小写英文字母组成removable中的元素 互不相同
class Solution {
public int maximumRemovals(String s, String p, int[] removable) {
int left = 0, right = removable.length;
while (left < right) {
int mid = (left + right + 1) >> 1;
if (check(s, p, removable, mid)) {
left = mid;
} else {
right = mid - 1;
}
}
return left;
}
private boolean check(String s, String p, int[] removable, int mid) {
int m = s.length(), n = p.length(), i = 0, j = 0;
Set<Integer> ids = new HashSet<>();
for (int k = 0; k < mid; ++k) {
ids.add(removable[k]);
}
while (i < m && j < n) {
if (!ids.contains(i) && s.charAt(i) == p.charAt(j)) {
++j;
}
++i;
}
return j == n;
}
}Java 二分查找之最值问题
主要解题思路
首先,这类问题的题目一般都会包含最大,最小字眼,并且一般是将最小值变大(最大值变小)或者 变大(变小)有明显的限制条件。
比如本题,我们要求解最大的k,也就是最大的removable数组下标,也就是能挨个删除最多个removable所指的字符的情况下,p仍然是s的子序列。
对于这种问题,我们要做的便是:
1.列出答案的范围
2.对列出的范围进行二分查找
3.对二分查找的目标数值进行检测,查看是否满足要求,之后再去缩小二分范围


class Solution {
public int maximumRemovals(String s, String p, int[] removable) {
char[] str0 = s.toCharArray();
char[] str1 = p.toCharArray();
int ans = 0;//我们要返回的值,答案
int left = 1;//左边界
int right = removable.length;//右边界
while(left<=right){//开始循环找答案
int mid = (left+right)>>>1;//位运算高效求中点
//这里调用的方法下面讲,ta的作用就是删除前mid个removable所指的位置的字符后
if(search1(mid,str0,str1,removable)){//是否还能满足p是s的子序列,如果满足返回true
ans = mid;//进入条件则说明满足,当前的mid就是候选答案之一,最后一个满足的mid就一定是答案
left = mid+1;//当前mid满足的话我们就要去尝试更大的数值,以缩小答案的范围
}else{//不满足
right = mid-1;//那我们就要去尝试更小的数,寻找能满足的
}
str0 = s.toCharArray();//我们在search1方法中改变了str0的值,所以要重新赋值
}
return ans;
}
private boolean search1(int mid,char[] str0,char[] str1,int[] removable){
for(int i = 0;i<mid;i++){
str0[removable[i]] = '1';
}
int j = 0;
for(int i = 0;i<str0.length;i++){//判断p是不是s的子序列
if(j<str1.length){
if(str1[j]==str0[i]){
j++;
}
}else{//已经遍历完p,即可说明p是s的子序列
return true;
}
}
if(j==str1.length){//已经遍历完p,即可说明p是s的子序列
return true;
}
return false;//已经遍历完s但是完全没有找到p对应的字符,即p不是s的子序列
}
}8) E06 爱吃香蕉的珂珂 - Leetcode875
class Solution {
public int minEatingSpeed(int[] piles, int h) {
int maxVal = 1;
for(int pile:piles){
maxVal = Math.max(maxVal,pile);
}
// 速度最小的时候,耗时最长
int left = 1;
// 速度最大的时候, 耗时最短
int right = maxVal;
while(left<right){
int mid = (left+right)>>>1;
if(calculateSum(piles,mid) > h){
// 耗时太多,说明速度太慢了,下一轮搜索区间是[mid+1,right]
left = mid +1;
}else{
right = mid;
}
}
return left;
}
/**
* 如果返回的小时数严格大于 H,就不符合题意
*
* @param piles
* @param speed
* @return 需要的小时数
*/
private int calculateSum(int[] piles,int speed){
int sum = 0;
for(int pile:piles){
sum+=(pile+speed-1)/speed;
}
return sum;
}
}分享一个更容易理解整数相除向上取整 的方法:如果pile % speed == 0整除,直接相除,否则说明有余数+1
private int calculateSum(int[] piles,int speed){
int sum = 0;
for(int pile:piles){
sum+=pile % speed == 0?pile/ speed:pile/speed+1;
}
return sum;
}pile % speed == 0 ? pile / speed : pile / speed + 1;这样写也行就是效率低了点

class Solution {
public int maxDistance(int[] position, int m) {
Arrays.sort(position);
int hi = (position[position.length-1]-position[0])/(m-1);
int lo = 1;
int ans = 1;
while(lo<=hi){
int mid = lo + (hi-lo)/2;
if(check(position,mid,m)){
ans = mid;
lo = mid +1;
}else{
hi = mid-1;
}
}
return ans;
}
boolean check(int[] position,int distance,int m){
int count = 1;
int i = 0;
for(int j =1;j<position.length;j++){
if(position[j] - position[i] >= distance){
i=j;
count++;
if(count>=m)return true;
}
}
return false;
}
}1760. 袋子里最少数目的球 - 力扣(LeetCode)
解题思路
- 重点:理解题意,将题目转化为可以实现的问题





class Solution {
public boolean check(int[] nums,long cost,int maxOperations){
long ans = 0;
for(int cur:nums){
if(cur % cost == 0){
ans += cur/cost-1;
}else{
ans+=cur/cost;
}
}
return ans<=maxOperations;
}
public int minimumSize(int[] nums, int maxOperations) {
long l = 1;
long r = 1000000000;
long ret = 0;
while(l<=r){
long mid = (l+r)>>>1;
if(check(nums,mid,maxOperations)){
r = mid -1;
ret = mid;
}else{
l = mid+1;
}
}
return (int)ret;
}
}class Solution {
public int minimumSize(int[] nums, int maxOperations) {
int left =1,right = Arrays.stream(nums).max().getAsInt();
while(left<right){
int mid = (left+right)>>>1;
if(operateTimes(nums,mid)<=maxOperations){
right=mid;
}else{
left= mid+1;
}
}
return left;
}
public int operateTimes(int[] nums,int x){
int times = 0;
for(int n:nums){
times+=(n-1)/x;
}
return times;
}
}class Solution {
public int minimumSize(int[] nums, int maxOperations) {
int left =1,right = (int)1e9;
while(left<right){
int mid = (right+left)>>>1;
long s = 0;
for(int v:nums){
s+=(v-1)/mid;
}
if(s<=maxOperations){
right = mid;
}
else{
left = mid+1;
}
}
return left;
}
}













 3383
3383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









