







字符串匹配BF (Brute Force 暴力匹配)
直接以一道题目来学习
28. 找出字符串中第一个匹配项的下标 - 力扣(LeetCode)


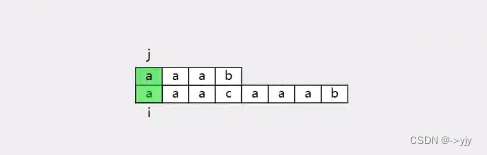
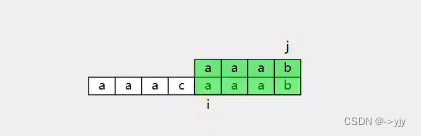
上面的字符串叫模式字符串 下面的字符串叫原始字符串
逐一匹配:
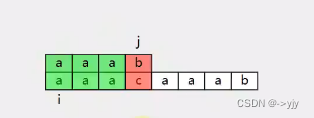
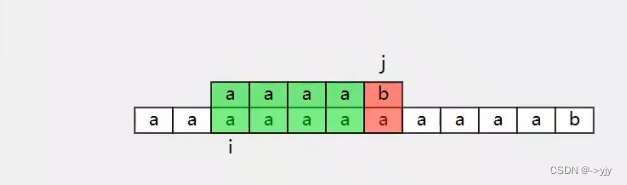
遇到不匹配的时候将j移动回第一个 i移动到开始的下一个点
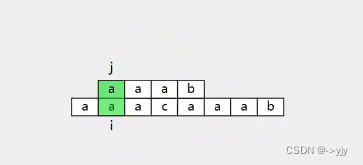
往后都是这样的过程:
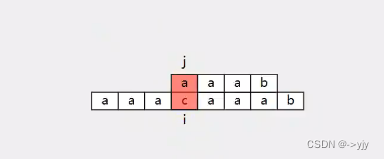
明白了这个之后我们来写一下代码:
/**
* Author : yjy
*/
public class yjy {
static int strStr(String str1,String str2){
char[] origin = str1.toCharArray(); //原始
char[] pattern = str2.toCharArray(); //模式
int i = 0;
int j = 0;
while(i<=origin.length-pattern.length){
for (j = 0; j < pattern.length; j++) {
if(pattern[j]!=origin[i+j]){
break;
}
}
if(j==pattern.length){
return i;
}
i++;
}
return -1;
}
public static void main(String[] args) {
System.out.println(strStr("aaacaaab","aaab"));
}
}______
#include<iostream>
#include<bits/stdc++.h>
using namespace std;
//BF算法函数
///在数组中第一个元素为0,从数组下标为1开始
int BF(char* S, char* T) {
//主串的长度
int lenS = strlen(S) - 1;
//子串的长度
int lenT = strlen(T) - 1;
//定义i,j分别作为主串和子串的"指针"
int i = 1, j = 1;
//当主串和子串没有匹配完全时执行该while语句
while (i <= lenS && j <= lenT) {
//如果此时主串和子串的元素匹配成功
if (S[i] == T[j]) {
//就让它们指向一个元素继续进行匹配操作
i++;
j++;
}
//如果匹配不成功的话就要进行回溯
//主串回溯.子串j指向0
else {
i = i - j + 2;
j = 1;
}
}
//如果此时j的值大于等于子串的长度说明已经匹配成功
if (j >= lenT) {
//返回匹配成功的位置
//因为此时是从下标0开始的
//所以我们往后加了一个1返回的是子串在主串中的位置
return i - lenT;
}
//匹配不成功
else {
return 0;
}
}
int main()
{
char S[100], T[100];
while (1) {
cout << "请输入主串,第一个元素请设置为0" << endl;
cin >> S;
cout << "请输入子串,第一个元素请设置为0" << endl;
cin >> T;
int ret = BF(S, T);
if (ret == 0) {
cout << "很抱歉,匹配失败,未能找到相关信息" << endl;
}
else {
cout << "匹配成功" << endl << "匹配成功的位置为" << ret << endl;
}
}
return 0;
}
输入不以0开头
#include<iostream>
#include<string.h>
using namespace std;
//BF算法函数
int BF(char*S, char*T)
{
//主串的长度
int lenS = strlen(S);
//子串的长度
int lenT = strlen(T);
//定义i,j分别作为主串和子串的指示器
int i = 0, j = 0;
//当主串和子串没有匹配完全时执行该while语句
while (i < lenS && j < lenT)
{
//如果此时主串和子串的元素匹配成功
if (S[i] == T[j])
{
//就让它们指向后一个元素继续进行匹配操作
i++;
j++;
}
//如果匹配不成功的话就要进行回溯操作
//主串回溯。子串的j指向0
else
{
i = i - j + 1;
j = 0;
}
}
//如果此时j的值大于等于子串的长度说明已经匹配成功
if (j >= lenT)
{
//返回匹配成功的位置
//因为我们此时是从下标0开始的
//所以我们往后加了一个1返回的是子串在主串中的位置
return i - lenT + 1;
}
//匹配不成功
else
{
return 0;
}
}
int main()
{
char S[100], T[100];
while (1)
{
cout << "请输入主串" << endl;
cin >> S;
cout << "请输入子串" << endl;
cin >> T;
int ret = BF(S, T);
if (ret == 0)
{
cout << "很抱歉,匹配失败,未在主串中找到子串的相关信息" << endl;
}
else
{
cout << "匹配成功" << endl << "匹配成功的位置为" << ret << endl;
}
}
return 0;
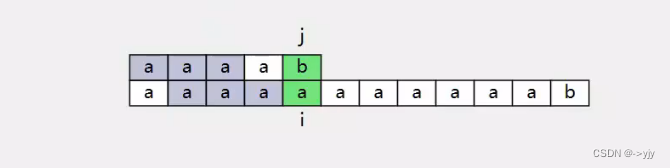
}这样暴力的匹配有一定的问题.
每一次都做了很多"无用功"
KMP
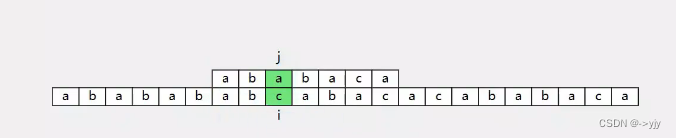
j只需要回溯到前面某个位置
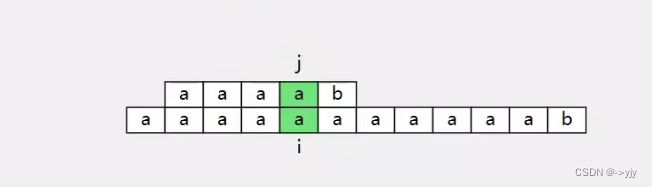
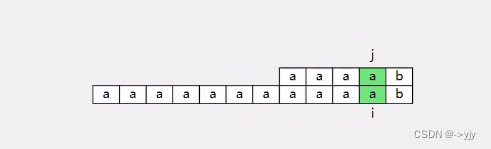
因为无需每次都回到头,效率大大提升!
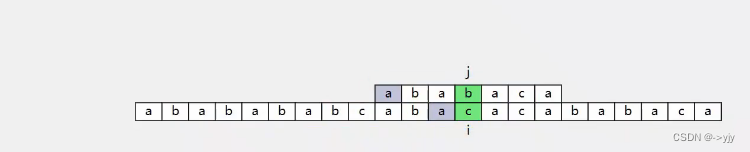
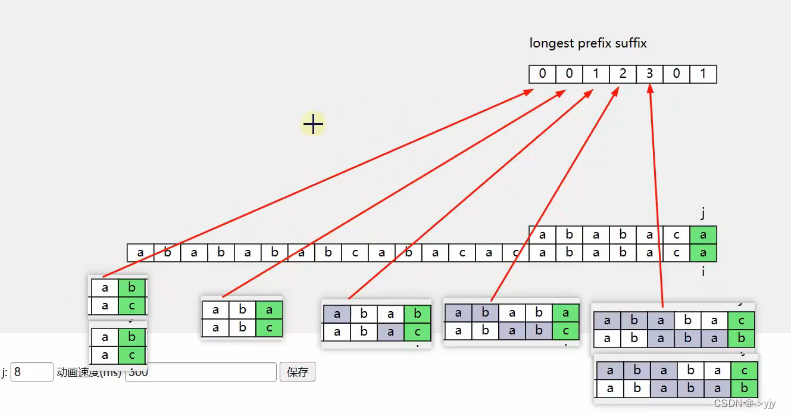
那我们来找一找有什么规律:
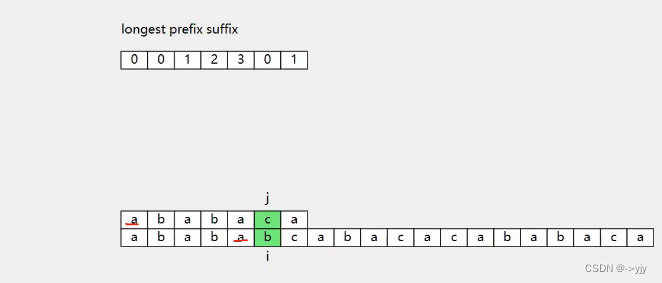
这个就是最长的子串啦! 模式字符串的前缀和原始字符串的后缀最长的前后缀
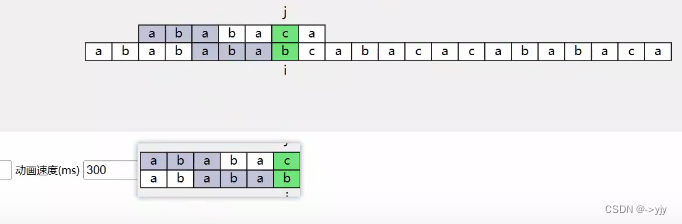
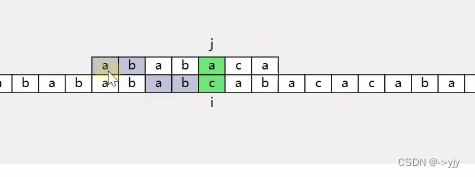
下一次:
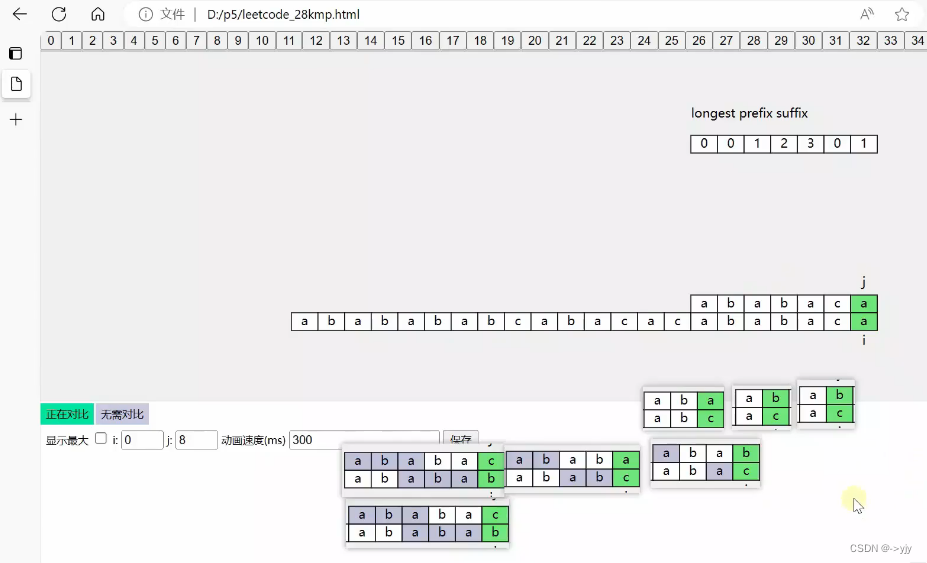
看了这么多结果我们来找找规律:
1.我们求最长前后缀的时候,其实只跟模式字符串有关,我们都是看前面相同的部分
2.我们在模式字符串中用到的字符数不同,计算出的最长前后缀的长度是确定的.
比如说:我们用了前5个字符,计算出是3 用前4个 计算出是2 ...
既然计算结果是确定的,那么我们就可以把它存储在一个一维数组中重用
所以我们就定义一个一维数组 longest prefix suffix
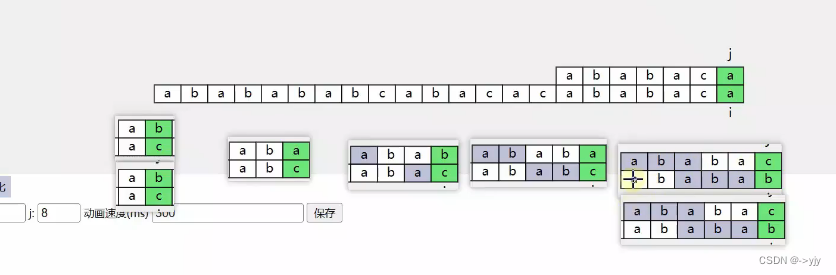
/**
* Author : yjy
*/
public class yjy {
/*
最长前后缀数组:只跟模式字符串相关
1.索引:使用了模式字符串前j个字符串-1
2.值:最长前后缀的长度(恰好是匹配失败时,j要跳转的位置)
*/
//先假定我们已经把这个最长前后缀的数组求出来了
static int[] lps(char[] pattern){
return new int[]{0,0,1,2,3,0,1};
}
public static void main(String[] args) {
System.out.println(strStr("ababababcabacacababaca","ababaca"));
System.out.println("ababababcabacacababaca".indexOf("ababaca"));
}
private static int strStr(String str1, String str2) {
char[] origin = str1.toCharArray();//原始
char[] pattern = str2.toCharArray();//模式
int[] lps = lps(pattern);//最长前后缀数组
/*
1.匹配成功,i++,j++,直到j==模式字符串长度
2.模式失败
j != 0 跳过最长前后缀字符,继续匹配
j == 0则i++
*/
int i =0;
int j = 0;
while(i<origin.length){
if(origin[i]==pattern[j]){
i++;
j++;
}else if(j==0){
i++;
}else{
//j!=0
j = lps[j-1];
}
if(j==pattern.length){
//找到解
return i-pattern.length;//i-j
}
}
return -1;
}
}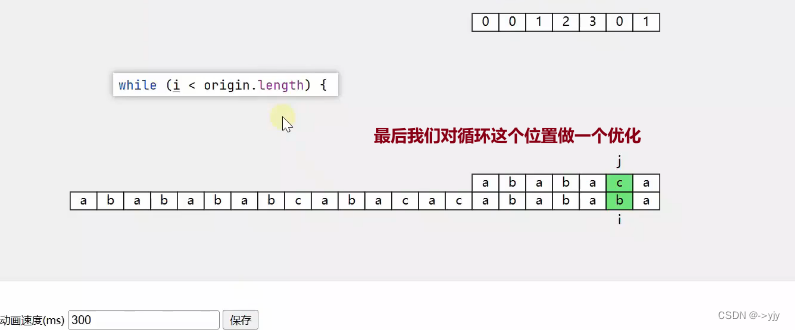
如果这个时候继续进行对比那就会超出了
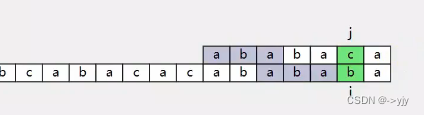

我们上面的代码不能判断这个情况,那么我们想要检查出这一种情况.

上面的差值大于下面的差值,即可认为上面超出了范围.
那么下面我们就来看看这个lps数组如何生成的.
我们现将模式字符串分为上面两个 上面那个找前缀 下面那个找后缀

使用1,2个字符的时候 都没有匹配的
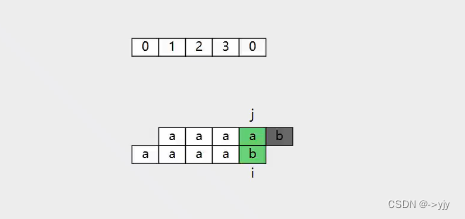
不一致的时候
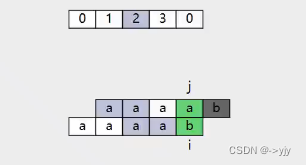
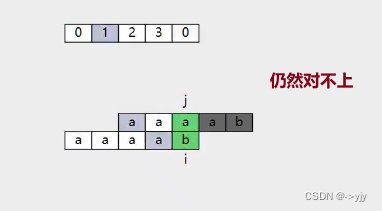
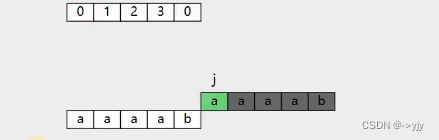
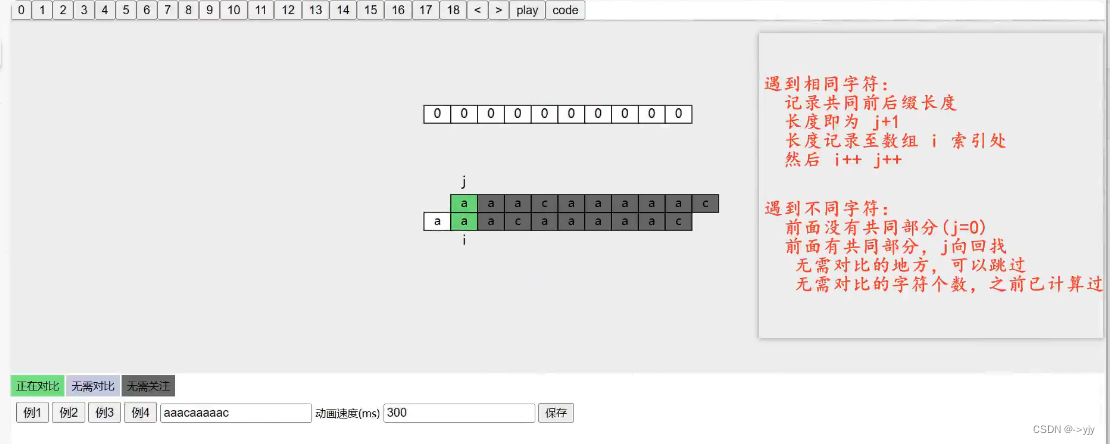
假设现在有个字符串abcabc ,我们来求他的lps数组 (有些书叫next数组)
static int[] lps(char[] pattern){
//return new int[]{0,0,1,2,3,0,1};
int[] lps = new int[pattern.length];
int i=1,j=0;
while(i<pattern.length){
if (pattern[i]==pattern[j]) {
lps[i] = j+1;
i++;
j++;
}else if(j==0){
i++;
}else{
j=lps[j-1];
}
}
return lps;
}完整代码:
/**
* Author : yjy
*/
public class yjy {
/*
最长前后缀数组:只跟模式字符串相关
1.索引:使用了模式字符串前j个字符串-1
2.值:最长前后缀的长度(恰好是匹配失败时,j要跳转的位置)
*/
//先假定我们已经把这个最长前后缀的数组求出来了
static int[] lps(char[] pattern){
//return new int[]{0,0,1,2,3,0,1};
int[] lps = new int[pattern.length];
int i=1,j=0;
while(i<pattern.length){
if (pattern[i]==pattern[j]) {
lps[i] = j+1;
i++;
j++;
}else if(j==0){
i++;
}else{
j=lps[j-1];
}
}
return lps;
}
public static void main(String[] args) {
System.out.println(strStr("ababababcabacacababaca","ababaca"));
System.out.println("ababababcabacacababaca".indexOf("ababaca"));
}
private static int strStr(String str1, String str2) {
char[] origin = str1.toCharArray();//原始
char[] pattern = str2.toCharArray();//模式
int[] lps = lps(pattern);//最长前后缀数组
/*
1.匹配成功,i++,j++,直到j==模式字符串长度
2.模式失败
j != 0 跳过最长前后缀字符,继续匹配
j == 0则i++
*/
int i =0;
int j = 0;
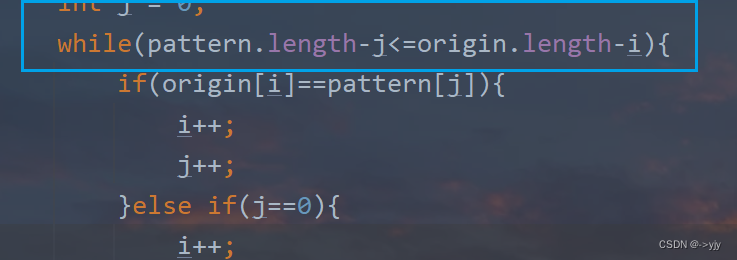
while(pattern.length-j<=origin.length-i){
if(origin[i]==pattern[j]){
i++;
j++;
}else if(j==0){
i++;
}else{
//j!=0
j = lps[j-1];
}
if(j==pattern.length){
//找到解
return i-pattern.length;//i-j
}
}
return -1;
}
}















 729
729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









