







目录
1.get请求方式:urllib.parse.quote()
2.get请求方式:urllib.parse.urlencode()
Urllib库的使用
urlllib.request.urlopen() 模拟浏览器向服务器发送请求
response 服务器返回的数据
response的数据类型是HttpResponse
字节-->字符串
解码decode
字符串-->字节
编码encode
read() 字节形式读取二进制 扩展:read(5) 返回前几个字节
readline() 读取一行
readlines() 一行一行读取 直至结束
getcode() 获取状态码
geturl() 获取url
getheaders() 获取headers
urllib.request.urlretrieve()
请求网页
请求图片
请求视频
Urllib库的基本使用
"""
作者:->yjy
所有的惊艳都曾历经平庸
"""
# 使用urllib来获取百度首页的源码
import urllib.request
# (1)定义一个url 就是你要访问的地址
# 如果你写的是https那么后面运行得到的结果就只有几行代码,https是加密传输的数据
url = 'http://www.baidu.com'
# (2)模拟浏览器向服务器发送请求 [要联网] response响应
response = urllib.request.urlopen(url)
# (3)获取响应中的页面的源码 content 内容
# read方法 返回的是字节形式的二进制数据
# 我们要将二进制的数据转换为字符串
# 二进制 --> 字符串 解码 decode('编码的格式')
content = response.read().decode('UTF-8')
# (4)打印数据
print(content)如果我还想爬取一下 广财慕课的源码:
import urllib.request
# 练习一下:爬取bilibili的源码
url = 'https://www.gdufemooc.cn'
# 模拟浏览器去请求浏览器
response = urllib.request.urlopen(url)
content = response.read().decode('UTF-8')
print(content) 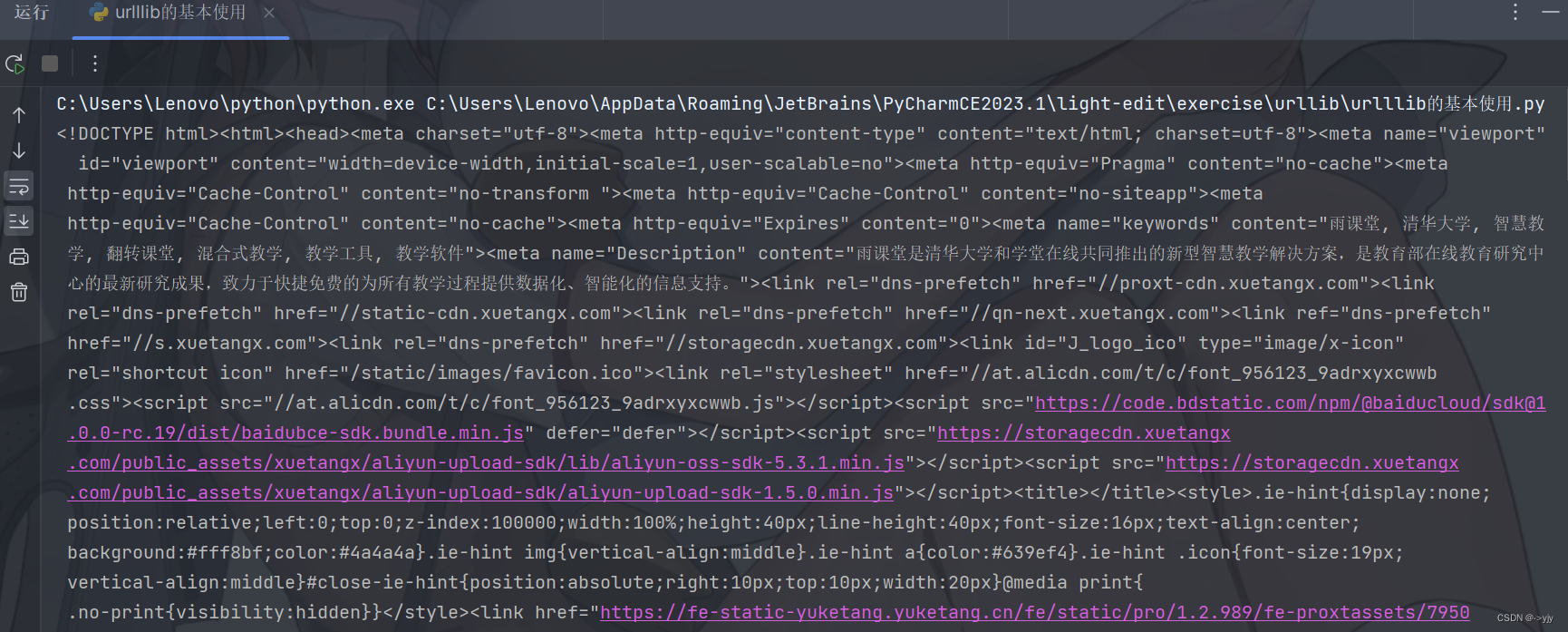
还是能够成功的!
但是当你想爬去一些其他网站的源码的时候却不一定能行,比如:bilibili
import urllib.request
# 练习一下:爬取bilibili的源码
url = 'https://www.bilibili.com/'
# 模拟浏览器去请求浏览器
response = urllib.request.urlopen(url)
content = response.read().decode('UTF-8')
print(content)
这里会报一个错误:
继续往后看,我们会解决这个问题.

一个类型和六个方法
"""
作者:->yjy
所有的惊艳都曾历经平庸
"""
import urllib.request
url = 'http://www.baidu.com'
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 一个类型和六个方法
# response是HTTPResponse的类型
print(type(response))
# 按照一个字节一个字节的去读
content = response.read()
print(content)
# 返回多少个字节
content = response.read(5)
print(content)
# 读取一行
content = response.readline()
print(content)
content = response.readlines()
print(content)
# 返回状态码 如果是200了 那么就证明我们的逻辑没有错
print(response.getcode())
# 返回的是url地址
print(response.geturl())
# 获取的是一些状态信息
print(response.getheaders())
# 一个类型 HTTPResponse
# 六个方法 read readline readlines getcode geturl getheaders下载
下载网页
import urllib.request
# 下载网页
url_page = 'http://www.baidu.com'
# url代表的是下载的路径 filename文件的名字
# 在python中 可以是变量的名字 也可以直接写值
# retrieve v.找回,收回;挽回
urllib.request.urlretrieve(url_page,'baidu.html')最终效果是:![]()
再试着爬一下其他网站
import urllib.request
# 下载网页
url = 'https://www.gdufemooc.cn'
urllib.request.urlretrieve(url=url,filename='GDUFE.html')下载图片
import urllib.request
# # 下载图片
url_img = 'https://ts1.cn.mm.bing.net/th/id/R-C.466ce8111047a7c906bf5b1d5bca6944?rik=mZhFbHSvePMGUw&riu=http%3a%2f%2fn.sinaimg.cn%2fsinacn20110%2f692%2fw961h1331%2f20190521%2fe80e-hxhyium7691752.jpg&ehk=ubkmmyFXp7mnQksDMD0gP1zV7gz78Mj4e7hyK%2fo54FA%3d&risl=&pid=ImgRaw&r=0'
urllib.request.urlretrieve(url=url_img,filename='klntl.jpg')效果:

import urllib.request
# 下载图片
url = 'https://tse4-mm.cn.bing.net/th/id/OIP-C.kEdDHuyWnIL6113QftvdVwHaEA?rs=1&pid=ImgDetMain'
urllib.request.urlretrieve(url=url,filename='cheems.jpg')
下载视频
import urllib.request
# 下载视频
url = 'https://vdept3.bdstatic.com/mda-nmgej5355w1up3f1/cae_h264/1671277763250403930/mda-nmgej5355w1up3f1.mp4?v_from_s=hkapp-haokan-hnb&auth_key=1720005910-0-0-50d0d69160c40203b3e38abb73dad9a1&bcevod_channel=searchbox_feed&cr=0&cd=0&pd=1&pt=3&logid=1510730062&vid=12613475349479718727&klogid=1510730062&abtest=101830_1-102148_2-17451_2'
urllib.request.urlretrieve(url=url,filename='cheems.mp4')
请求对象的定制-UA反爬
这个概念是比较抽象的.
我们之前写百度是写http://www.baidu.com
我们现在写https://baidu.com.他们有什么区别?
不就是多了个s嘛.但是确实是有很大区别的.我们先来看看url的组成
# url的组成
# http / https www.baidu.com 80/443 s wd = #
# 协议 主机 端口号 路径 参数 锚点
# http 80
# https 443
# mysql 3306
# oracle 1521
# redis 6379
# mogodb 27017
我们再次按照之前所学的方法写:
import urllib.request
url = 'https://www.baidu.com'
response = urllib.request.urlopen(url)
content = response.read().decode('utf-8')
print(content)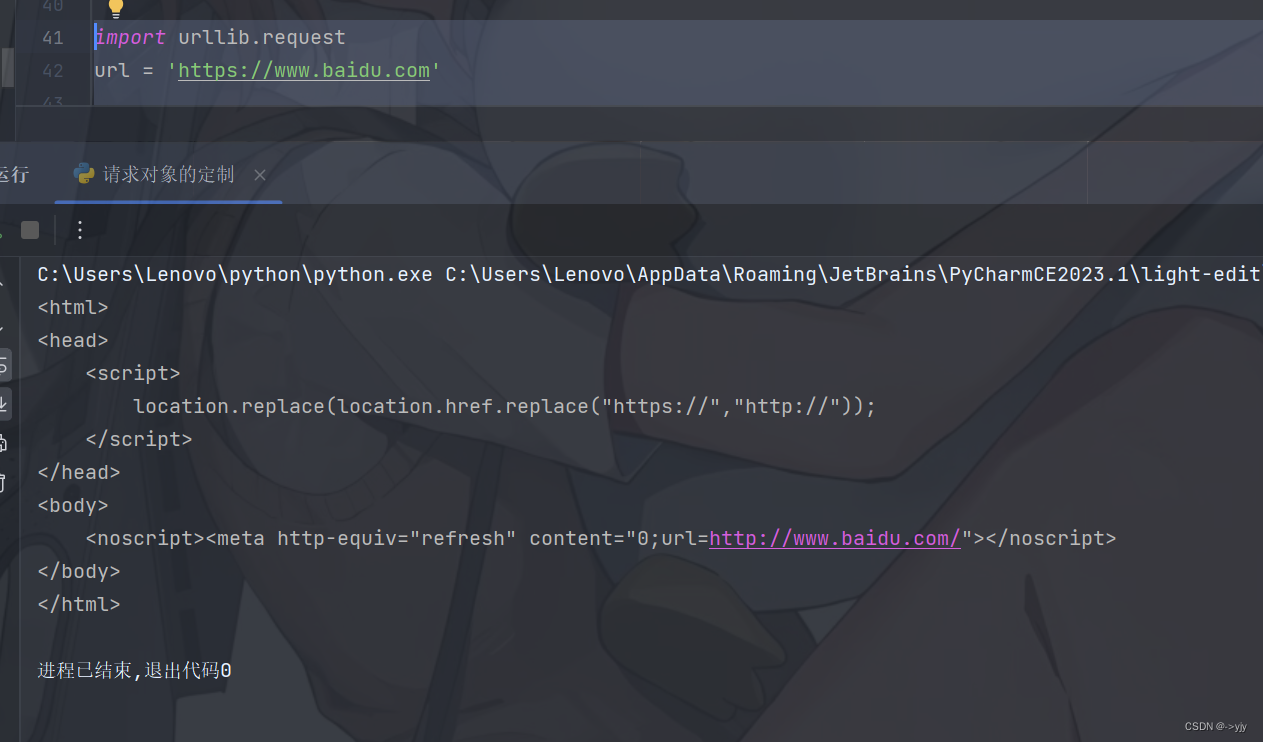
诶,怎么跟打印出来的数据那么少?
因为我们遇到了反爬
啥叫反爬?
这样一个故事或许可以帮助你理解: 张三喜欢一个女孩子,那么女孩子一看张三觉得长得不是他喜欢的款.也就是张三想爬取这个女孩子的信息,但她觉得张三长得胖胖的,她不喜欢,只说了一句:"你是个好人",然后并没有给他数据返回.也就是说张三在访问她的时候数据不够完整,白一点,瘦一点就好了嘛.张三就可以伪装一下自己,擦点粉底等.同等的,为什么我们这里获取的数据不完整,因为我们给它的数据不够完整不够优秀.这也是我们遇到的第一个反爬User Agent
UA介绍:User Agent 中文名为用户代理,简称UA,它是一恶搞特殊字符串头,使得服务器能够识别客户使用的操作系统及版本,CPU类型,浏览器及版本.浏览器内核,浏览器渲染,浏览器语言,浏览器插件等.
语法:request = urllib.request.Request()
你可能想问:UA在哪里呢???
UA无时无刻都在.你可以上浏览器搜索U大全.我们也可以按照以下操作来找到:
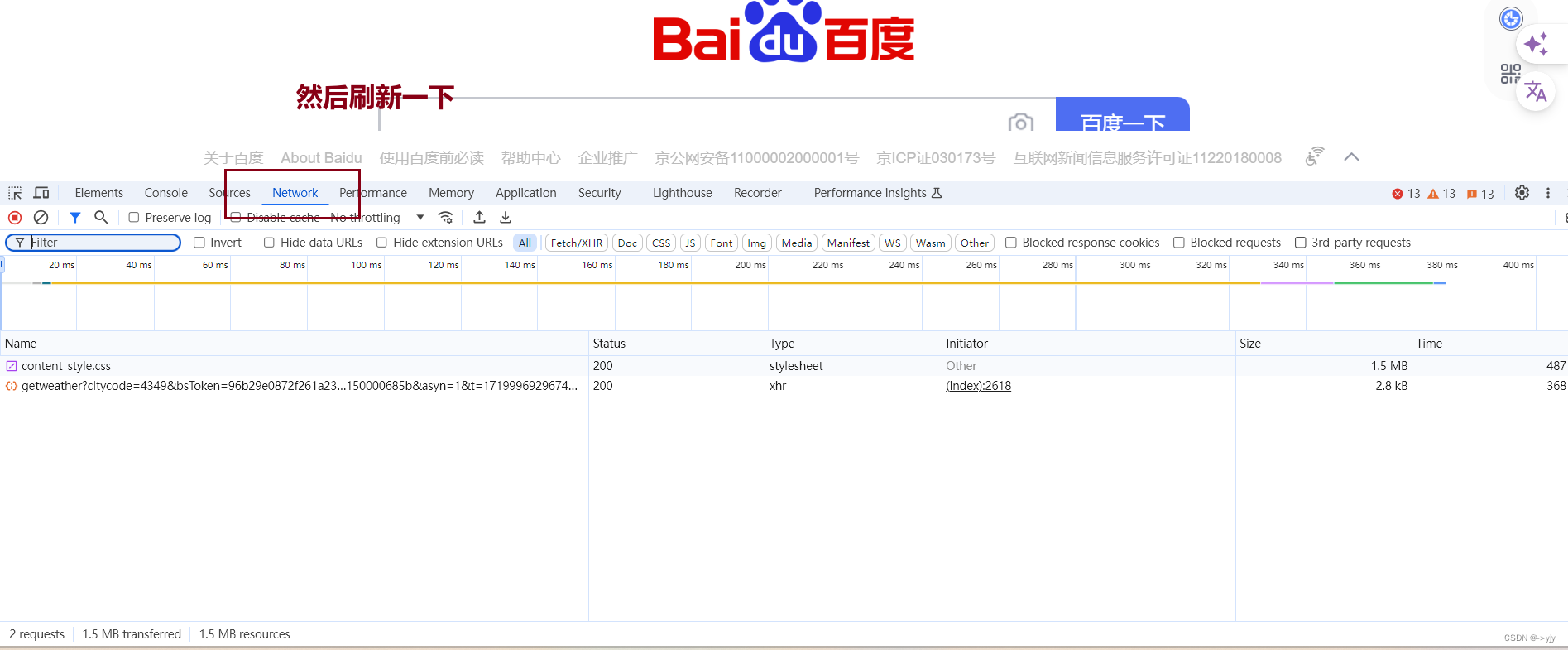
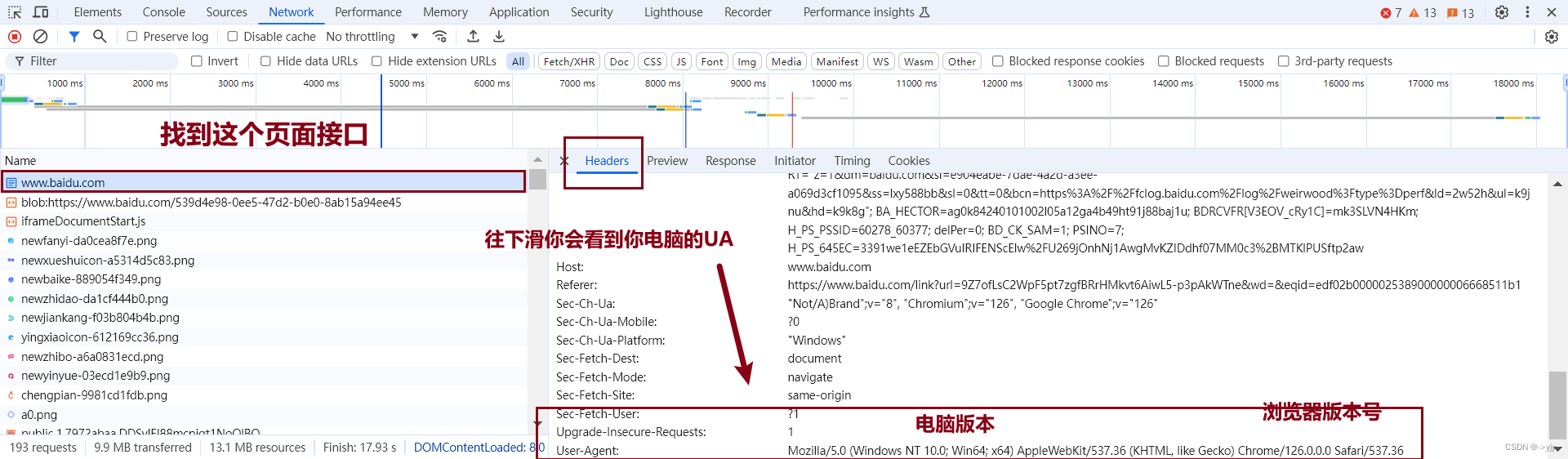
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36'
}
然后我直接在response那里面带上headers这样就可以吗?
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36'
}
response = urllib.request.urlopen(url,headers)这样会报错! 我们可以进去urlopen里面看看它的参数
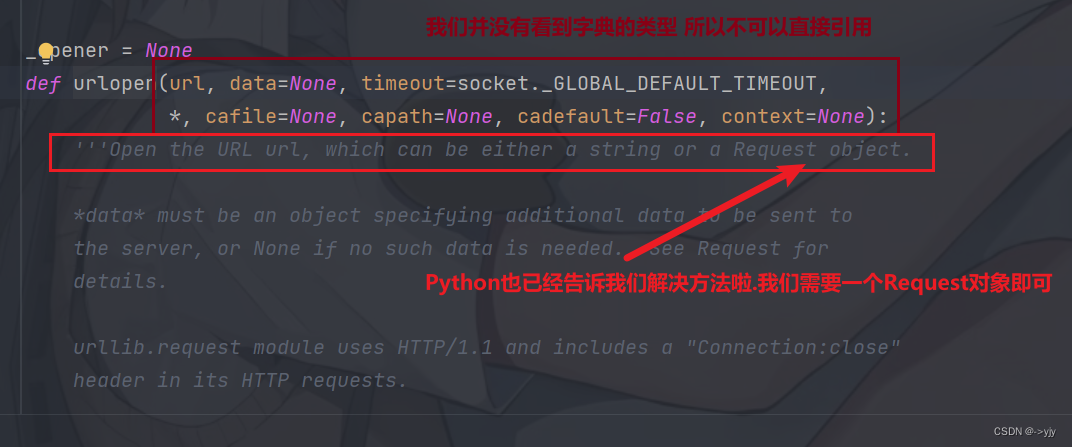
# # 遇到反爬
# """
# User-Agent:
# Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36
# """
#
import urllib.request
url = 'https://www.baidu.com'
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
}
# 因为urlopen 方法中不能存储字典,所以headers不能传递进去
# 请求对象的定制
# 注意 因为参数顺序的问题 不能直接写url和headers 中间还有data 所以我们需要关键字传参
request = urllib.request.Request(url = url,headers = headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf8')
print(content)
编解码
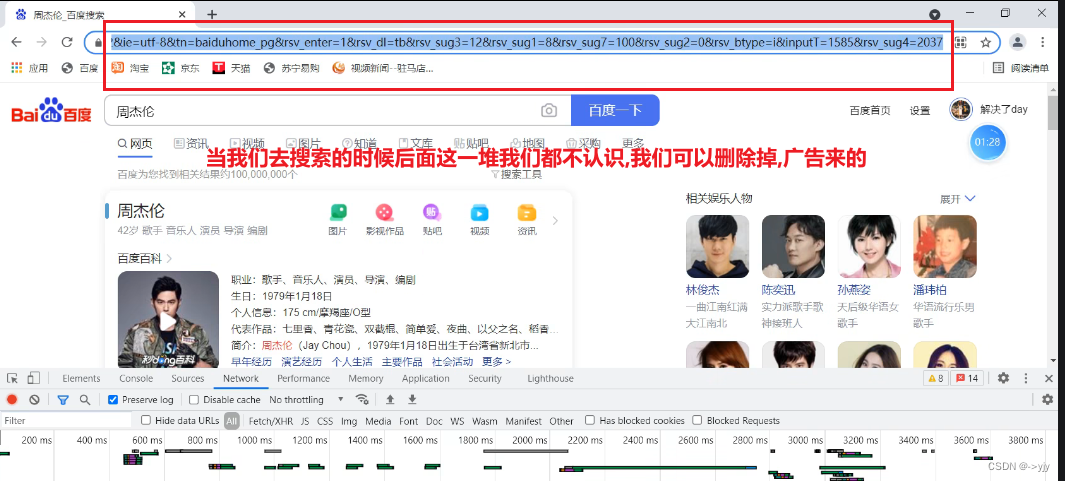
我们删除后访问该网址不受任何影响,当我们把这个网址https://www.baidu.com/s?wd = 周杰伦复制到pycharm中你会发现周杰伦三个字变成这样了
![]()
unicode编码
这就是编码集的演变
扩展:
'''编码集的演变‐‐‐
由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,
这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,
所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc‐kr里,
各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。
现代操作系统和大多数编程语言都直接支持Unicode。'''
1.get请求方式:urllib.parse.quote()
# https://www.baidu.com/s?tn=52176495_dg&ch=3&ie=utf-8&wd=%E5%91%A8%E6%9D%B0%E4%BC%A6
# 需求: 获取 https://www.baidu.com/s?wd = 周杰伦的网页源码
#
import urllib.request
import urllib.parse
url = 'https://www.baidu.com/s?wd='
# 请求对象的定制为了解决反爬的第一种手段
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
}
# 模拟浏览器向服务器发送请求
# request = urllib.request.Request(url=url,headers = headers)
# 将周杰伦三个字变成unicode 编码的格式
# 我们需要依赖于urllib.parse 要导入
# quote 将汉字变为unicode编码
name = urllib.parse.quote('周杰伦')
# 可以给任何名字
# print(name)
url = url +name
# print(url)
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应耳朵内容
content =response.read().decode('utf-8')
# 打印数据
print(content)
import urllib.request
import urllib.parse
url = 'https://www.baidu.com/s?wd='
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
}
url = url + urllib.parse.quote('小野')
request = urllib.request.Request(url = url,headers=headers)
response = urllib.request.urlopen(request)
print(request.read().decode('utf-8'))2.get请求方式:urllib.parse.urlencode()
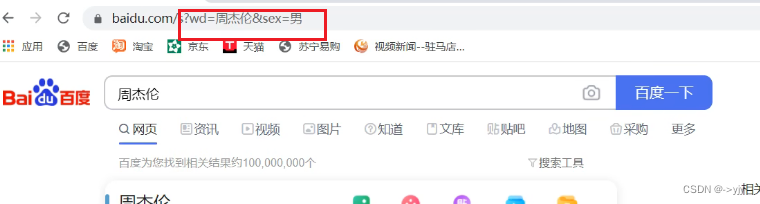
适用多个参数
"""
作者:->yjy
所有的惊艳都曾历经平庸
"""
# urlencode应用场景:多个参数的时候 也就是网站后&一个参数&一个参数....
# import urllib.parse
#
# data = {
# 'wd' : '周杰伦',
# 'sex':'男',
# 'location' : '中国台湾省'
# }
# a = urllib.parse.urlencode(data)
# print(a)
# 获取https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6&sex=%E7%94%B7&location%20=%20%E4%B8%AD%E5%9B%BD%E5%8F%B0%E6%B9%BE%E7%9C%81 网页源码
import urllib.request
import urllib.parse
base_url = 'https://www.baidu.com/s?'
data = {
'wd' : '周杰伦',
'sex' : '男',
'location':'中国台湾省'
}
new_data = urllib.parse.urlencode(data)
print(new_data)
# 请求资源路径
url = base_url+new_data
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
}
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取网页源码的数据
content = response.read().decode('utf-8')
# 打印数据
print(content)3.post请求方式
# post请求
import urllib.request
import urllib.parse
url = 'https://fanyi.baidu.com/sug'
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
}
data = {
'kw' : 'spider'
}
# post请求的参数 必须要进行编码
data = urllib.parse.urlencode(data).encode('utf-8')
# print(data)
# post的请求的参数 是不会拼接在url的后面的 而是需要放在请求参数定制的参数中
# post请求的参数,必须要进行编码
request = urllib.request.Request(url=url,data=data,headers = headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
# print(response)
content = response.read().decode('utf-8')
# print(content)
# 字符串->json对象
import json
obj = json.loads(content)
print(obj)
# post请求方式的参数 必须编码 data = urllib.parse.urlencode(data).encode('utf-8')
# 编码之后 必须调用encode方法 data=urllib.parse.urlencode(data).encode('utf-8')
# 参数是放在请求定制的方法中 request = urllib.request.Request(url=url,data=data,headers = headers)eg:百度翻译
import urllib.request
import urllib.parse
url = 'https://fanyi.baidu.com/sug'
headers = {
'user‐agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like
Gecko) Chrome/74.0.3729.169 Safari/537.36'
}
keyword = input('请输入您要查询的单词')
data = {
'kw':keyword
}
data = urllib.parse.urlencode(data).encode('utf‐8')
request = urllib.request.Request(url=url,headers=headers,data=data)
response = urllib.request.urlopen(request)
print(response.read().decode('utf‐8'))总结:post和get区别?
1:get请求方式的参数必须编码,参数是拼接到url后面,编码之后不需要调用encode方法
2:post请求方式的参数必须编码,参数是放在请求对象定制的方法中,编码之后需要调用encode方法
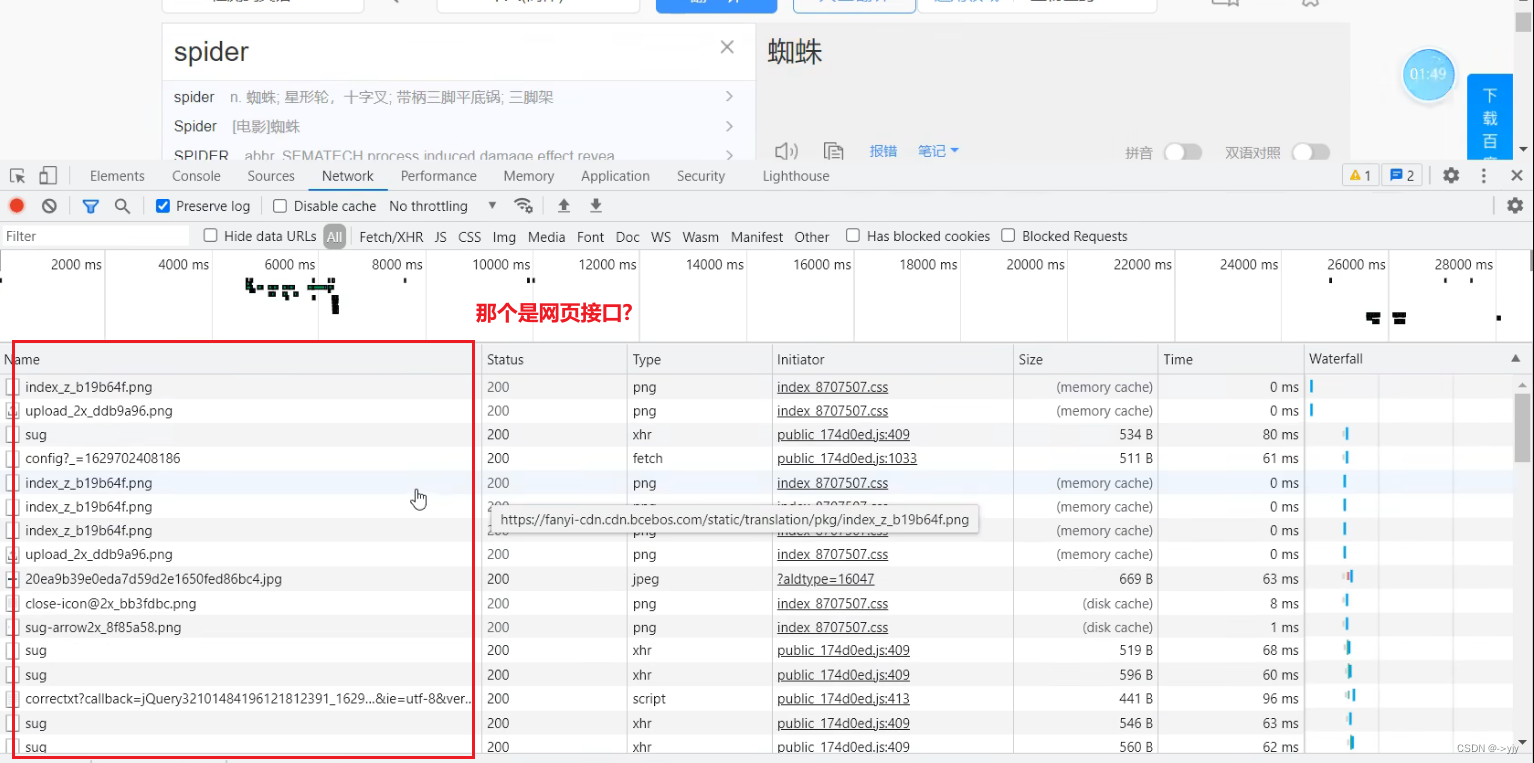
kw:keyword关键字
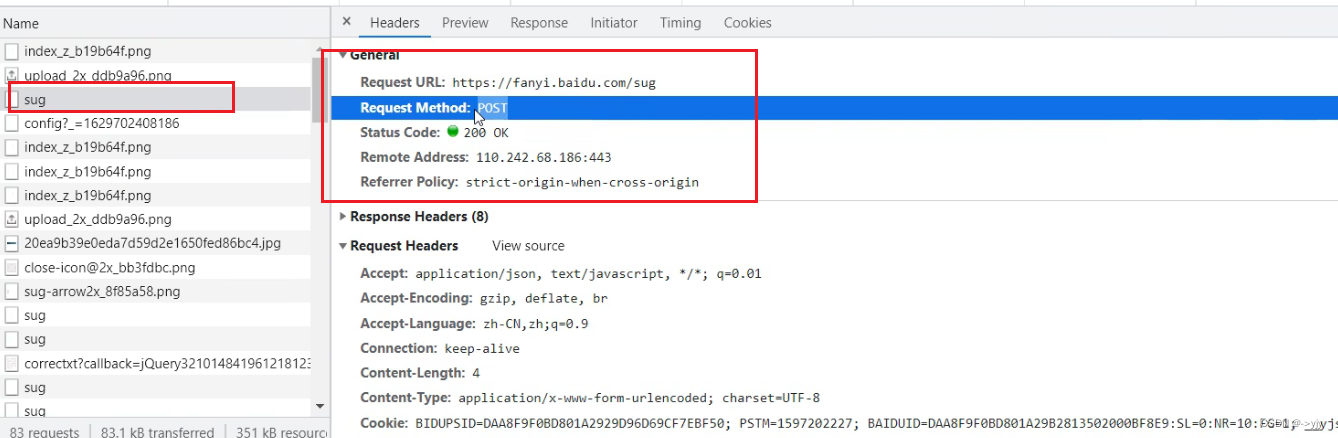
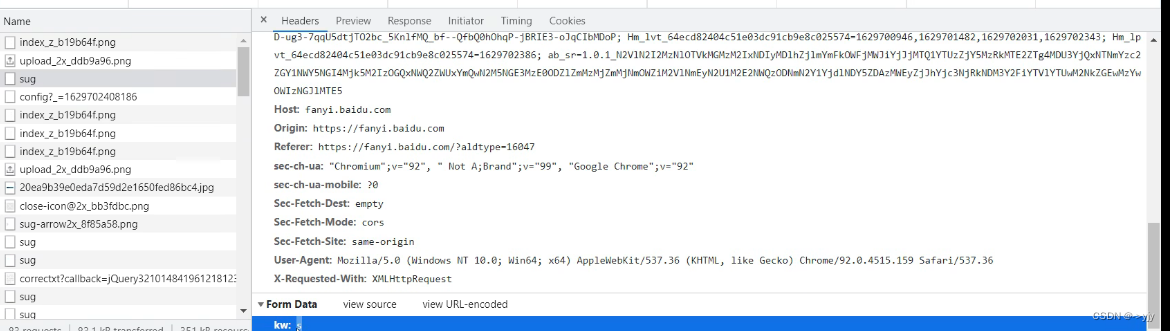
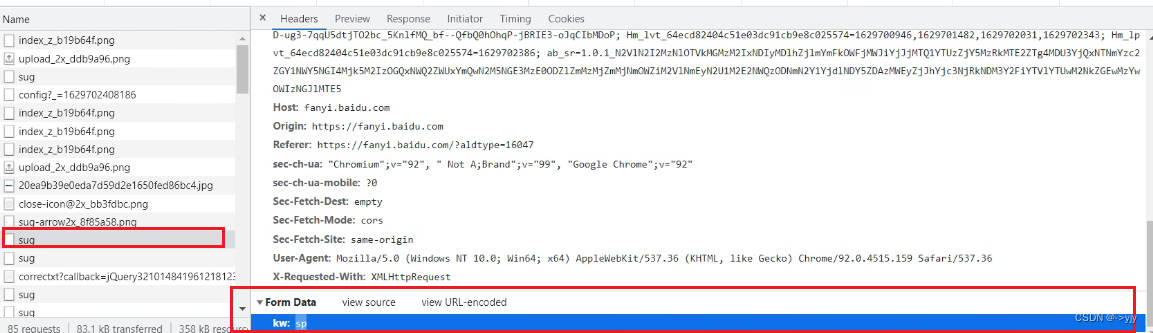
案例练习:百度详细翻译




import urllib.request
import urllib.parse
url = 'https://fanyi-api.baidu.com/api/trans/activity/conf?callback=bdTransJP1'
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
}
data = {
'from':'en',
'to':'zh',
'query':'love',
'transtype':'realtime',
'simple_means_flag':'3',
'sign':'198772.518981',
'token':'5483bfa6529b419c90d91f3de875d',
'domian':'common',
}
# post请求的参数 必须进行编码 并且要调用encode方法
data = urllib.parse.urlencode(data).encode('utf-8')
# 请求对象的定制
request = urllib.request.Request(url=url,data=data,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
print(content)
import json
obj = json.loads(content)
print(obj)写这段代码发现它获取的数据并不完整
你喜欢一个女生,你有的跟她想要的不一样,人家当然拒绝你啦.但是如果你什么都有,要颜值有颜值,要身材有身材,要体贴有体贴.那她就会接受你啦~


但是这样也会出错,必须把Accept-Encoding注释掉

但其实你追女孩子是有一个核心的点最能打动她,她才喜欢你,其他的只不过是锦上添花

这里有一个反爬:Cookie
把这个写上去就可以啦~
ajax的get请求
豆瓣电影第一页
先用抓包工具抓取接口

它之所以给你json数据,是基于前后端分离
import urllib.request
# get 请求
# 获取豆瓣电影的第一页的数据 并保存起来
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20'
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
}
# (1) 请求对象的定制
request = urllib.request.Request(url=url,headers = headers)
# (2) 获取响应的数据
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# print(content)
# (3) 数据下载到本地
# open 方法默认情况下使用的是gbk的编码 如果我们想要保存汉字 ,那么需要再open方法中指定编码格式为utf-8
# encoding = 'utf-8'
# fp = open('douban.json','w',encoding='utf-8')
# fp.write(content)
with open('douban1.json','w',encoding='utf-8') as fp:
fp.write(content)
豆瓣电影前十页

当你往下滑的时候它都在加载,而这个操作后端的底层实现就是ajax 异步加载
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20
# 后面很多页后端的底层实现是ajax
# 每一页的规律:
# page 1 2 3 4
# start 0 20 40 60
# start (page-1)*20
# 下载豆瓣电影前10页的数据
# (1)请求对象的定制
# (2)获取响应的数据
# (3)下载数据
import urllib.parse
import urllib.request
def create_request(page):
base_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'
data = {
'start':(page-1)*20,
'limit':20
}
data = urllib.parse.urlencode(data)
url = base_url+data
print(url)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
}
request = urllib.request.Request(url=url,headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page,content):
with open('douban'+str(page) + '.json','w',encoding='utf-8') as fp:
fp.write(content)
# 程序的入口
if __name__ == '__main__':
start_page = int(input('请输入起始的页码:'))
end_page = int(input('请输入结束的页码:'))
for page in range(start_page,end_page+1):
# print(page)
# 每一页都有自己的请求对象的定制
request = create_request(page)
# 获取响应的数据
content = get_content(request)
# 下载
down_load(page,content)ajax的post请求
案例:KFC官网
# 2页
# https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# post
# cname: 北京
# pid:
# pageIndex: 2
# pageSize: 10
import urllib.request
import urllib.parse
# 请求对象定制 Post
def create_request(page):
base_url= 'https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {
'cname': '北京',
' pid': '',
'pageIndex': page,
' pageSize': '10'
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
}
request = urllib.request.Request(url=base_url,headers=headers,data = data)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page,content):
with open('kfc_'+str(page)+'.json','w',encoding='utf-8')as fp:
fp.write(content)
if __name__ == '__main__':
start_page = int(input('请输入起始页码:'))
end_page = int(input('请输入结束页码:'))
for page in range(start_page,end_page+1):
# print(page)
# 请求对象的定制
request=create_request(page)
# 获取网页源码
content = get_content(request)
# 下载
down_load(page,content)
URLError\HTTPError
简介:1.HTTPError类是URLError类的子类
2.导入的包urllib.error.HTTPError urllib.error.URLError
3.http错误:http错误是针对浏览器无法连接到服务器而增加出来的错误提示。引导并告诉浏览者该页是哪里出
了问题。
4.通过urllib发送请求的时候,有可能会发送失败,这个时候如果想让你的代码更加的健壮,可以通过try‐
except进行捕获异常,异常有两类,URLError\HTTPError
import urllib.request
import urllib.error
url = 'https://blog.csdn.net/2301_79602614/article/details/140010382'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
}
try:
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
except urllib.error.HTTPError:
print('系统正在升级...')
except urllib.error.URLError:
print('我都说啦,系统在升级捏~')cookie登录
使用案例:
1.weibo登陆
作业:qq空间的爬取
# 适用场景:数据采集的时候 需要绕过登录 然后进入到某个界面
# 如果我们将来要采集一些数据 但是这些数据必须是你登录之后才能看到的数据
# 这种问题如何做数据采集呢?

这个页面正常访问能访问到吗?
import urllib.request
url = 'https://weibo.cn/7868687/info'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
}
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
# 将数据保存到本地
with open('weibo.html','w',encoding='utf-8')as fp:
fp.write(content)
# 问题: 又是一个新的反爬手段
# 个人信息页面是utf-8 但是还报错了编码错误 因为并没有进入个人信息页面
# 而是跳转到了登录页面 登录页面不是utf-8 所以报错
# 解决:我们可以看登录界面的源码 发现用的是编码是:gb2312 将上面的utf-8改为GB312即可
# 如何绕过?
# 什么情况下访问不成功?
# 因为请求头的信息不够
# cookie中携带着你的登录信息 如果有登录之后的cookie 那么我们就可以携带着cookie进入到任何页面
# referer 判断当前路径是不是由上一个路径进来的 一般情况下 是做图片防盗链

qq空间爬取:
Handler处理器
为什么要学习handler?
urllib.request.urlopen(url)
不能定制请求头
urllib.request.Request(url,headers,data)
可以定制请求头
Handler
定制更高级的请求头(随着业务逻辑的复杂 请求对象的定制已经满足不了我们的需求(动态cookie和代理
不能使用请求对象的定制)
# 需求 使用handler来访问百度 获取网页源码
import urllib.request
url = 'http://www.baidu.com'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
}
request = urllib.request.Request(url=url,headers=headers)
# handler build_opener open
# (1)获取handler对象
handler = urllib.request.HTTPHandler()
# (2)获取opener对象
opener = urllib.request.build_opener(handler)
# (3)调用open方法
response = opener.open(request)
content = response.read().decode('utf-8')
print(content)
eg:
import urllib.request
url = 'http://www.baidu.com'
headers = {
'User ‐ Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML,
likeGecko) Chrome / 74.0.3729.169Safari / 537.36'
}
request = urllib.request.Request(url=url,headers=headers)
handler = urllib.request.HTTPHandler()
opener = urllib.request.build_opener(handler)
response = opener.open(request)
print(response.read().decode('utf‐8'))代理服务器
1.代理的常用功能?
1.突破自身IP访问限制,访问国外站点。
2.访问一些单位或团体内部资源
扩展:某大学FTP(前提是该代理地址在该资源的允许访问范围之内),使用教育网内地址段免费代理服务
器,就可以用于对教育网开放的各类FTP下载上传,以及各类资料查询共享等服务。
3.提高访问速度
扩展:通常代理服务器都设置一个较大的硬盘缓冲区,当有外界的信息通过时,同时也将其保存到缓冲
区中,当其他用户再访问相同的信息时, 则直接由缓冲区中取出信息,传给用户,以提高访问速度。
4.隐藏真实IP
扩展:上网者也可以通过这种方法隐藏自己的IP,免受攻击。
2.代码配置代理
创建Reuqest对象
创建ProxyHandler对象
用handler对象创建opener对象
使用opener.open函数发送请求
查询当前ip 可以直接在浏览器中搜索ip 得到
import urllib.request
url = 'https://www.baidu.com/s?tn=15007414_15_dg&ie=utf-8&wd=ip'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
}
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器访问服务器
# response = urllib.request.urlopen(request)
proxies = {
'http':'218.87.205.30:20078'
}
# handle build_opener open
handler = urllib.request.ProxyHandler(proxies=proxies)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
# 获取响应的信息
content = response.read().decode('utf-8')
# 保存本地
with open('daili.html','w',encoding='utf-8') as fp:
fp.write(content)
# print(content)
# 代理池 高密ip
eg:
import urllib.request
url = 'http://www.baidu.com/s?wd=ip'
headers = {
'User ‐ Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML,
likeGecko) Chrome / 74.0.3729.169Safari / 537.36'
}
request = urllib.request.Request(url=url,headers=headers)
proxies = {'http':'117.141.155.244:53281'}
handler = urllib.request.ProxyHandler(proxies=proxies)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
content = response.read().decode('utf‐8')
with open('daili.html','w',encoding='utf‐8')as fp:
fp.write(content)扩展:1.代理池
proxies_pool = [
# 放真实的代理
{'http':'218.87.205.30:20078'},
{'http':'218.87.205.30:20028'},
]
import random
proxies = random.choice(proxies_pool)
print(proxies)
2.快代理
直接上浏览器查找
















 2132
2132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









