






机器学习 — 特征工程(二)
文章目录
六,无量纲化- 预处理
无量纲,即没有单位的数据
无量纲化包括"归一化"和"标准化", 为什么要进行无量纲化呢?
这是一个男士的数据表:
| 编号id | 身高 h | 收入 s | 体重 w |
|---|---|---|---|
| 1 | 1.75(米) | 15000(元) | 120(斤) |
| 2 | 1.5(米) | 16000(元) | 140(斤) |
| 3 | 1.6(米) | 20000(元) | 100(斤) |
假设算法中需要求它们之间的欧式距离, 这里以编号1和编号2为示例:
L = ( 1.75 − 1.5 ) 2 + ( 15000 − 16000 ) 2 + ( 120 − 140 ) 2 L = \sqrt{(1.75-1.5)^2+(15000-16000)^2+(120-140)^2} L=(1.75−1.5)2+(15000−16000)2+(120−140)2
从计算上来看, 发现身高对计算结果没有什么影响, 基本主要由收入来决定了,但是现实生活中,身高是比较重要的判断标准. 所以需要无量纲化.
6.1 MinMaxScaler 归一化
通过对原始数据进行变换把数据映射到指定区间(默认为0-1)
- <1>归一化公式:
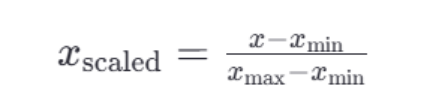
这里的 𝑥min 和 𝑥max 分别是每种特征中的最小值和最大值,而 𝑥是当前特征值,𝑥scaled 是归一化后的特征值。
若要缩放到其他区间,可以使用公式:x=x*(max-min)+min;
- <2>归一化API
sklearn.preprocessing.MinMaxScaler(feature_range)
- <2>归一化示例
from sklearn.preprocessing import MinMaxScaler
x=[[100,20,],
[200,21,],
[150,28,]]
tool=MinMaxScaler()
x_new=tool.fit_transform(x)
print(x_new)
[[0. 0. ]
[1. 0.125]
[0.5 1. ]]
- <4>缺点
最大值和最小值容易受到异常点影响,所以鲁棒性较差。所以常使用标准化的无量钢化
6.2 normalize归一化
API
from sklearn.preprocessing import normalize
normalize(data, norm='l2', axis=1)
#data是要归一化的数据
#norm是使用那种归一化:"l1" "l2" "max
#axis=0是列 axis=1是行
6.1.1 L1归一化
from sklearn.preprocessing import normalize
x=[[100,20,],
[200,21,],
[150,28,]]
x =normalize(x,norm='l1')
print(x)
[[0.83333333 0.16666667]
[0.90497738 0.09502262]
[0.84269663 0.15730337]]
6.1.2 L2归一化
#L2归一化
from sklearn.preprocessing import normalize
x=[[100,20,],
[200,21,],
[150,28,]]
x =normalize(x,norm='l2')
#L2归一化
from sklearn.preprocessing import normalize
x=[[100,20,],
[200,21,],
[150,28,]]
x =normalize(x,norm='l2')
print(x)
6.1.3 max归一化
from sklearn.preprocessing import normalize
x=[[100,20,],
[200,21,],
[150,28,]]
x=normalize(x,norm="max",axis=0)
print(x)
[[0.5 0.71428571]
[1. 0.75 ]
[0.75 1. ]]
6.3 StandardScaler 标准化
在机器学习中,标准化是一种数据预处理技术,也称为数据归一化或特征缩放。它的目的是将不同特征的数值范围缩放到统一的标准范围,以便更好地适应一些机器学习算法,特别是那些对输入数据的尺度敏感的算法。
- <1>标准化公式
最常见的标准化方法是Z-score标准化,也称为零均值标准化。它通过对每个特征的值减去其均值,再除以其标准差,将数据转换为均值为0,标准差为1的分布。这可以通过以下公式计算:
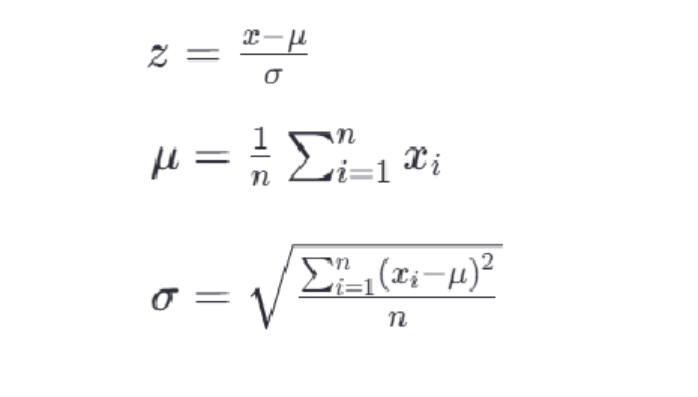
- <2> 标准化 API
sklearn.preprocessing.StandardScale
与MinMaxScaler一样,原始数据类型可以是list、DataFrame和ndarray
fit_transform函数的返回值为ndarray, 归一化后得到的数据类型都是ndarray
- <3>标准化示例
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
# 1、获取数据
df_data = pd.read_csv("src/dating.txt")
print(type(df_data)) #<class 'pandas.core.frame.DataFrame'>
print(df_data.shape)
# 2、实例化一个转换器类
transfer = StandardScaler()
# 3、调用fit_transform
new_data = transfer.fit_transform(df_data)
print("DateFrame数据被归一化后:\n", new_data[0:5])
nd_data = df_data.values #把DateFrame转为ndarray
new_data = transfer.fit_transform(nd_data)
print("ndarray数据被归一化后:\n", new_data[0:5])
nd_data = df_data.values.tolist() #把DateFrame转为list
new_data = transfer.fit_transform(nd_data) #把ndarray数据进行归一化
print("list数据被归一化后:\n", new_data[0:5])
<class 'pandas.core.frame.DataFrame'>
(1000, 4)
DateFrame数据被归一化后:
[[ 0.33193158 0.41660188 0.24523407 1.24115502]
[-0.87247784 0.13992897 1.69385734 0.01834219]
[-0.34554872 -1.20667094 -0.05422437 -1.20447063]
[ 1.89102937 1.55309196 -0.81110001 -1.20447063]
[ 0.2145527 -1.15293589 -1.40400471 -1.20447063]]
ndarray数据被归一化后:
[[ 0.33193158 0.41660188 0.24523407 1.24115502]
[-0.87247784 0.13992897 1.69385734 0.01834219]
[-0.34554872 -1.20667094 -0.05422437 -1.20447063]
[ 1.89102937 1.55309196 -0.81110001 -1.20447063]
[ 0.2145527 -1.15293589 -1.40400471 -1.20447063]]
list数据被归一化后:
[[ 0.33193158 0.41660188 0.24523407 1.24115502]
[-0.87247784 0.13992897 1.69385734 0.01834219]
[-0.34554872 -1.20667094 -0.05422437 -1.20447063]
[ 1.89102937 1.55309196 -0.81110001 -1.20447063]
[ 0.2145527 -1.15293589 -1.40400471 -1.20447063]]
- <4> 注意点
在数据预处理中,特别是使用如StandardScaler这样的数据转换器时,fit、fit_transform和transform这三个方法的使用是至关重要的,它们各自有不同的作用:
- fit:
- 这个方法用来计算数据的统计信息,比如均值和标准差(在
StandardScaler的情况下)。这些统计信息随后会被用于数据的标准化。 - 你应当仅在训练集上使用
fit方法。
- 这个方法用来计算数据的统计信息,比如均值和标准差(在
- fit_transform:
- 这个方法相当于先调用
fit再调用transform,但是它在内部执行得更高效。 - 它同样应当仅在训练集上使用,它会计算训练集的统计信息并立即应用到该训练集上。
- 这个方法相当于先调用
- transform:
- 这个方法使用已经通过
fit方法计算出的统计信息来转换数据。 - 它可以应用于任何数据集,包括训练集、验证集或测试集,但是应用时使用的统计信息必须来自于训练集。
- 这个方法使用已经通过
七,特征降维
特征降维其目的:是减少数据集的维度,同时尽可能保留数据的重要信息。
特征降维的好处:
减少计算成本:在高维空间中处理数据可能非常耗时且计算密集。降维可以简化模型,降低训练时间和资源需求。
去除噪声:高维数据可能包含许多无关或冗余特征,这些特征可能引入噪声并导致过拟合。降维可以帮助去除这些不必要的特征。
特征降维的方式:
- 特征选择
- 从原始特征集中挑选出最相关的特征
- 主成份分析(PCA)
- 主成分分析就是把之前的特征通过一系列数学计算,形成新的特征,新的特征数量会小于之前特征数量
7.1 .特征选择
VarianceThreshold 低方差过滤特征选择
-
Filter(过滤式): 主要探究特征本身特点, 特征与特征、特征与目标 值之间关联
-
方差选择法: 低方差特征过滤
如果一个特征的方差很小,说明这个特征的值在样本中几乎相同或变化不大,包含的信息量很少,模型很难通过该特征区分不同的对象,比如区分甜瓜子和咸瓜子还是蒜香瓜子,如果有一个特征是长度,这个特征相差不大可以去掉。
- 计算方差:对于每个特征,计算其在训练集中的方差(每个样本值与均值之差的平方,在求平均)。
- 设定阈值:选择一个方差阈值,任何低于这个阈值的特征都将被视为低方差特征。
- 过滤特征:移除所有方差低于设定阈值的特征
-
from sklearn.feature_selection import VarianceThreshold
tool = VarianceThreshold(threshold=1.5)
x = [[0, 2, 0, 3],
[0, 7, 4, 3],
[0, 1, 1, 3]]
print(tool.fit_transform(x))
[[2 0]
[7 4]
[1 1]]
7.2 根据相关系数的特征选择
皮尔逊相关系数(Pearson correlation coefficient)是一种度量两个变量之间线性相关性的统计量。它提供了两个变量间关系的方向(正相关或负相关)和强度的信息。皮尔逊相关系数的取值范围是 [−1,1],其中:
- ρ = 1 \rho=1 ρ=1 表示完全正相关,即随着一个变量的增加,另一个变量也线性增加。
- ρ = − 1 \rho=-1 ρ=−1 表示完全负相关,即随着一个变量的增加,另一个变量线性减少。
- ρ = 0 \rho=0 ρ=0 表示两个变量之间不存在线性关系。
相关系数 ρ \rho ρ的绝对值为0-1之间,绝对值越大,表示越相关,当两特征完全相关时,两特征的值表示的向量是
在同一条直线上,当两特征的相关系数绝对值很小时,两特征值表示的向量接近在同一条直线上。当相关系值为负数时,表示负相关
from scipy.stats import pearsonr
print(pearsonr([1,2,3,4,5],
[5,4,3,2,1]))
PearsonRResult(statistic=-1.0, pvalue=0.0)
7.3主成份分析(PCA)
PCA的核心目标是从原始特征空间中找到一个新的坐标系统,使得数据在新坐标轴上的投影能够最大程度地保留数据的方差,同时减少数据的维度。
PCA的核心目标是从原始特征空间中找到一个新的坐标系统,使得数据在新坐标轴上的投影能够最大程度地保留数据的方差,同时减少数据的维度。
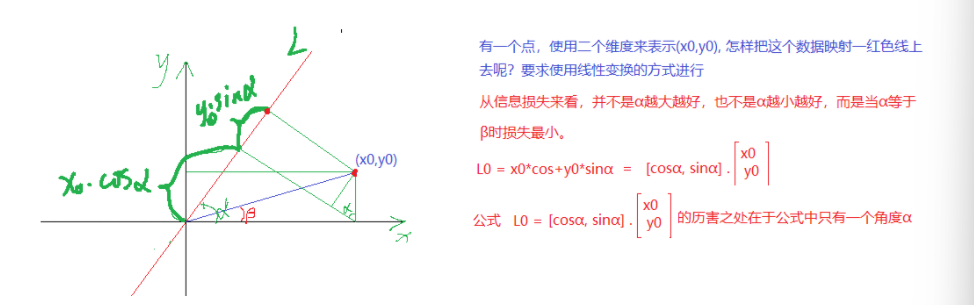
x
0
x_0
x0投影到L的大小为
x
0
∗
c
o
s
α
x_0*cos \alpha
x0∗cosα
y 0 y_0 y0投影到L的大小为 y 0 ∗ s i n α y_0*sin\alpha y0∗sinα
然后降维保留主成分
from sklearn.decomposition import PCA
data = [[12,82,41,51],
[15,13,10,58],
[15,41,90,14]]
pca = PCA(n_components=0.5)
data_pca = pca.fit_transform(data)
print(data_pca)
[[ 2.17858777]
[-48.82047898]
[ 46.64189122]]
7.4 鸢尾花案例
# 案例 鸢尾花特征降维
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
x,y = load_iris(return_X_y=True)
pca = PCA(n_components=0.95)
x=pca.fit_transform(x)
print(x.shape)
print(x)
(150, 2)
[[-2.68412563 0.31939725]
[-2.71414169 -0.17700123]
[-2.88899057 -0.14494943]
[-2.74534286 -0.31829898]
[-2.72871654 0.32675451]
[-2.28085963 0.74133045]
[-2.82053775 -0.08946138]
[-2.62614497 0.16338496]
[-2.88638273 -0.57831175]
[-2.6727558 -0.11377425]
[-2.50694709 0.6450689 ]
[-2.61275523 0.01472994]
[-2.78610927 -0.235112 ]
[-3.22380374 -0.51139459]
[-2.64475039 1.17876464]
[-2.38603903 1.33806233]
[-2.62352788 0.81067951]
[-2.64829671 0.31184914]
[-2.19982032 0.87283904]
[-2.5879864 0.51356031]
[-2.31025622 0.39134594]
[-2.54370523 0.43299606]
[-3.21593942 0.13346807]
[-2.30273318 0.09870885]
...
[ 1.52716661 -0.37531698]
[ 1.76434572 0.07885885]
[ 1.90094161 0.11662796]
[ 1.39018886 -0.28266094]]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









