







引言
随着ai对我们生活的影响越来越深,使用ai来便利我们的生活也变得越来越常见。其中,ai声音作为应用技术比较成熟,使用门槛比较低的技术,值得大家花一点时间学习使用。
q:我学会这个能干什么?
a:可以自定声音模型,接入unity游戏中和chat实现对话等,也可以在做视频等时提供方便的免费配音,也可以自娱自乐搞二次元老婆。
模型介绍
gpt-sovits是一个相对而言体量较小,具备完整的图形化ui,学习门槛极低的模型,只需要约5分钟的声音原始数据,就可以获得效果不错的训练结果,训练过程很快,等待时间少,不容易出错。
模型下载:
由于模型需要和自己的显卡型号匹配,且版本众多,因此本教程不提供模型的下载,可以去百度贴吧或bilibili等寻找合适的模型。
使用UVR5进行降噪处理
下载原始素材
在训练之前,我们需要先准备好一定的原始素材,常见的声音格式都可以。这里我以明日方舟wiki上下载的声音集作为展示。把下载好的声音放在新建文件夹里,这个文件夹就是我们训练每一个步骤的结果集,因此每一个步骤都需要设置一个文件夹来区分。
原始素材需要单独放一个文件夹:
这样就算下载好了。
使用uvr5模型进行背景音乐分离、去混响处理
打开gpt-sovits模型的文件夹,找到go-webui.bat这个文件,打开。唤出终端后会稍微卡一段时间,然后ui界面就会出现在你的浏览器里。
一旦打开web界面,就绝对不能关闭终端,接下来的整个流程都需要保证你的终端是挂在后台的!
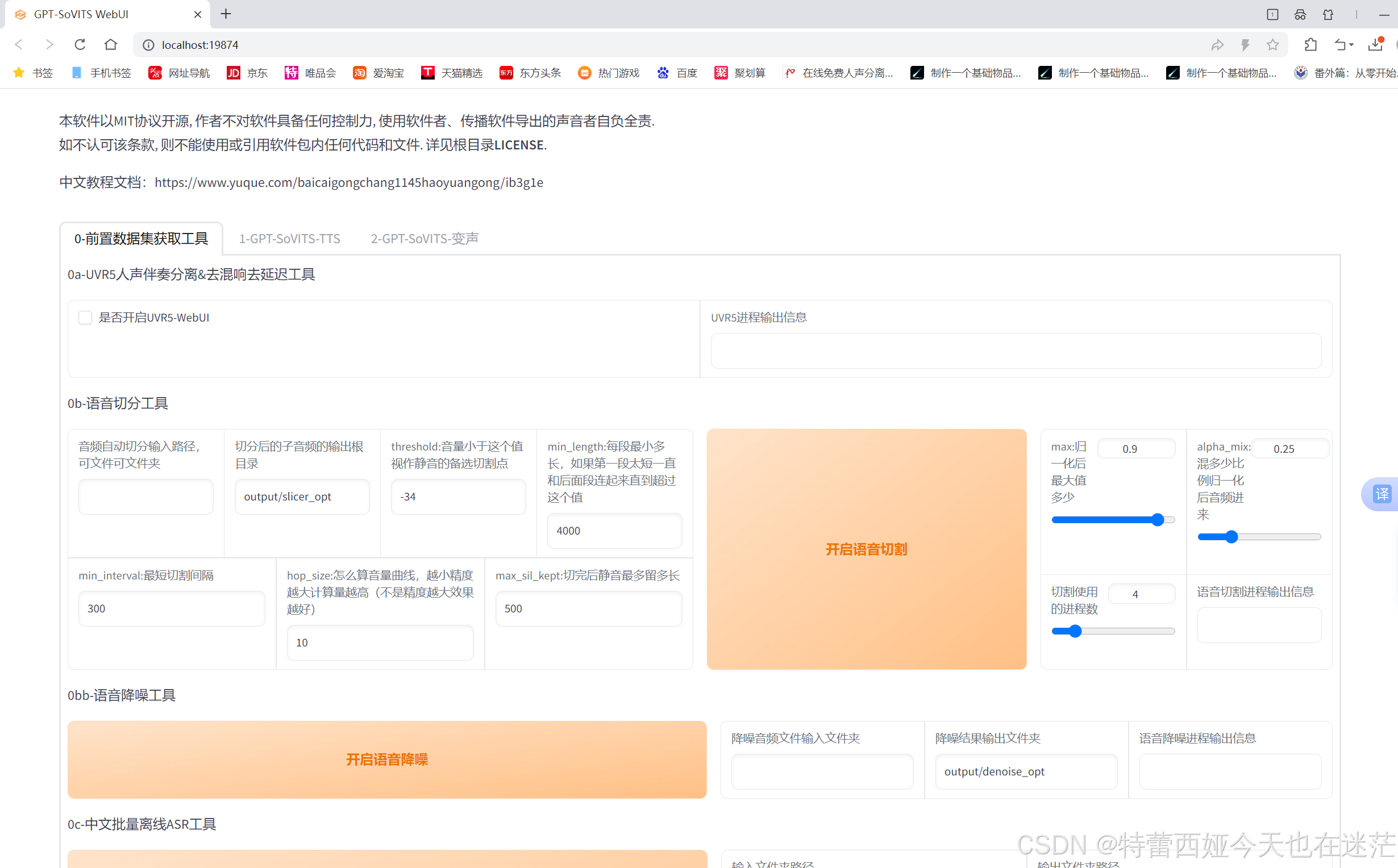
我们的前置工作还没有做完。虽然我在wiki下载的声音很纯净,但如果你用的是录音机或是其他方式&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3176
3176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









