




 本文介绍了Spark中的核心概念——弹性分布式数据集(RDD),包括其创建、操作、并行化和持久化。重点讲解了RDD的transformations和actions,以及Spark的函数式编程风格,涉及匿名函数和Accumulator。同时讨论了Shuffle操作在WordCount中的应用。
本文介绍了Spark中的核心概念——弹性分布式数据集(RDD),包括其创建、操作、并行化和持久化。重点讲解了RDD的transformations和actions,以及Spark的函数式编程风格,涉及匿名函数和Accumulator。同时讨论了Shuffle操作在WordCount中的应用。
概述
spark 提供的重要的抽象是一个 弹性分布式数据集(RDD) ,能被并行操作的,在集群上分区的集合元素。RDDs 可以通过 hadoop 文件(或共它的 hadoop 支持的文件系统),或者编程中的 scala 集合,转换它创建 RDD。用户还可以要求 spark 将 RDD 保存在内存中,以便在并行操作中高效的重用;最后 RDDs 会自动的从节点故障中恢复。
第二个抽象是spark中的共享变量,默认的,当 spark 在不同节点上作为一组并行运行一个函数时,它会将函数中使用的每个变量的副本发送给每个任务,有的时候,变量需要在任务之间共享,或者task 与driver 之间共享,spark 支持两种类型的共享变量:广播变量和累加器,前者可以被用于所有节点(缓存在对应节点的内存中),后者仅添加到其中的变量,如计数器的总和
此篇只使用 scala 语言,其它语言请参考spark官网,如果对于如何使用 scalal 编程,请移步 使用spark开发第一个程序WordCount程序及多方式运行代码
弹性分布式数据集(RDDS)
spark 围绕着弹性分布式数据集(RDD) 的概念展开,RDD 是一个可以并行操作的容错元素集合。两种方法创建 RDD :并行化程序中现有集合,或引用外部存储系统中的数据集,如共享文件系统,HDFS, HBASE
并行集合
并行化集合是通过程序(scala-seq)中的现有集合,调用 SparkContext’s 并行化方法来创建的。集合的元素被复制形成可以并行操作的分布式数据集。例如,以下如何创建一个包含数字1到5的并行集合
注意: 是在 spark-shell 下进行代码验证,详细请参考 使用spark开发第一个程序WordCount程序及多方式运行代码
val data = Array(1, 2, 3, 4, 5)
val distData = sc.parallelize(data)
代码执行如下
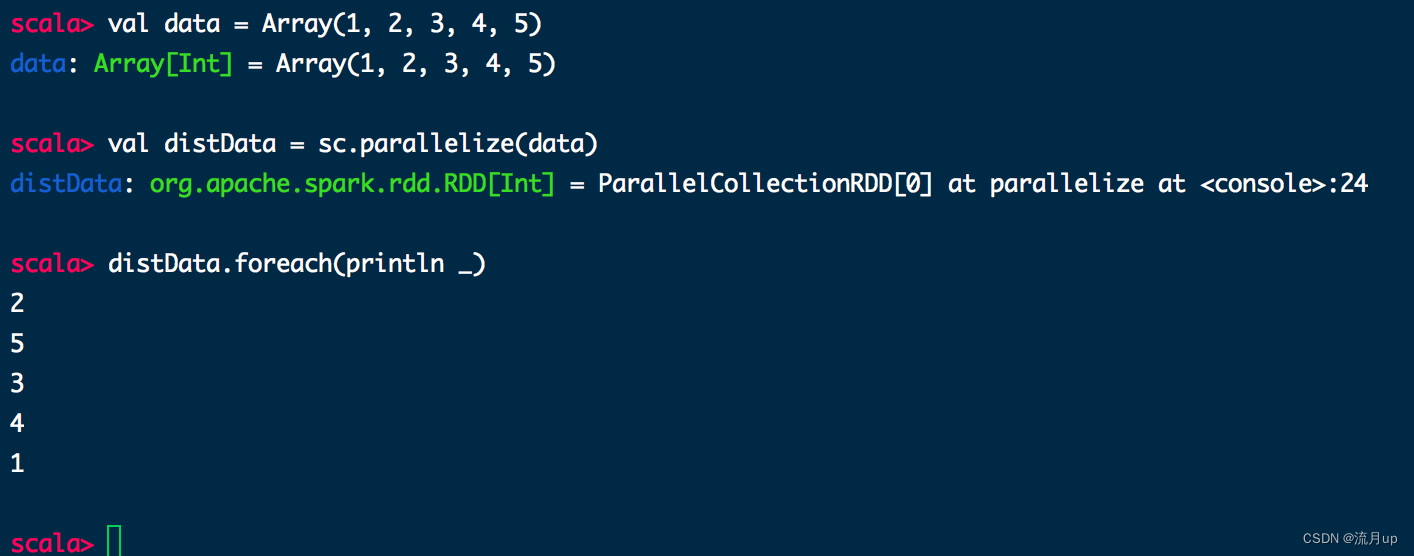
一旦创建,分布式数据集(distData)就可以并行操作。例如,可以调用distData.reduce((a,b)=>a+b)来将数组的元素相加。稍后将描述分布式数据集上的操作。
还有一个重要的参数,就是可以设置并行度,通常,spark会尝试根据集群自动设置分区数量,也可以手动设置,例如: sc.parallelize(data,10)
外部数据集
Spark可以从Hadoop支持的任何存储源创建分布式数据集,包括您的本地文件系统、HDFS、Cassandra、HBase、Amazon S3等
详细请移步 spark开发第一个程序WordCount程序
RDD操作
RDD 支持两种类型的操作:
- transformations(转换),从现有数据集创建新的数据集;例如:
map是一种转换,它将每个数据集元素传递给一个函数,并返回新的RDD - actions 在数据集上运行计算后,向
driver返回值,reduce是一种使用某种函数聚合RDD的所有元素并将结果返回给driver的操作(尽管也有一个并行的reduceByKey返回分布式数据集)
spark 中所有的 transformations 都是惰性的,因为它们不会立即计算结果,相反的,它们只是记录 transformations 的数据集,只有 actions 才会触发 transformations ,这种设计使 spark 能够更高效的运行。
默认情况下,每次对 RDD 的 transformations 操作,都可能需要重新计算它,可以采取在内存中持久化 RDD,这样,方便下次直接使用,还支持将 RDD 保持在磁盘上,或跨多个节点复制。
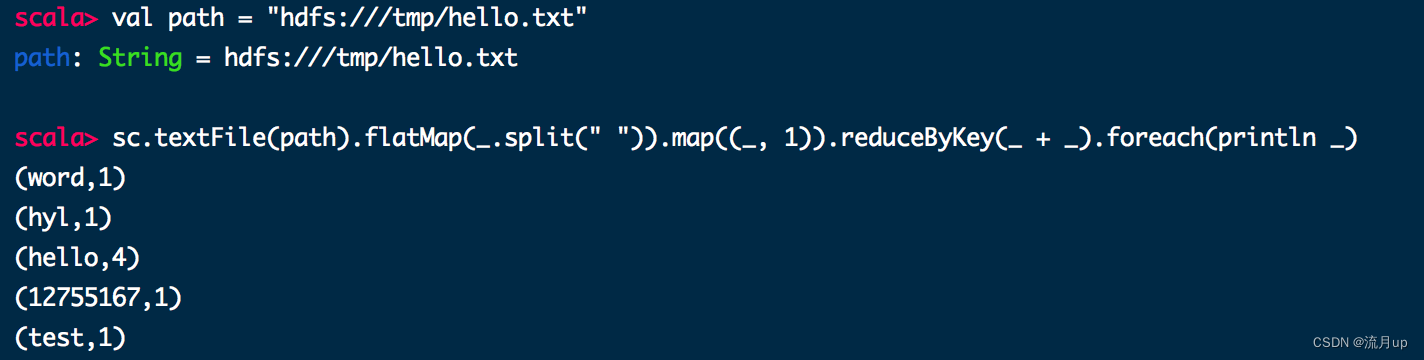
val path = "hdfs:///tmp/hello.txt"
sc.textFile(path).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).foreach(println _)
spark的函数式编程
Spark’s API 很大程度上依赖于函数式编程,推荐以下两种方法:
- 匿名函数,简洁,行云流水
- 静态方法
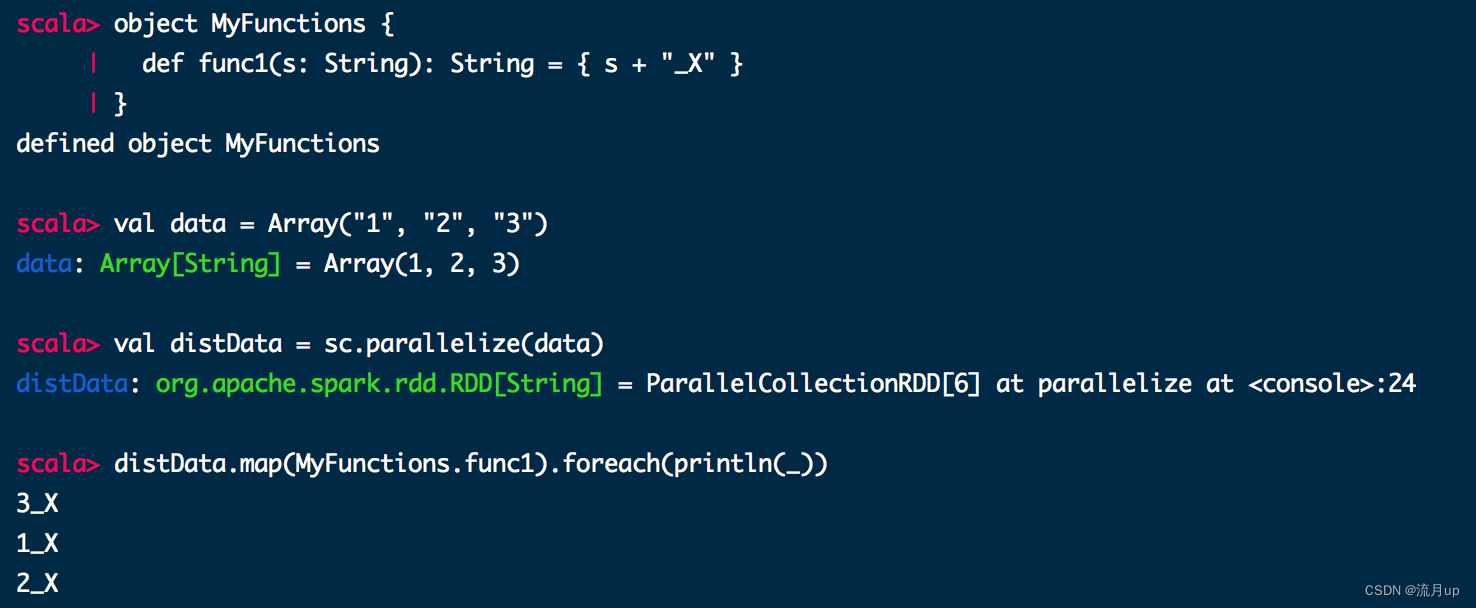
object MyFunctions {
def func1(s: String): String = { s + "_X" }
}
val data = Array("1", "2", "3")
val distData = sc.parallelize(data)
distData.map(MyFunctions.func1).foreach(println(_))
了解闭包
有一个难点是善于spark 是要理解变量作用域和生命周期,当在集群上执行方法时,这个和 js 的闭包,是不同的,因为方法执行是在多个节点上执行的,不在一个 jvm 里,可以使用 Accumulator 解决,会在后结的共享变量中进行详细说明。
Shuffle 操作
Spark中的某些操作会触发一个称为shuffle的事件。shuffle是Spark的一种机制,用于重新分发数据,以便在分区之间以不同的方式进行分组。这通常涉及到在执行器和机器之间复制数据,使洗牌成为一项复杂而昂贵的操作。
WordCount(单词统计) ,其实有一步就包含了 Shuffle 操作,要统计某个单词出现的次,那就要聚合这个单词 key ,key 可能在不同的机器上。
可能导致混洗的操作包括重分区操作(如重分区和合并)、“ByKey操作”(如groupByKey和reduceByKey)以及联接操作(如cogroup和join)。
结束
RDD 编程指南,至此结束,如有问题,欢迎评论区留言。


















 278
278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











