






python爬虫基础
一.文件
1.文件的打开与关闭
打开文件/创建文件
在python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件
open(文件路径,访问模式)
示例如下
#创建一个test.txt文件
# open(文件的路径/文件的名字,模式)
# 模式:w 可写
# r 可读
open('test.txt','w')
#打开文件:用一个变量接收创建的文件
fp=open('text.txt','w')
fp.write('hello world')# 将这句话写在text文件中
如图,我们手动创建一个demo文件夹
#文件夹是不可以创建的 暂时需要手动创建 手动创建一个demo文件
fp=open('demo/text.txt','w')
fp.write('hello world')
在该代码执行后,我们可以发现在demo文件夹中出现了text.txt文件,并且text.txt文件中还出现了write的‘hello world’
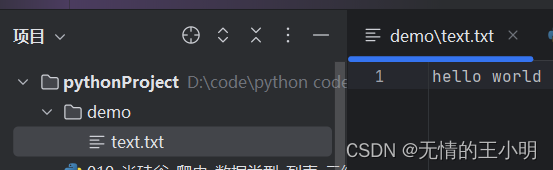
文件路径
- 绝对路径:指的是绝对位置,完整地描述了目标的所在地,所有目录层级关系是一目了然的。
-
- 例如:
E:\python,从电脑的盘符开始,表示的就是一个绝对路径。
- 例如:
- 相对路径:是从当前文件所在的文件夹开始的路径。
-
test.txt,是在当前文件夹查找test.txt文件
-
./test.txt,也是在当前文件夹里查找test.txt文件, ./ 表示的是当前文件夹。
-
../test.txt,从当前文件夹的上一级文件夹里查找test.txt文件。 …/ 表示的是上一级文件夹
-
demo/test.txt,在当前文件夹里查找demo这个文件夹,并在这个文件夹里查找test.txt文件。
访问模式
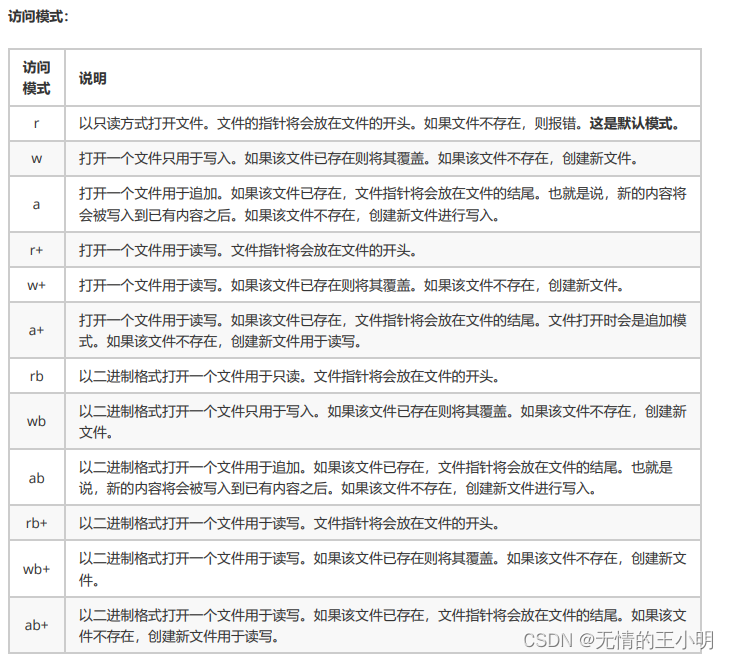
文件的关闭
#文件的关闭:看着可能没有什么区别,但是内存的占用减少了
fp.close()
2.文件的读写
- 写数据(write)
使用write()可以完成向文件写入数据
f=open('test.txt','w')
f.write('hello world,i am here\n' )
f.close()
如果文件在创建之前已经存在 会先清空原来文件的数据 然后再写
如果我想在原来的文件中追加数据,该怎么做呢?
我们可以将读写模式改为a 那么就会执行追加的操作
f=open('test.txt','a')#将读写模式改为a模式
f.write('hello world,i am here\n' )
f.close()
read
- 读数据(read)
默认情况下 read是一字节一字节的读 效率比较低
使用read(num)可以从文件中读取数据,num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据
test.txt文件的内容如下
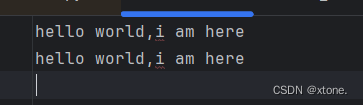
f=open('test.txt','r')
content=f.read(5) # 最多读取5个数据
print(content)
print('-'*30)
content=f.read() # 从上次读取的位置继续读取剩下的所有的数据
print(content)
f.close()
输出为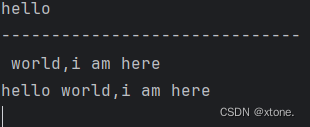
readline
readline是一行一行的读取 但是只能读取一行
f=open('test.txt','r')
content = f.readline()
print(content)
输出为
hello world,i am here
readlines
readlines可以按照行来读取 但是会将所有的数据都读取到 并且以一个列表的形式返回
而列表的元素 是一行一行的数据
f=open('test.txt','r')
content = f.readlines()
print(content)
输出为
['hello world,i am here\n', 'hello world,i am here\n']
3.序列化与反序列化
通过文件操作,我们可以将字符串写入到一个本地文件。但是,如果是一个对象(例如列表、字典、元组等),就无
法直接写入到一个文件里,需要对这个对象进行序列化,然后才能写入到文件里。
设计一套协议,按照某种规则,把内存中的数据转换为字节序列,保存到文件,这就是序列化,反之,从文件的字
节序列恢复到内存中,就是反序列化。
对象—》字节序列 === 序列化
字节序列–》对象 ===反序列化
Python中提供了JSON这个模块用来实现数据的序列化和反序列化。
JSON模块
JSON(JavaScriptObjectNotation, JS对象简谱)是一种轻量级的数据交换标准。JSON的本质是字符串。
使用JSON实现序列化
JSON提供了dump和dumps方法,将一个对象进行序列化。
dumps方法的作用是把对象转换成为字符串,它本身不具备将数据写入到文件的功能。
import json
file = open('names.txt', 'w')
names = ['zhangsan', 'lisi', 'wangwu', 'jerry', 'henry', 'merry', 'chris']
# file.write(names) 出错,不能直接将列表写入到文件里
# 可以调用 json的dumps方法,传入一个对象参数
result = json.dumps(names)
# dumps 方法得到的结果是一个字符串
print(type(result)) # <class 'str'>
# 可以将字符串写入到文件里
file.write(result)
file.close()
dump方法可以在将对象转换成为字符串的同时,指定一个文件对象,把转换后的字符串写入到这个文件里。
import json
file=open('name.txt','w')
names=['zhangsan','lisi','wangwu']
# file.write(names) #出错,不能直接将列表写入到文件里
# 可以调用 json的dumps方法,传入一个对象参数
result = json.dumps(names)
print(type(result))
# 可以将字符串写入到文件里
file.write(result)
file.close()
import json
file = open('names.txt', 'w')
names = ['zhangsan', 'lisi', 'wangwu', 'jerry', 'henry', 'merry', 'chris']
# dump方法可以接收一个文件参数,在将对象转换成为字符串的同时写入到文件里
json.dump(names, file)
file.close()
使用JSON实现反序列化
使用loads和load方法,可以将一个JSON字符串反序列化成为一个Python对象。
loads方法需要一个字符串参数,用来将一个字符串加载成为Python对象。
import json
# 调用loads方法,传入一个字符串,可以将这个字符串加载成为Python对象
result = json.loads('["zhangsan", "lisi", "wangwu", "jerry", "henry", "merry", "chris"]')
print(type(result)) # <class 'list'>
load方法可以传入一个文件对象,用来将一个文件对象里的数据加载成为Python对象。
import json
# 以可读方式打开一个文件
file = open('names.txt', 'r')
# 调用load方法,将文件里的内容加载成为一个Python对象
result = json.load(file)
print(result)
file.close()
4.异常
程序在运行过程中,由于我们的编码不规范,或者其他原因一些客观原因,导致我们的程序无法继续运行,此时,程序就会出现异常。如果我们不对异常进行处理,程序可能会由于异常直接中断掉。为了保证程序的健壮性,我们在程序设计里提出了异常处理这个概念。
读取文件异常
在读取一个文件时,如果这个文件不存在,则会报出 FileNotFoundError错误。
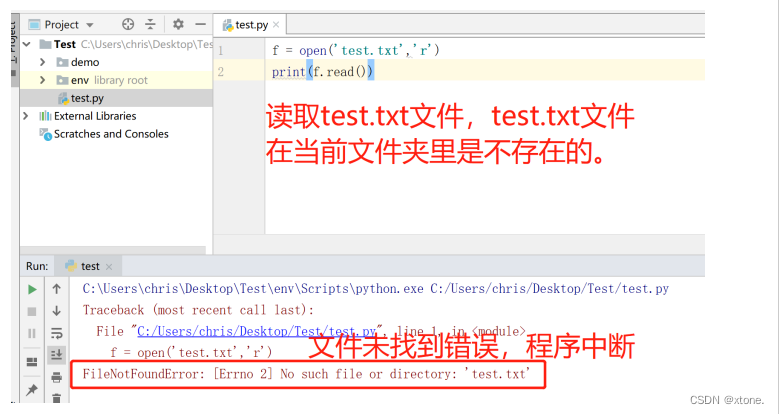
try…except语句
try…except语句可以对代码运行过程中可能出现的异常进行处理。 语法结构:
try:
可能会出现异常的代码块
except 异常的类型:
出现异常以后的处理语句
try:
f = open('test.txt', 'r')
print(f.read())
except FileNotFoundError:
print('文件没有找到,请检查文件名称是否正确')















 2308
2308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









