






自适应学习率
梯度不小损失却不再更新的原因:不合适的学习率导致参数在误差表面“震荡”
调整目标:给每一个参数不同的学习率,使得如果在某一个方向上,梯度的值很小,非常平坦,我们会希望学习率调大一点;如果在某一个方向上非常陡峭,坡度很大,我们会希望学习率可以设得小一点。
AdaGrad
θ t + 1 i ← θ t i − η σ t i g t i \theta^i_{t+1} \leftarrow \theta^i_t - \dfrac{\eta}{\sigma^i_t} g^i_t θt+1i←θti−σtiηgti
σ t i = 1 t + 1 Σ i = 0 t ( g t i ) 2 \sigma^i_t = \sqrt[]{\dfrac{1}{t+1}\Sigma^t_{i=0}(g^i_t)^2} σti=t+11Σi=0t(gti)2
RMSProp
θ t + 1 i ← θ t i − η σ t i g t i \theta^i_{t+1} \leftarrow \theta^i_t - \dfrac{\eta}{\sigma^i_t} g^i_t θt+1i←θti−σtiηgti
σ t i = α ( σ t − 1 i ) 2 + ( 1 − α ) ( g t i ) 2 , 0 < α < 1 \sigma^i_t = \sqrt[]{\alpha (\sigma^i_{t-1})^2 + (1-\alpha)(g^i_t)^2},0 < \alpha < 1 σti=α(σt−1i)2+(1−α)(gti)2,0<α<1
σ 0 i = ( g 0 i ) 2 = ∣ g 0 i ∣ \sigma^i_0 = \sqrt[]{(g^i_0)^2} = \left| g^i_0 \right| σ0i=(g0i)2= g0i
Adam
θ t + 1 i ← θ t i − η σ t i m t i \theta^i_{t+1} \leftarrow \theta^i_t - \dfrac{\eta}{\sigma^i_t} m^i_t θt+1i←θti−σtiηmti
m决定参数更新的方向, σ \sigma σ影响步伐的大小
学习率调度
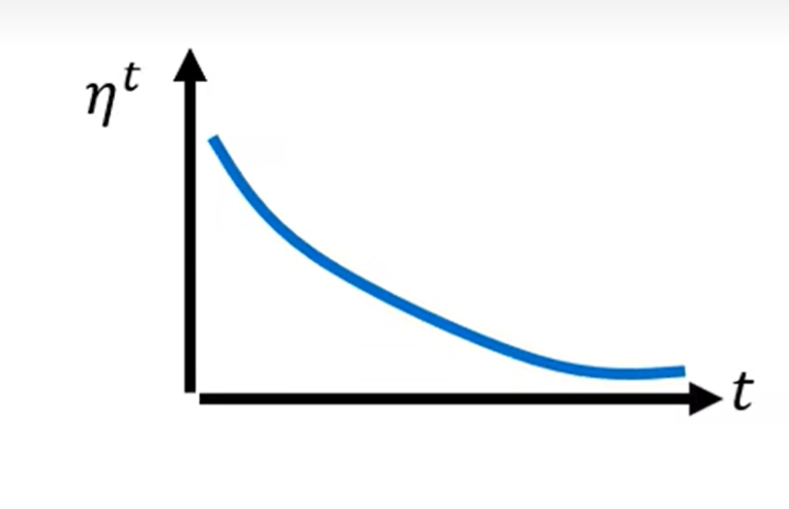
- 学习率衰减
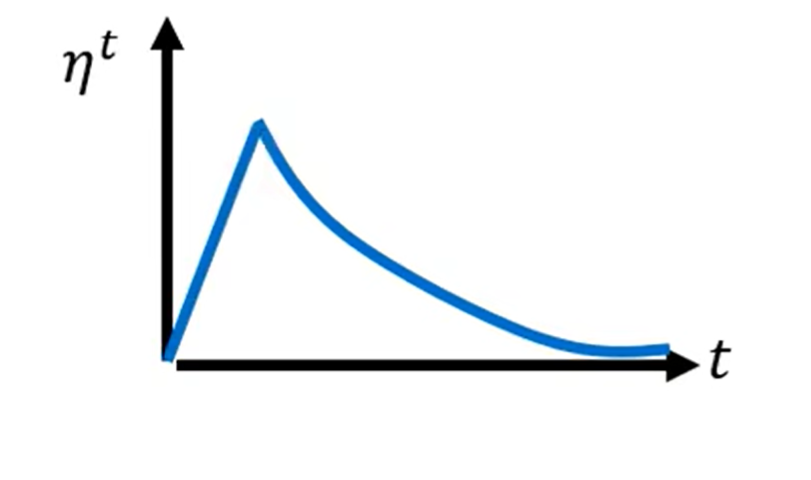
- 预热
超参数:变化的范围、变大的速度、变小的速度
在残差网络里面,学习率先设置成 0.01,再设置成 0.1,并且其论文还特别说明,一开始用 0.1 反而训练不好。除了残差网络,BERT 和 Transformer 的训练也都使用了预热。
预热的原因;
当我们使用 Adam、RMSprop 或 AdaGrad 时,需要计算 σ。而 σ 是一个统计的结果。从 σ 可知某一个方向的陡峭程度。统计的结果需要足够多的数据才精准,一开始统计结果 σ 是不精准的。一开始学习率比较小是用来探索收集一些有关误差表面的情报,先收集有关 σ 的统计数据,等 σ 统计得比较精准以后,再让学习率慢慢爬升。Adam的进阶版:RAdam
分类
使用独热向量而不是数字来表示类的原因:
数字间的间隔大小会给本来独立的类引入远近关系
如果有三个类,标签 y 就是一个三维的向量,比如类 1 是 [1, 0, 0]T,类 2 是 [0, 1, 0]T,类3 是 [0, 0, 1]T。如果每个类都用一个独热向量来表示,就没有类 1 跟类 2 比较接近,类 1 跟类 3 比较远的问题。如果用独热向量计算距离的话,类两两之间的距离都是一样的。
softmax函数
y 是独热向量,所以其里面的值只有 0 跟 1,但是 yˆ 里面有任何值。既然目标只有 0 跟 1,但 yˆ 有任何值,可以使用softmax函数把它归一化到 0 到 1 之间,再计算跟标签的相似度。
y i ′ = exp ( y i − y m a x ) Σ e x p ( y i − y m a x ) y'_i = \dfrac{\exp(y_i - y_{max})}{\Sigma exp(y_i - y_{max})} yi′=Σexp(yi−ymax)exp(yi−ymax)
交叉熵
e = − Σ i y i l n y i ′ e = -\Sigma_i y_ilny_i' e=−Σiyilnyi′
当 y 与 y ′ y与y' y与y′相同时,可以最小化交叉熵的值,此时均方误差也是最小的。最小化交叉熵其实就是最大化似然
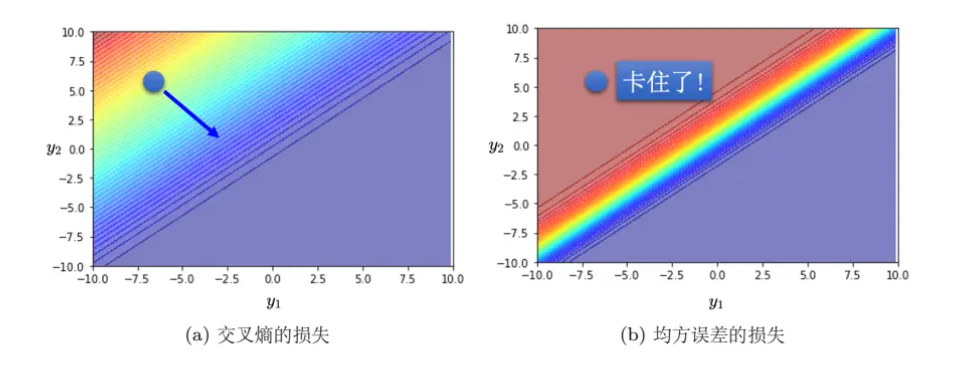
比起均方误差的优点:
做分类时较容易让损失达到最低点















 550
550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









