






深度学习基础:自适应学习率(Adaptive Learning rate)
1. learning rate impact in trainning

Training is stuck because of PING-PONG around critical point due to learning rate is too big.

Traing is hard to reach critical point due to learning rate is too small which leads to parameter update is slow as gradient is small in flat error surface.
Conclusion: learning rate should be adjusted according to gradient situation during training.
2. Adaptive learning rate Method
different paramter have different gradient change situation:
a) gradient change rapid -> small learning rate;
b) gradient change slow -> big learning rate;
1) Adagrad(假设同个参数变化是固定的, 要么快, 要么慢)


Adagrad 对学习率的调整 是基于 之前训练的所有梯度, 每个梯度对学习率调整的影响都一样;
2) RMSProp(假设同个参数变化不是固定的, 有时快, 有时慢)


RMSProp 对学习率的调整 是基于 之前训练的所有梯度, 但每个梯度对学习率调整的影响是可配置的; 为了能快速适应梯度变化, 应该把最近的梯度影响增大.
3) Adam(RMSProp + Momentum, Torch里面使用默认值就可以了)

4) Learning Rate Scheduling(learning rate adjusts on training duration)

在梯度很小变化的方向上, 平方根越来越小, 导致更新突然爆炸, 跑到梯度变化大的地方, 然后又慢慢恢复到正轨上;
考虑到随着训练时间变长, 梯度总会慢慢变小, 因此可以调整learning rate 随着时间而变小;
warm-up: learning rate 随着时间先变大再变小;
5) Summary(动量 m考虑了方向, 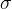 考虑了大小,
考虑了大小, 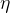 考虑了时间)
考虑了时间)

深度学习基础:分类(Classification)

Q: 当把模型输出的标量scaler(1, 2, 3) 当作类别处理可以吗?
A: 1, 2, 3 数字潜在也表达了他们之间的关系, 1和2 比较接近, 1和3 相差大, 这不能表达类别之间独立的关系;
One-hot Vector + softmax 来表达类别



类别之间的距离表达(Loss)

Minimizing Cross-Entropy is equivalent to maximizing likelihood(最大似然)
Torch 使用 cross-entropy 的时候会自动在输出层加上 softmax;

上图说明不同的 Loss 函数会影响训练的难易度; 左图会一开始就stuck因为梯度很平坦, 右图有很明显的梯度,训练起来更稳定快速.
Loss 函数的选择 也是一种改变 error surface 的方法.















 1049
1049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









