







PyTorch学习笔记
1 PyTorch简介与安装

PyTorch是一个基于 Numpy 的科学计算包,向它的使用者提供了两大功能:
- 作为 Numpy 的替代者,向用户提供使用 GPU 强大功能的能力;
- 做为一款深度学习的平台, 向用户提供最大的灵活性和速度。
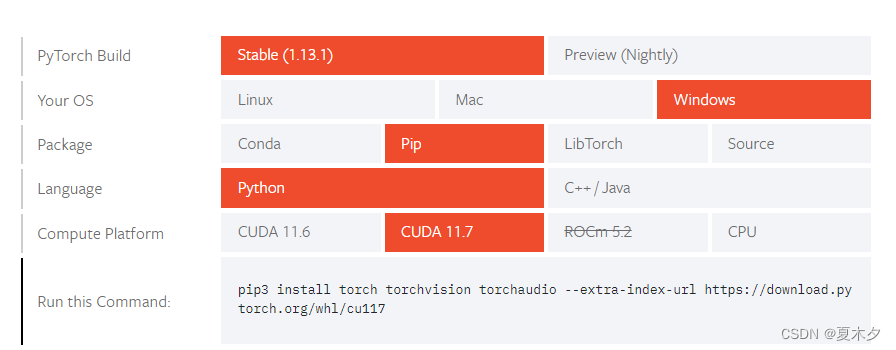
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117
具体可根据个人设备的配置来选择,生成自己的安装命令
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1686
1686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









